This is about an update to Blender video editing Scopes (waveform, vectorscope, etc.), and a detour into rendering many points on a GPU.
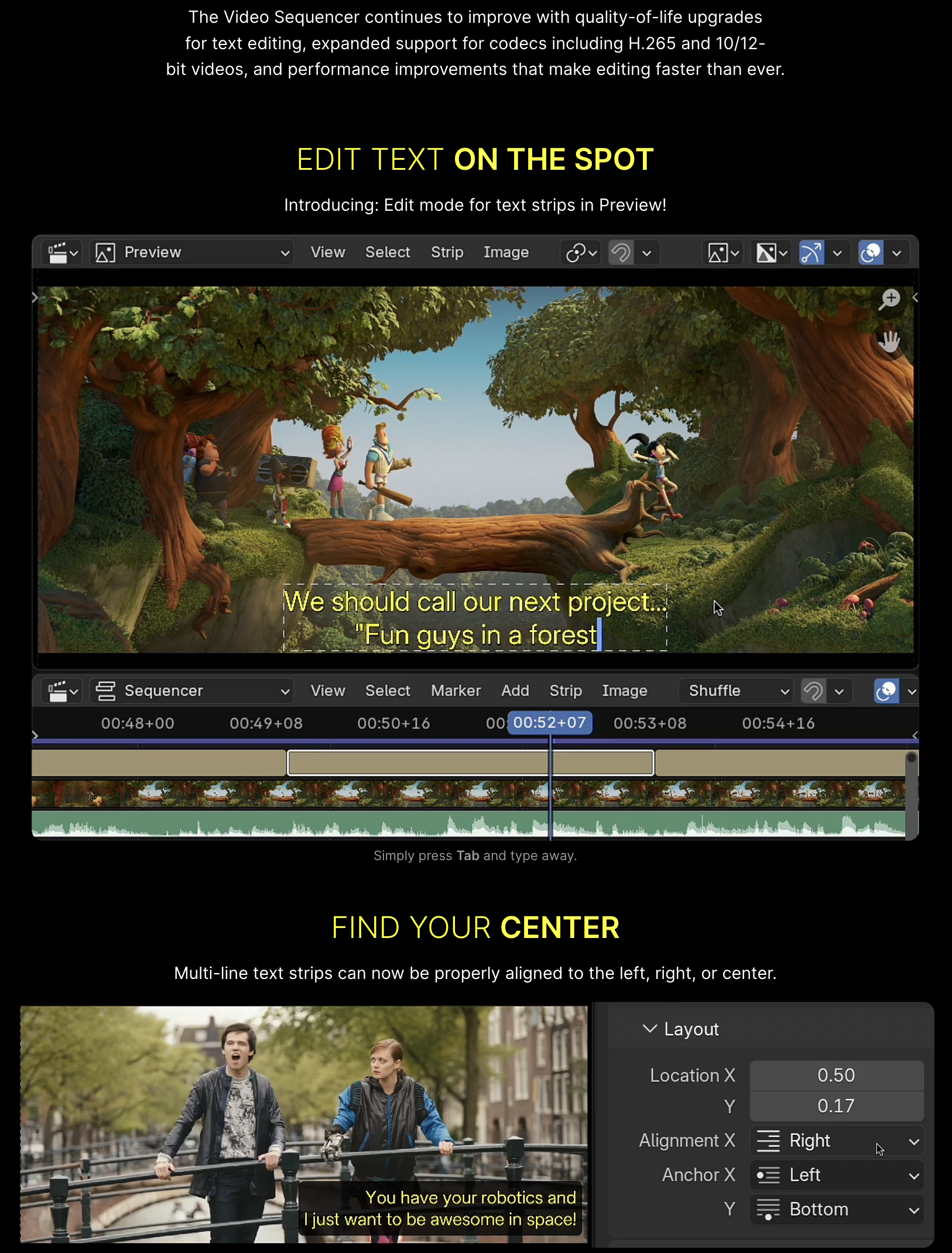
Making scopes more ready for HDR
 Current Blender Studio production, Singularity, needed improvements
to video editing visualizations, particularly in the HDR area. Visualizations that Blender can do are: histogram, waveform, RGB parade,
vectorscope, and “show overexposed” (“zebra stripes”) overlay. Some of them were not handling HDR content in a useful way, e.g.
histogram and waveform were clamping colors above “white” (1.0) and not displaying their actual value distribution.
