Float Compression 5: Science!
Introduction and index of this series is here.
Previous post was about mis-using meshoptimizer compression for compressing totally non-mesh data, for pretty good results. This time, let’s look at several libraries specifically targeted at compressing floating point data sets. Most of them are coming from the scientific community – after all, they do have lots of simulation data, which is very often floating point numbers, and some of that data is massive and needs some compression.
Let’s go!
Reminder: so far I’m only looking at lossless compression. Lossy compression investigation might be a future post.
zfp
zfp (website, github) is a library for either lossy or lossless compression of 1D-4D data (floats and integers, 32 and 64 bit sizes of either). I’ve seen it before in EXR post.
It is similar to GPU texture compression schemes – 2D data is divided into 4x4 blocks, and each block is encoded completely independently from the others. Inside the block, various magic stuff happens and then, ehh, some bits get out in the end :) The actual algorithm is well explained here.
Sounds cool! Let’s try it (again, I’m using the lossless mode of it right now). zfp is the red 4-sided star point:
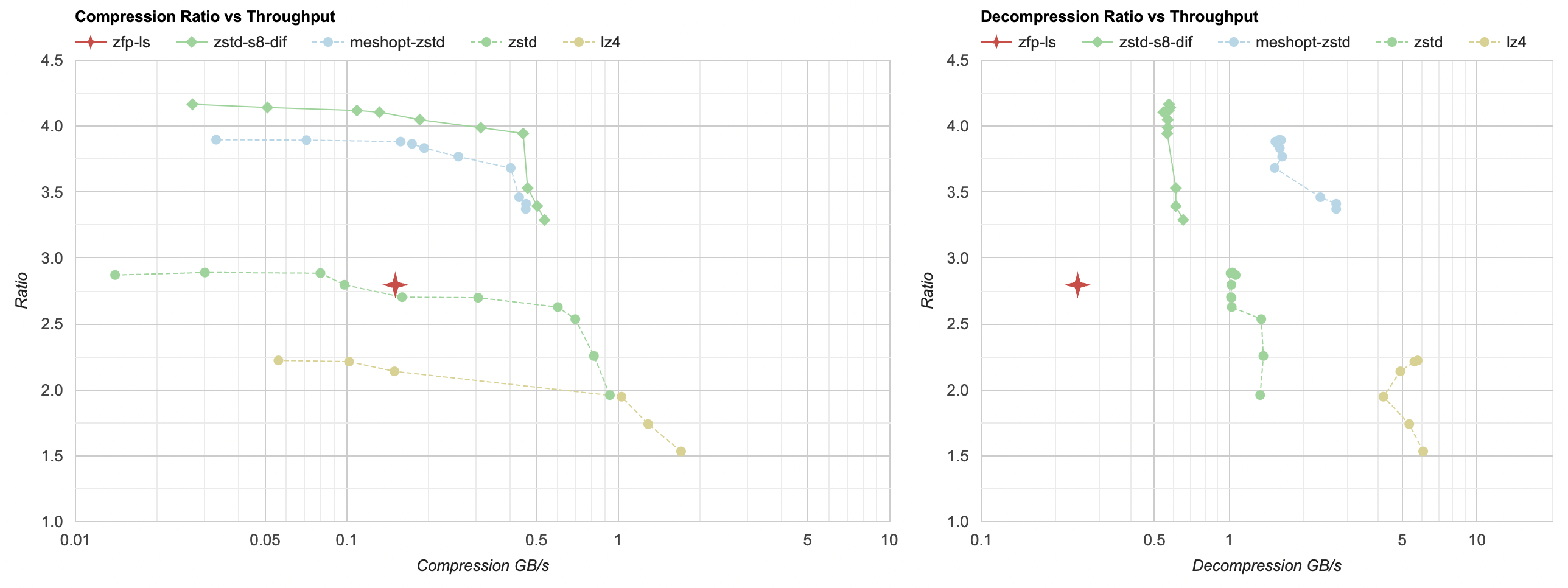
Ouch. I hope I “used it wrong” in some way? But this is not looking great. Ratio is under 1, i.e. it makes the data larger, and
is slow to decompress. (Edit: initially I made a mistake and misunderstood what zfp_compress returns – it returns the
cumulative number of compressed bytes; not new compressed bytes done during the compress call. And the second mistake I
made was when compressing 1D data - you need to tell it that Y dimension is zero, not one!)
