Making Gaussian Splats more smaller
Previous post was about making Gaussian Splatting data sizes smaller (both in-memory and on-disk). This one is still about the same topic! Now we look into clustering / VQ.
Teaser: this scene (garden tools from my own shed) is just 7.5 megabytes of data now. And it represents the metal shading
(anisotropy / brushed metal parts) quite well!
Spherical Harmonics take up a lot of space!
In raw uncompressed Gaussian Splat data, majority of the data is Spherical Harmonics coefficients. If we ignore the very first SH coefficient (which we treat as “a color”), the rest is 45 floating point numbers for each splat (15 numbers for R,G,B channels each). For something like the “bike” scene with 6.1 million splats, this is 1.1GB data just for the SH coefficients alone. And while they can be converted into half-precision (FP16) floats with pretty much no quality loss at all, or into smaller quantized formats (Norm11 and Norm565 from previous post), that still leaves them at 350MB and 187MB worth of data. Even the idea that should not actually work – lay them out in a Morton order inside a texture and compress as GPU BC1 format – does not look entirely terrible, but is still about 46MB of data.
Are Spherical Harmonics even worth having? That’s a good question. Without them, the scenes still look quite good,
but the surfaces lose quite a lot of “shininess”, especially different reflectance when moving the viewpoint. Below are “bike”
and “garden” scenes, rendered with full SH data (left side) vs just color (right side):


How does “reflection” of the vase on the metal part of the table work, you might ask? The gaussians have “learned” the ages-old trick of duplicating and mirroring the geometry for reflection! Cute!
Anyway, for now let’s assume that we do want this “surface reflectivity looks nicer” effect that is provided by SH data.
Remember palettized images?
Remember how ages ago image files used to have a “color palette” of say 256 or 16 distinct colors, and each pixel would just say “yeah, that one”, pointing at the index of the color inside the palette. Heck, even whole computer displays were using palettes because “true color” was too costly at the time.
We can try doing the same thing for our SH data – given several million SH items inside a gaussian splat scene, can we actually pick “just some amount” of distinct SH values, and have each splat just point to the needed SH item?
Why, yes, we can. I’ve spent a bit of time learning about “vector quantization”, “clustering” and “k-means” and related jazz, and have played around with clustering SHs into various amounts (from 1024 up to 65536).
Note that SH data, at 45 numbers per splat, is quite “high dimensional”, and that has various challenges (see curse of dimensionality). One of them is that clustering millions of splats into thousands of items, in 45 dimensions, is not exactly fast. Another is that clustering might not produce good results. ⚠️ I don’t know anything about any of that; it could very well be that I should have done clustering entirely differently! But hey, whatever :)
Also, I’m very impatient, like if anything takes longer than 10 minutes I go “this is not supposed to be that long”. I first tried scikit-learn but that was taking ages to cluster SHs into even one thousand items. Faiss was way faster, taking about 5 minutes to cluster “bike” scene SHs into 16k items. However, I did not want to add that as a dependency, so I whipped up my own variant of mini-batch k-means using Burst’ed C# directly inside Unity. I probably did it all wrong and incorrectly, but it is about 3x faster than even Faiss and seems to provide better quality, at least for this task, so 🤷
So the process is:
- Take all the SH data from the gaussian splat scene,
- Cluster that into 4k - 16k distinct SH item “palette”. Store that. I’m storing as FP16 numbers, so that’s 360KB - 1.44MB data for the palette itself.
- For each original SH data point, find which item of the palette it is closest to. Store that inded per splat. I’m storing as 16 bits (even if some of the bits are not used), so for “bike” scene (6.1M splats) this is about 12MB indices.
Here’s full SH (left side) vs. SHs clustered into 16k items (right side):


This does retain the “shininess” effect, at expense of ~13MB data for either scene above. And while it does have some lighting artifacts, they are not terribly bad. So… probably okay?
Aside: the excellent gsplat.tech by Jakub Červený (@jakub_c5y) seems to also be using some sort of VQ/Clustering for the data. Seriously, check it out, it’s probably be nicest gaussian splatting thing right now w.r.t. usability – very intuitive camera controls, nicely presented file sizes, and works on WebGL2. Craftsmanship!
New quality levels
In my toy “gaussian splatting for Unity” implementation, currently I only do SH clustering at “Low” and “Very Low” quality levels.