Current Blender Studio production, Singularity, needed improvements
to video editing visualizations, particularly in the HDR area. Visualizations that Blender can do are: histogram, waveform, RGB parade,
vectorscope, and “show overexposed” (“zebra stripes”) overlay. Some of them were not handling HDR content in a useful way, e.g.
histogram and waveform were clamping colors above “white” (1.0) and not displaying their actual value distribution.
So I started to look into that, and one of the issues, particularly with waveform, was that it gets calculated on the CPU,
by putting the waveform into a width x 256 size bitmap.
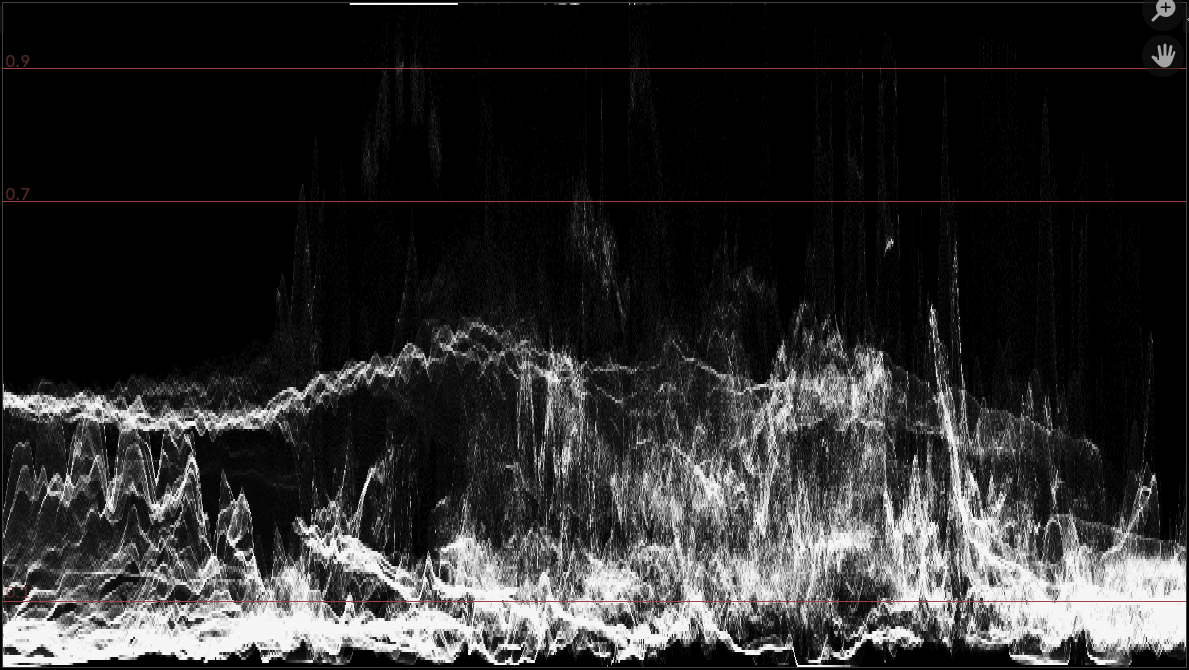
This is what a waveform visualization does: each column displays pixel luminance distribution of that column of the input
image. For low dynamic range (8 bit/channel) content, you can trivially know there are 256 possible vertical values that would
be needed. But how tall should the waveform image be for HDR content? You could guesstimate things like “waveform displays +4
extra stops of exposure” and make a 4x taller bitmap.
Or you could…
…move Scopes to the GPU
I thought that doing calculations needed for waveform & vectorscope visualizations on the CPU, then sending that bitmap to
the GPU for display sounds a bit silly. And, at something like 4K resolutions, that is not very fast either! So why
not just do that on the GPU?