In lossless mode, zfp is not looking super great – ratio is not stellar, and decompression speed in particular is quite slow. The compression ratio is similar to zstd without any data filtering. To be fair, zfp compresses the two 2D files from my data set much better than the two other (1D) files. My takeaway is that zfp might be mostly targeted at lossy compression, which is a topic for some other day. Let’s move on.
fpzip
fpzip (website, github) is from the same research group as zfp,
and is their previous floating point compressor. It can also be both lossless and lossy, but from the description seems to
be more targeted at lossless case. Let’s try it out (fpzip is the 5-sided star):
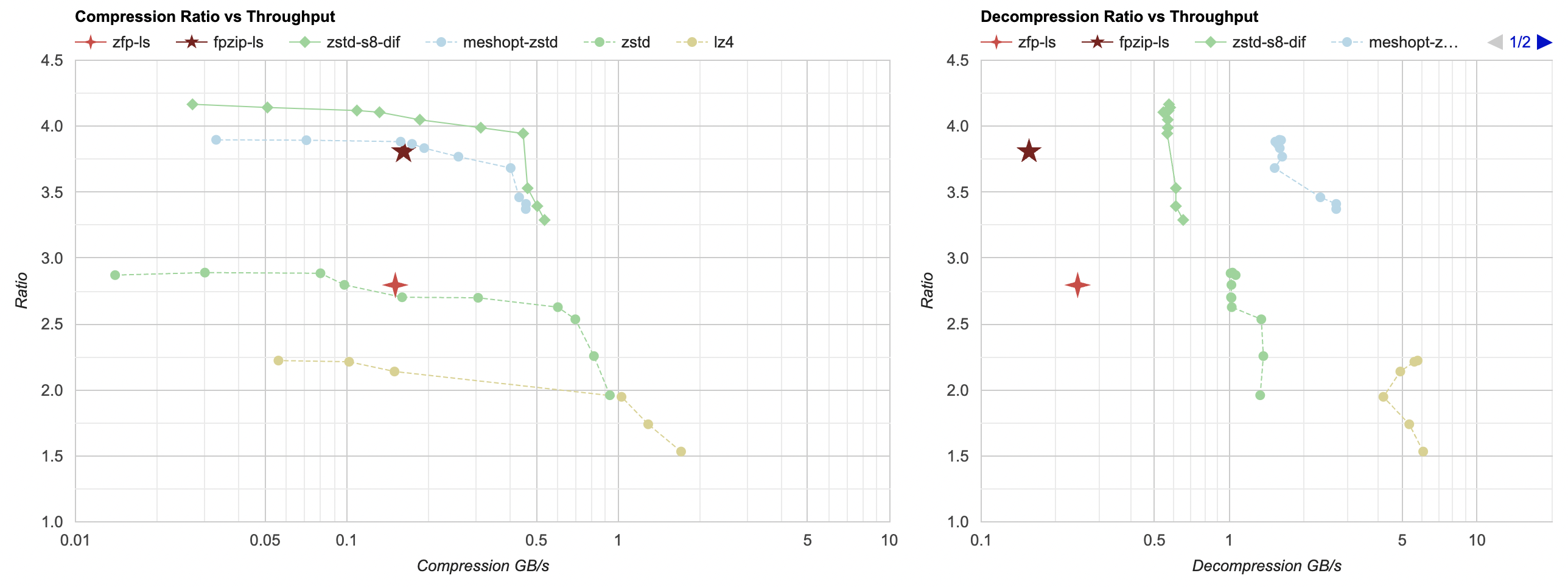
Ok, this is better compression ratio compared to zfp. Here I’m first splitting the data by floats (see part 3 post) so that all water heights are together, all velocities are together, etc. Without doing that, fpzip does not get any good compression ratio. Code is here.
- Compression ratio and performance is really good! Our data set gets down to 24.8MB (not far from “split bytes + delta + zstd” 22.9MB or “mesh optimizer + zstd” 24.3MB). Compresses in 0.6 seconds.
- However decompression performance is disappointing; takes same time as compression at 0.6 seconds – so between 5x and 10x slower than other best approaches so far.