Previously, “Low” preset had data sizes of 119MB, 49MB, 113MB; PSNR respectively
34.72, 31.81, 33.05):
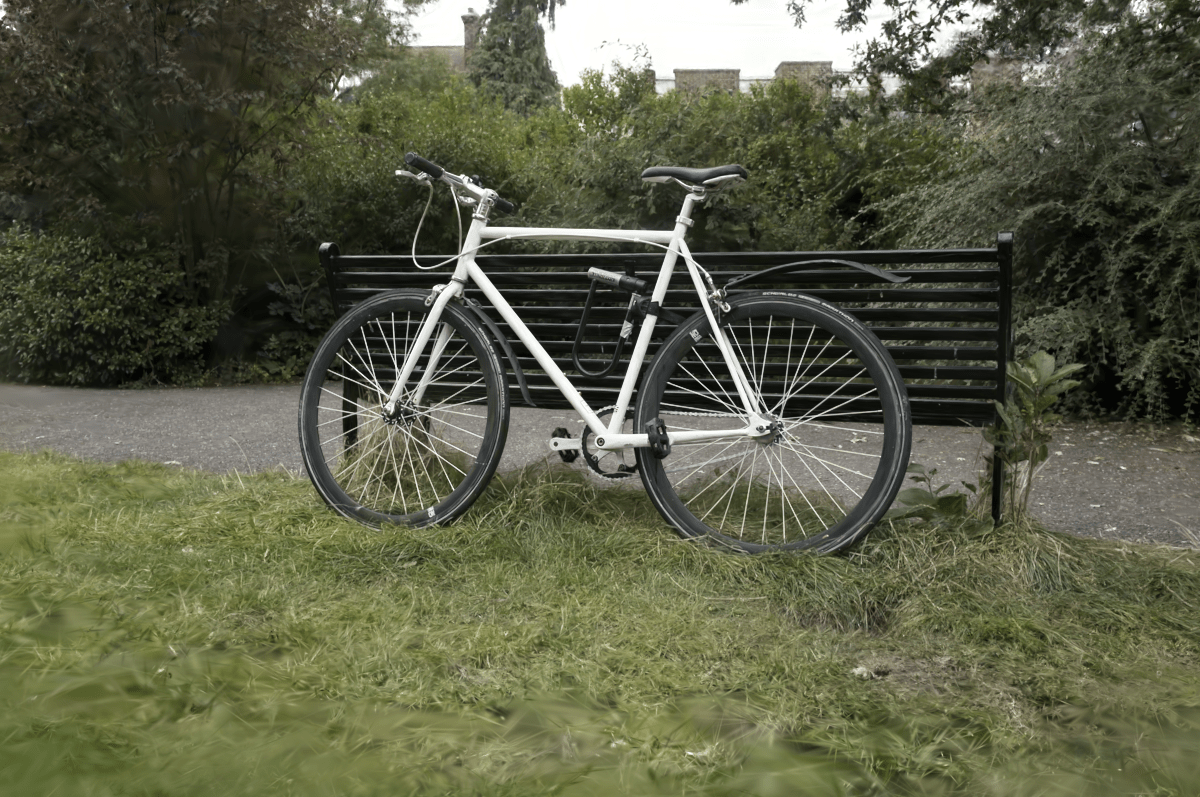


Now, the “Low” preset clusters SH into 16k items. Data sizes 98MB, 41MB, 93MB; PSNR respectively
35.17, 35.32, 35.00:
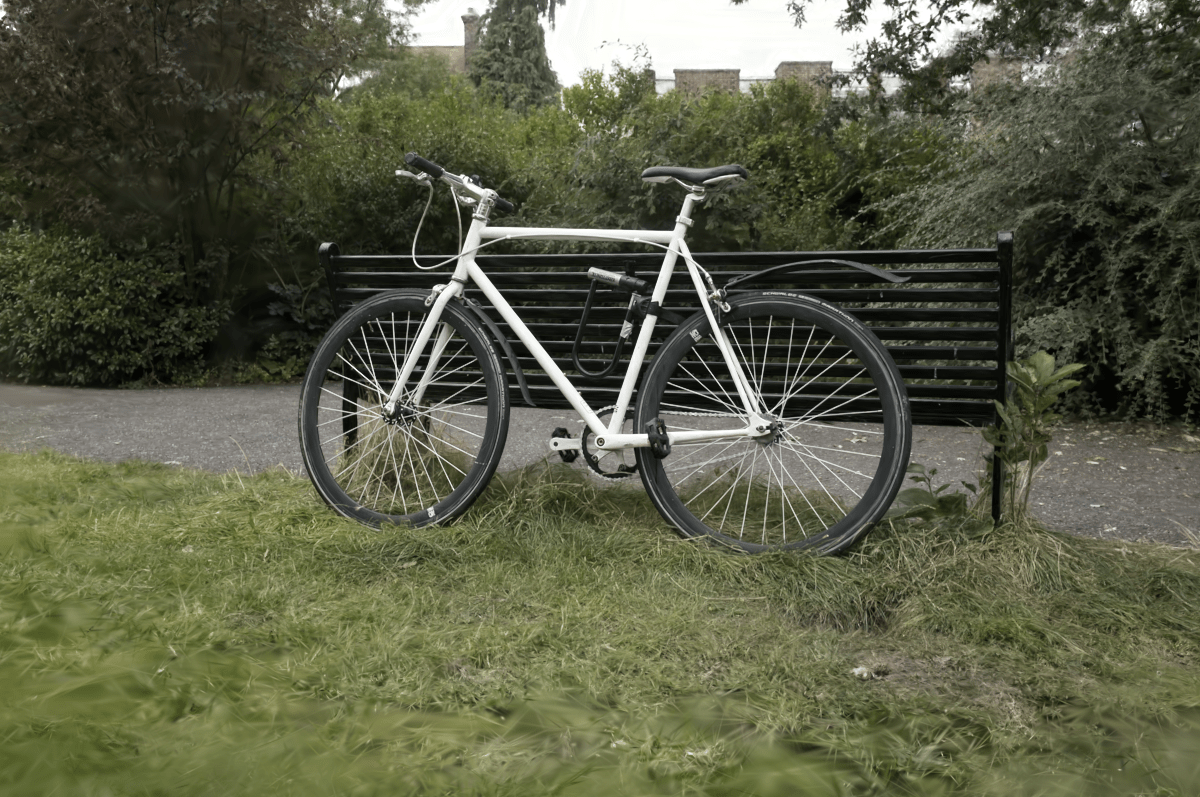


The “Very Low” preset previously was pretty much unusable (data sizes of 74MB, 32MB, 74MB; PSNR
24.02, 22.28, 23.10):
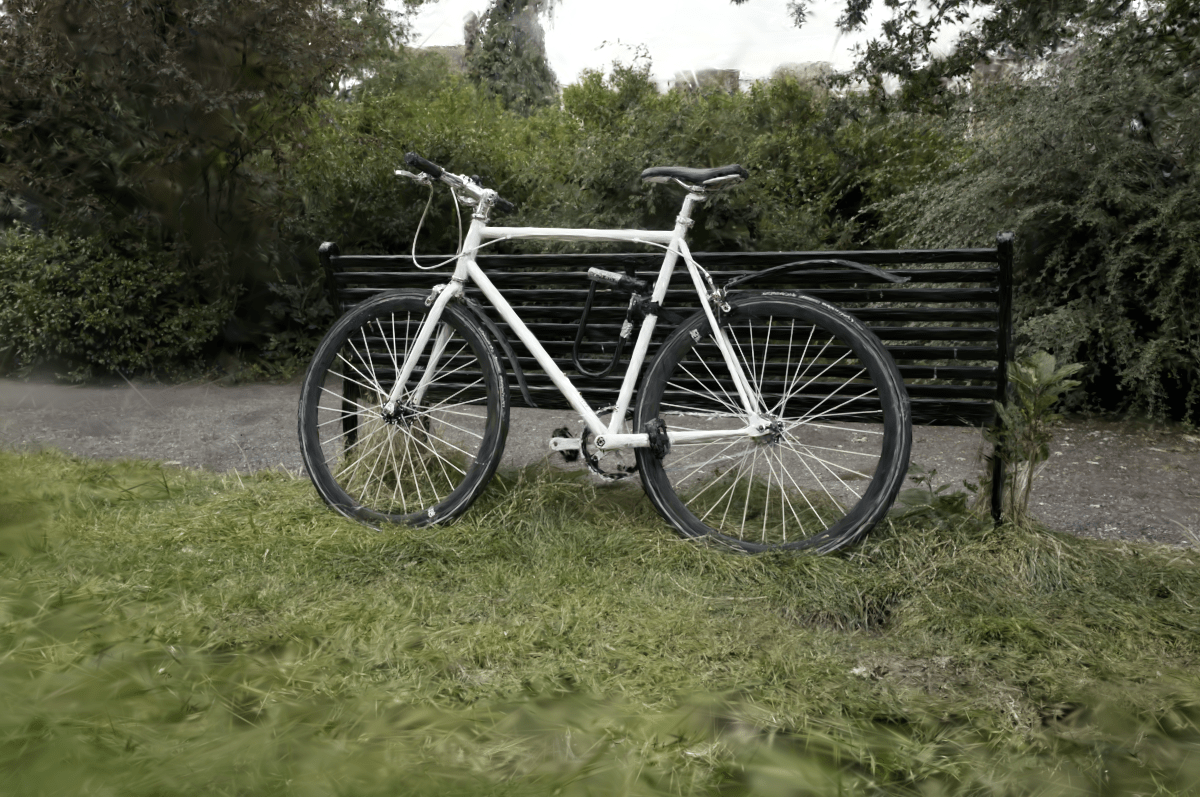


However now the Very Low preset is in “somewhat usable” territory! File sizes are similar; the savings from clustered SH I’ve spent