The process would be:
- GPU already gets the image it needs to display anyway,
- Drawing a scope would be rendering a point sprite for each input pixel. Sample the image based on sprite ID in the vertex shader,
and position it on the screen accordingly. Waveform puts it at original coordinate horizontally, and at color luminance vertically.
Vectorscope puts it based on color YUV U,V values.
- The points need to use blending in “some way”, so that you can see how many points hit the same luminance level, etc.
- The points might need to be larger than a pixel, if you zoom in.
- The points might need to be “smaller than a pixel” if you zoom out, possibly by fading away their blending contribution.
So I did all that, it was easy enough. Performance on my RTX 3080Ti was also much better than with CPU based scopes.
Since rendering alpha blended points makes it easy to have them colored, I also made each point retain a bit of original image
pixel’s hue:
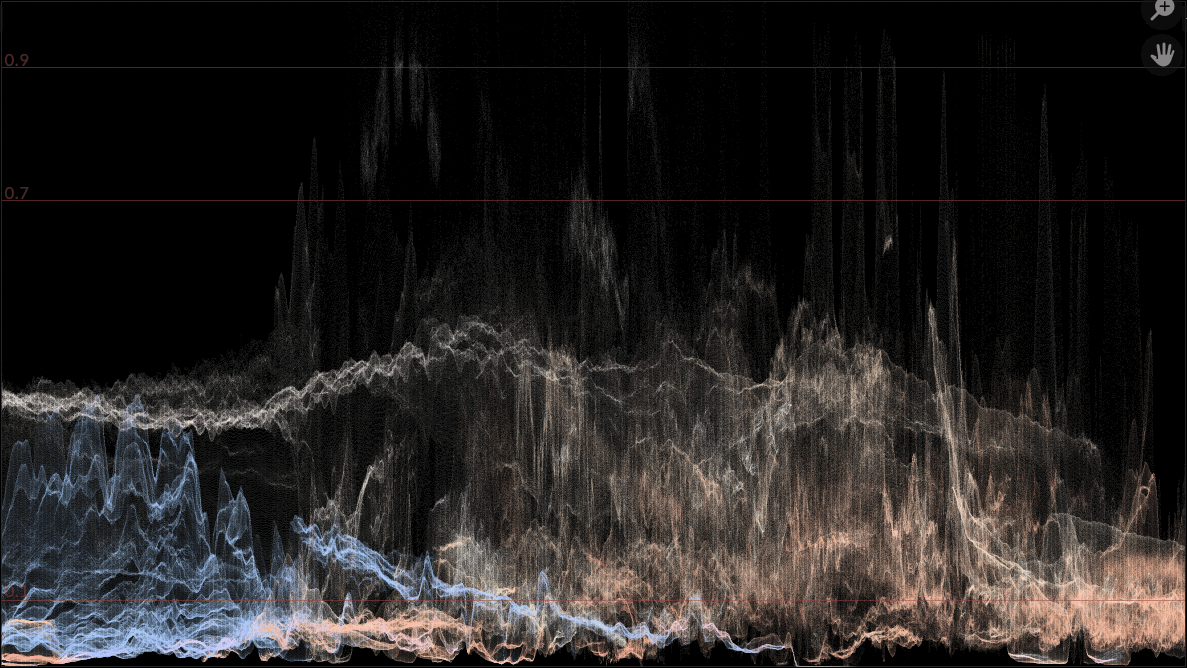
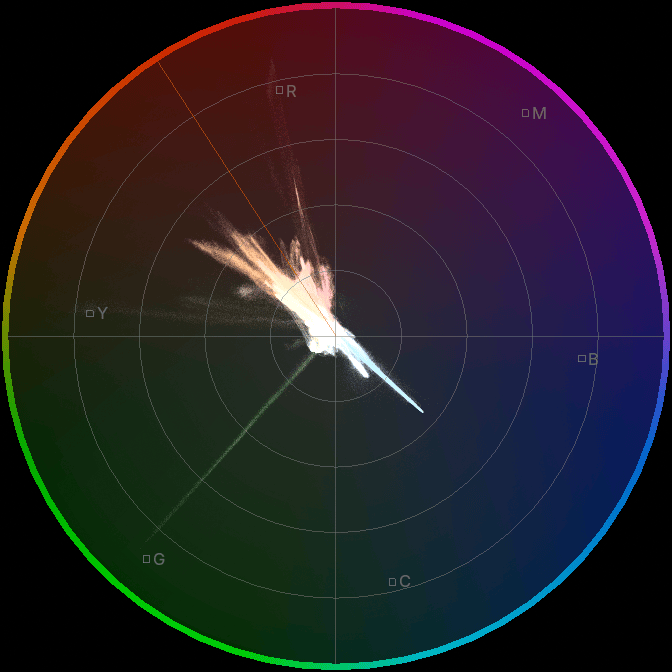
Yay, done! …and then I tested them on my Mac, just to double check if it works. It does! But the new scopes now playback at like
2 frames per second 🤯 Uhh, what is going on? Why?!