SPDP
SPDP (website, 2018 paper) is interesting, in that it is a “generated” algorithm. They developed a number of building blocks (reorder something, delta, LZ-like compress, etc.) and then tested millions of their possible combinations on some datasets, and picked the winner. Source code only comes either as a HDF5 filter, or as a standalone command line utility. I had to modify it slightly (code) to be usable as a library, and to not use 1MB of stack space which Windows does not appreciate :)
A series of six-sided stars here:
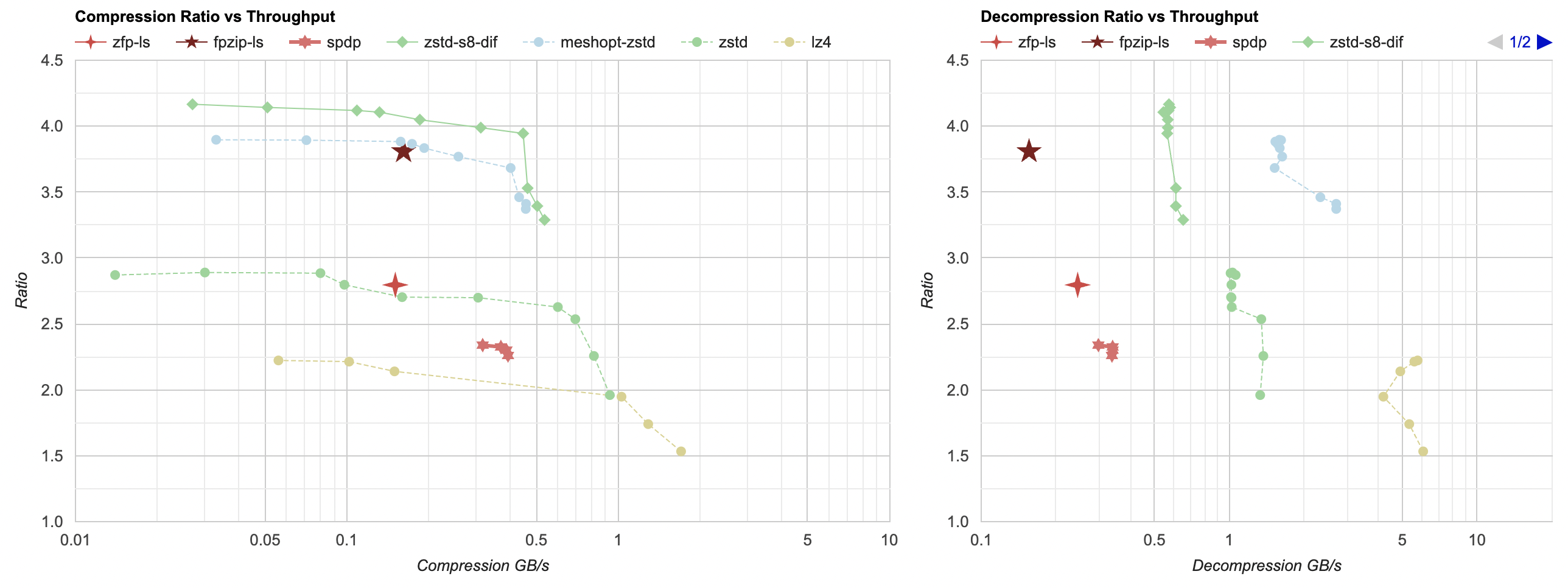
- Similar to fpzip case, I had to split the data by floats (code) to get better compression ratio.
- Compression ratio is between regular zstd and lz4, and is a far behind the best options.
- It is about twice as fast as fpzip at both compression and decompression, which is still far behind the better options.
The idea of having a bunch of building blocks and automatically picking their best sequence / combination on a bunch of data sets is interesting though. Maybe they should have had stronger building blocks though (their LZ-like codec might be not super good, I guess).
ndzip
ndzip (github, 2021 paper) promises a “efficient implementation on modern SIMD-capable multicore processors, it compresses and decompresses data at speeds close to main memory bandwidth, significantly outperforming existing schemes”, let’s see about it!