on other components that were suffering before. SH clustered into 4k items. Data sizes 79MB, 33MB, 75MB; PSNR
32.27, 30.19, 31.10:
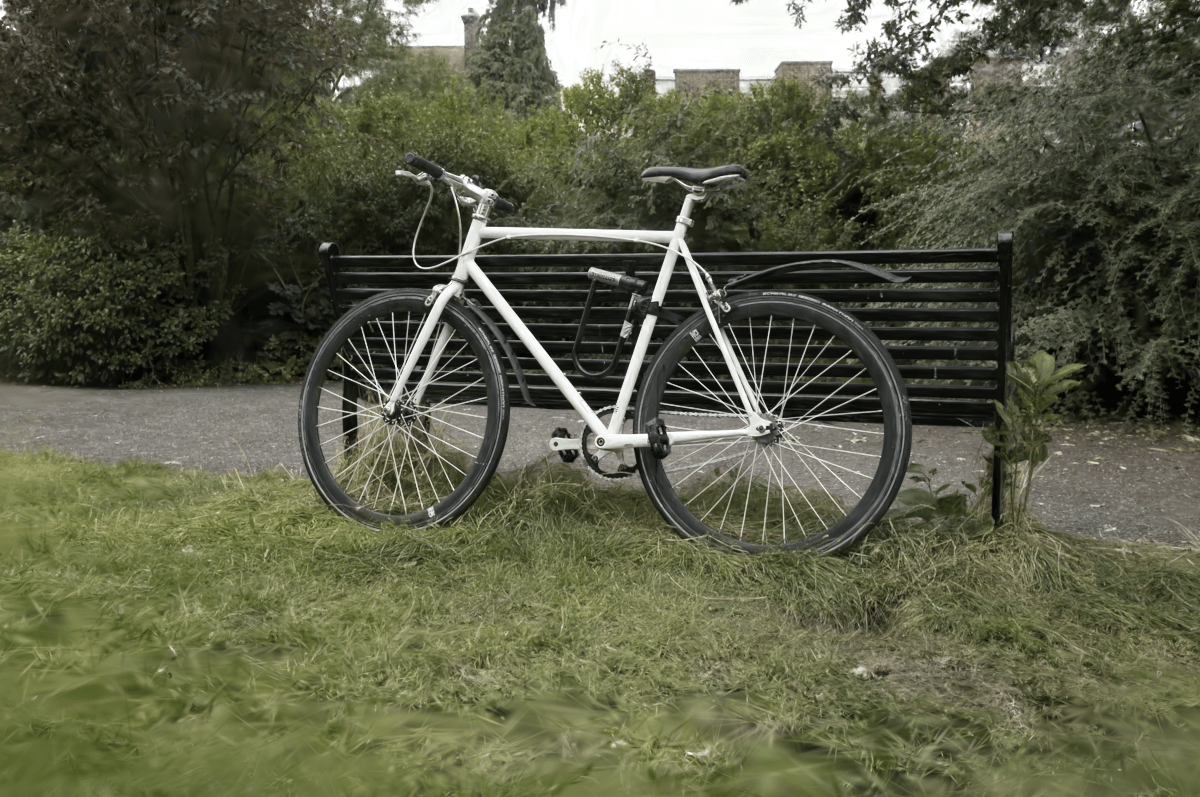


| Quality | Pos | Rot | Scl | Col | SH | Compr | PSNR |
|---|---|---|---|---|---|---|---|
| Very High | Norm16x3 | Norm10_2 | Norm16x3 | F16x4 | F16x3 | 2.1x | |
| High | Norm16x3 | Norm10_2 | Norm16x3 | F16x4 | Norm11 | 2.9x | 57.77 |
| Medium | Norm11 | Norm10_2 | Norm11 | Norm8x4 | Norm565 | 5.1x | 47.46 |
| Low | Norm11 | Norm10_2 | Norm565 | Norm8x4 | Cluster16k | 14.9x | 35.17 |
| Very Low | Norm11 | Norm10_2 | Norm565 | BC7 | Cluster4k | 18.4x | 32.27 |
Conclusions and future work
At this point, we can have “bike” and “garden” scenes in under 100MB of data (instead of original 1.4GB PLY file) at fairly acceptable quality. Not bad!
Of course gaussian splatting at this point is useful for “rotate around a scanned object” use case; it is not useful for “in games” or many other cases. We don’t know how to re-light them, or how to animate them well, etc. etc. Yet.
I haven’t done any of the “small things I could try” from the end of the previous post yet. So maybe that’s next? Or maybe look into how to further reduce the splat data on-disk, as opposed to just reducing the memory representation.
All the code for above is in this UnityGaussianSplatting#9 PR on github.