I mean, sure, at 4K resolution a full scope now renders 8 million points. But come on, that is on a M4 Max GPU; it should be able to easily
do hundreds of millions of primitives in realtime!
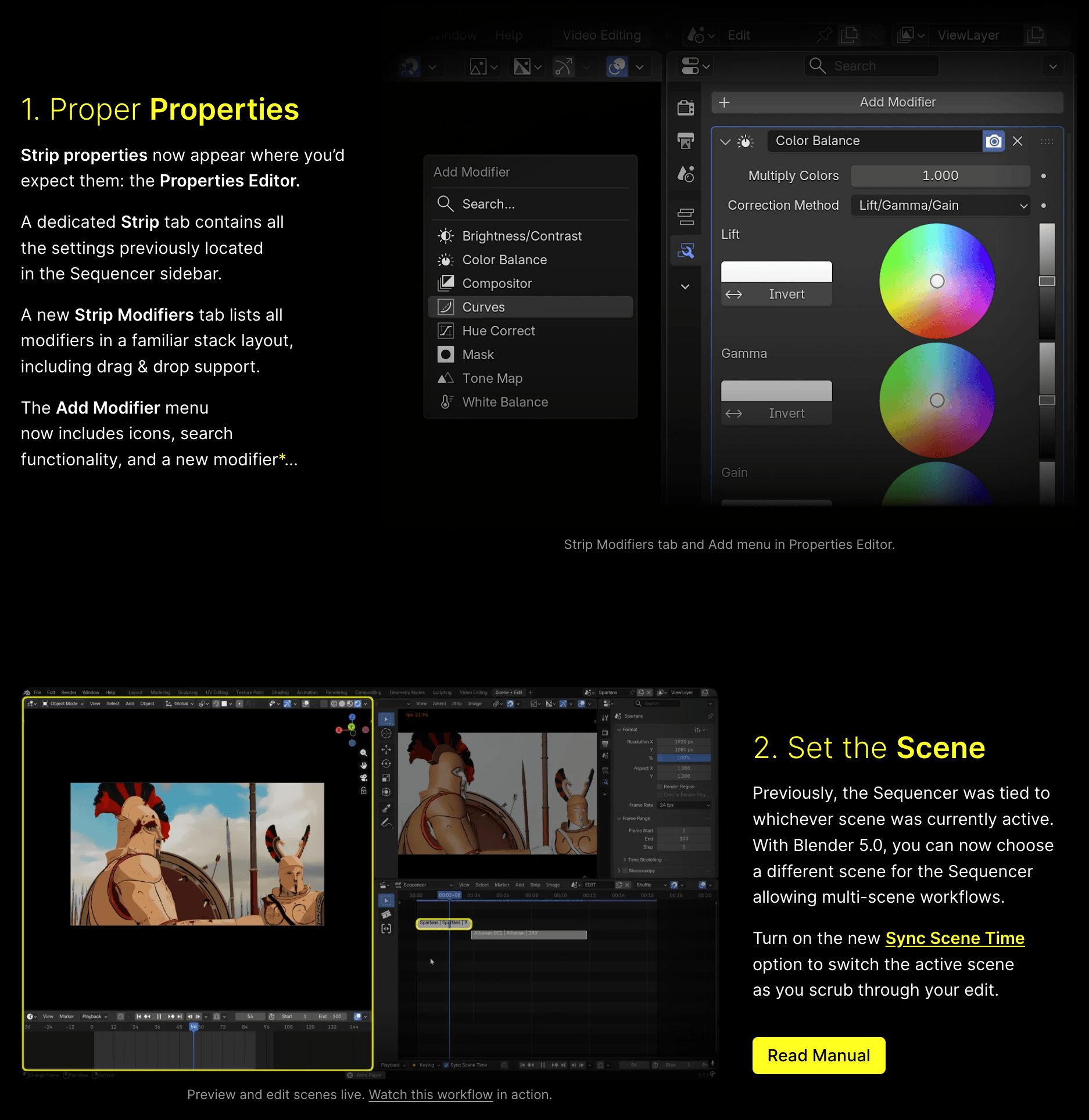
Rendering points on a GPU
Turns out, the problematic performance was mostly the vectorscope visualization. Recall that a vectorscope places points based on their
signed U,V (from YUV color model). Which means it places a lot of points very near the
center, since usually most pixels are not very saturated. A vectorscope of a grayscale image would be all the points right in
the middle!