Note that I have not used or tested multi-threaded modes of any of the compressors present. Some can do it; all could do it if incoming data was split into some sort of chunks (or after splitting “by floats”, each float block compressed in parallel). But that’s not for today.
ndzip does not build on Windows out of the box (I opened a PR with some fixes), and for the multi-threaded
code path it uses OpenMP features that MSVC 2022 seems to not have. It also is specifically designed for AVX2, and and that needs a bit of juggling to
get compiled on Windows too. On Mac, it does not link due to some symbol issues related to STL (and AVX2 code path would not really work on an arm64).
On Linux, the multi-threaded OpenMP path does not produce correct results, but single-threaded path does. Huge props for releasing source code, but all of
this does sound more like a research project that is not quite yet ready for production use :)
Anyway, 7-sided yellow star here:
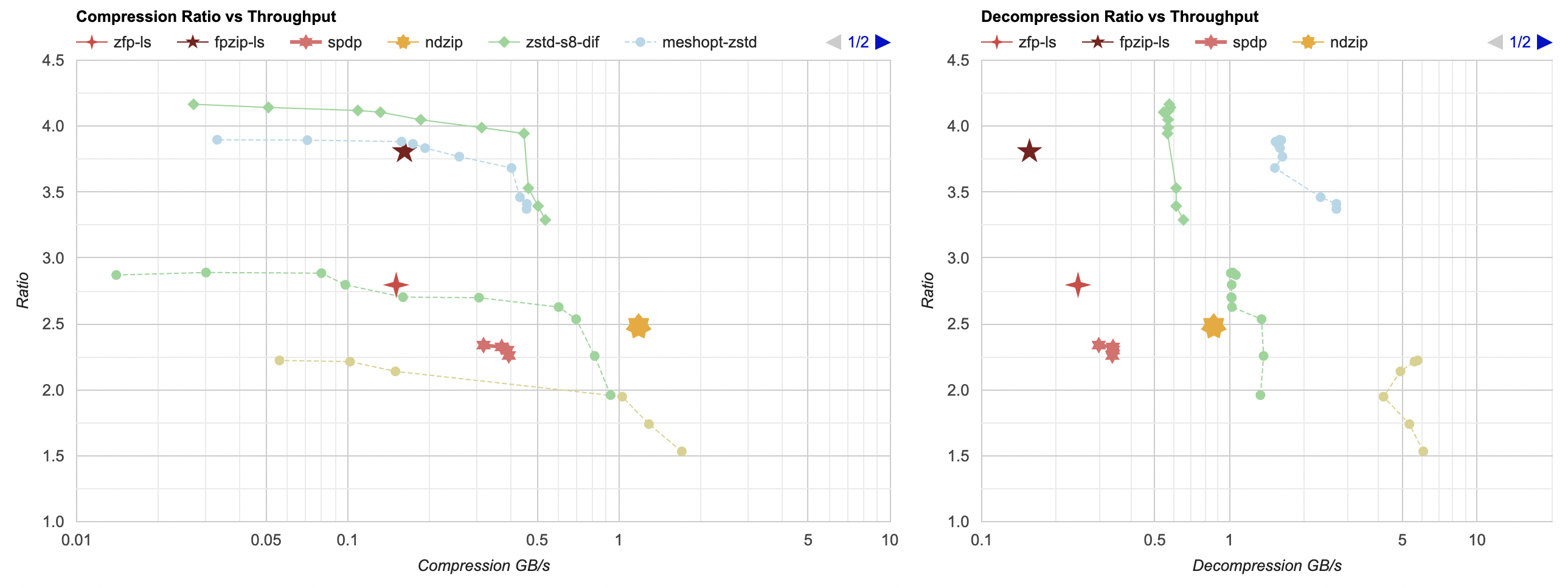
- Similar to others, I split data by floats first, or otherwise it does not achieve pretty much any compression.
- Now this one does achieve a place on the Pareto frontier for compression. The ratio is well behind the best possible (file size gets to 38.1MB; best others go down to 23MB), but it does compress at over 1GB/s. So if you need that kind of compression performance, this one’s interesting.
- They also have CUDA and SYCL code for GPUs too. I haven’t tried that.
streamvbyte
streamvbyte (github, blog post, 2017 paper) is not meant for compressing floating point data; it is targeted as compressing 4-byte integers. But hey, there’s no law saying we can’t pretend our floats are integers, right?
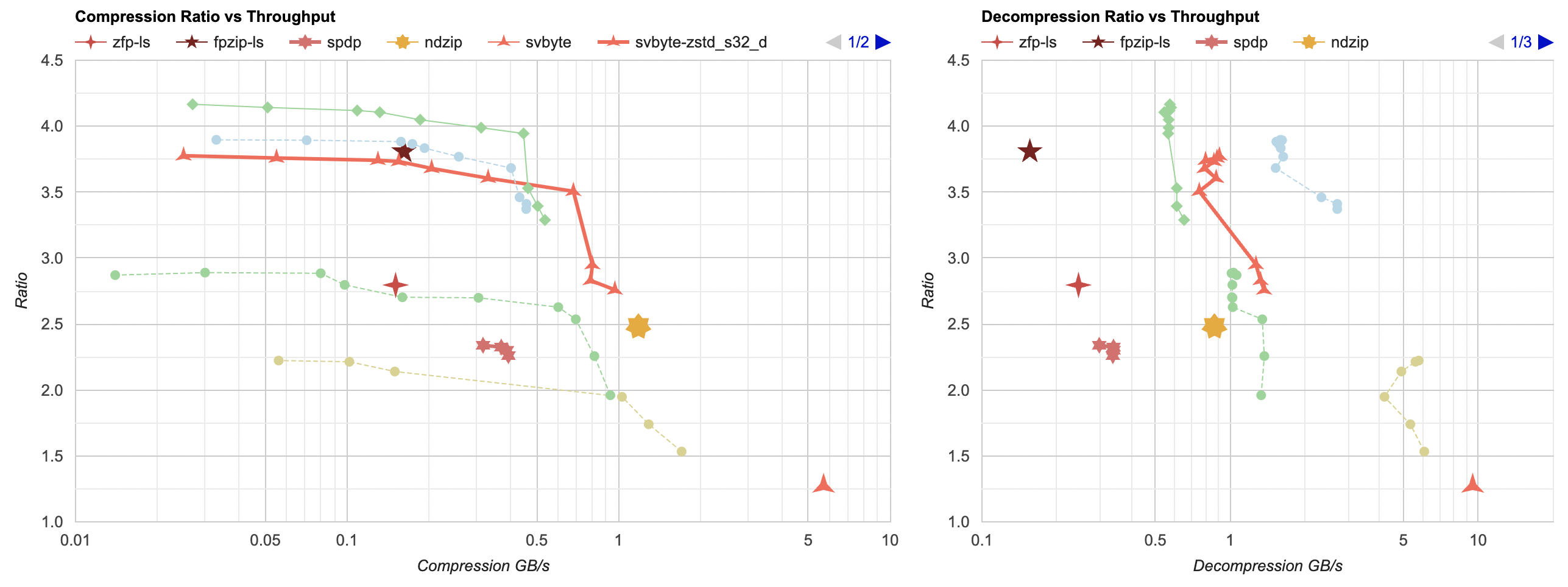
- Three-sided star is regular
streamvbyte. Only 1.2x compression ratio, but it is the fastest of the bunch; compressing at 5.7GB/s, decompressing at ~10GB/s. - There’s also
streamvbyte_delta, which on unfiltered data is not really good (not shown here). - However (similar to others), if the data is first split by floats, then
streamvbyte_deltafollowed by a general purpose compressor is quite good. Especially if you need compression faster than 0.5GB/s, then “split by floats, streamvbyte_delta, zstd” is on the Pareto frontier, reaching 3.5x ratio.
Conclusion and what’s next
On this data set, in lossless mode, most of the compression libraries I tried in this post are not very impressive. My guess is that’s a combination of several factors: 1) maybe they are primarily targeted at double precision, and single precision floats somewhat of an afterthought, 2) maybe they are much better at 3D or 4D data, and are weaker at a mix of 2D and 1D data like in my case, 3) maybe they are much better when used in lossy compression mode.
However it is curious that some of the papers describing these compressors only either compare them to other scientific compressors, or only to regular lossless compression algorithms. So they go with conclusions like “we surpass zstd a bit!” and declare that a win, without comparing to something like “filter the data, and then zstd it”.
Another interesting aspect is that most of these libraries have symmetric compression and decompression performance, which is very different from most of regular data compression libraries, where compression part is often much slower.
Next up: either look into lossy compression, or into speeding up the data filtering part. Until then!