And it turns out, GPUs are not entirely happy when many (tens of thousands or more) points are rendered at the same location
and alpha blending is on. And Apple GPUs are extremely not happy about this. “Way too many” things in the same tile are
likely to overflow some sort of tile capacity buffers (on tile-based GPUs), and blending “way too many” fragments in the same location
is probably running into a bottleneck due to fixed capacity of blending / ROP backend queues (see “A trip through the Graphics Pipeline 2011,
part 9”).
Rendering single-pixel points is not terribly efficient on any GPU, of course. GPUs rasterize everything in 2x2 pixel “quads”, so each
single pixel point is at least 4 pixel shader executions, with three of them thrown out
(see “Counting Quads” or “A trip through the Graphics Pipeline 2011,
part 8”).
Could I rasterize the points in a compute shader instead? Would that be faster?
Previous research ("Rendering Point Clouds with Compute Shaders",
related code) as well as “compute based rendering”
approaches like Media Molecule Dreams or Unreal Nanite suggest that it might be worth a shot.
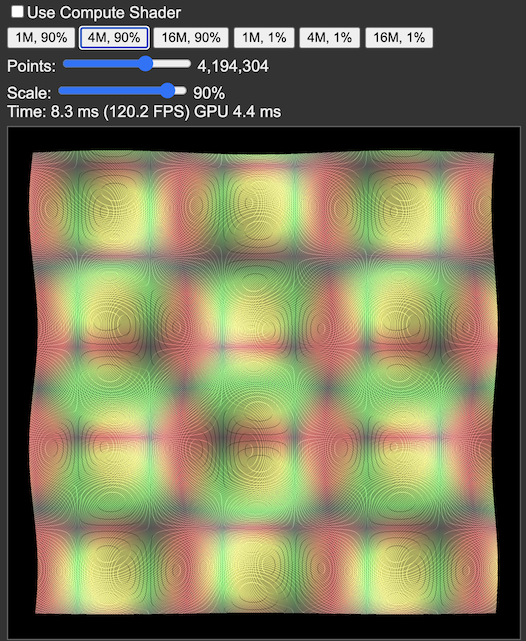 It was time to do some 🔬📊SCIENCE📊🔬: make a tiny WebGPU test that tests various point rendering scenarios,
and test it out on a bunch of GPUs. And I did exactly that:
webgpu-point-raster.html
that renders millions of single pixel points in a “regular” (500x500-ish) area down to “very small” (5x5 pixel)
area, with alpha blending, using either the built-in GPU point rendering, or using a compute shader.
It was time to do some 🔬📊SCIENCE📊🔬: make a tiny WebGPU test that tests various point rendering scenarios,
and test it out on a bunch of GPUs. And I did exactly that:
webgpu-point-raster.html
that renders millions of single pixel points in a “regular” (500x500-ish) area down to “very small” (5x5 pixel)
area, with alpha blending, using either the built-in GPU point rendering, or using a compute shader.
A bunch of people on the interwebs tested it out and I got results from 30+ GPU models, spanning all sorts of GPU architectures
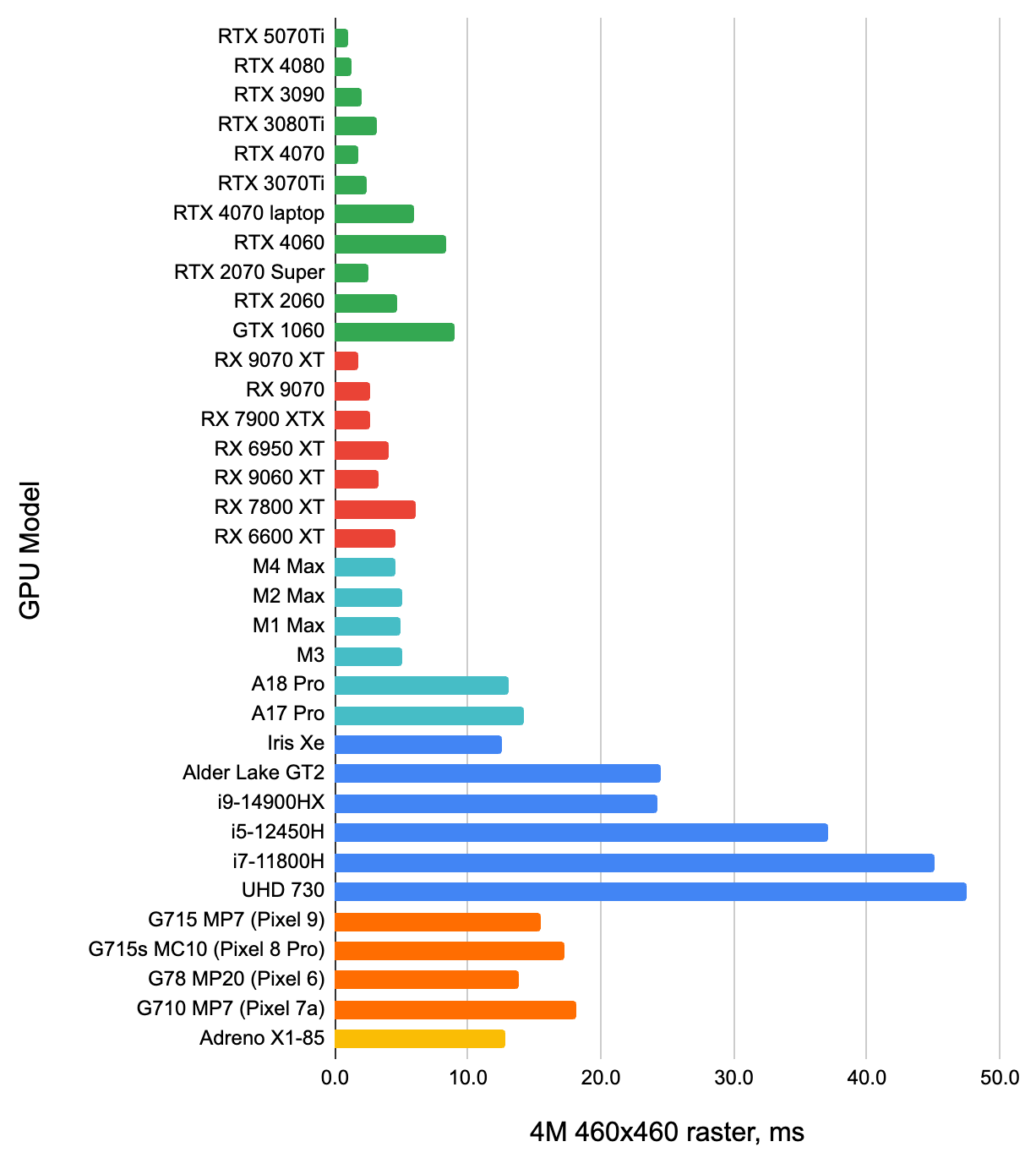
and performance levels. Here, how much time each GPU takes to render 4 million single-pixel points into a roughly
460x460 pixel area (so about 20 points hitting each pixel). The second chart is how many times point rasterization becomes
slower, if the same amount of points gets blended into a 5x5 pixel area (160 thousand points per pixel).
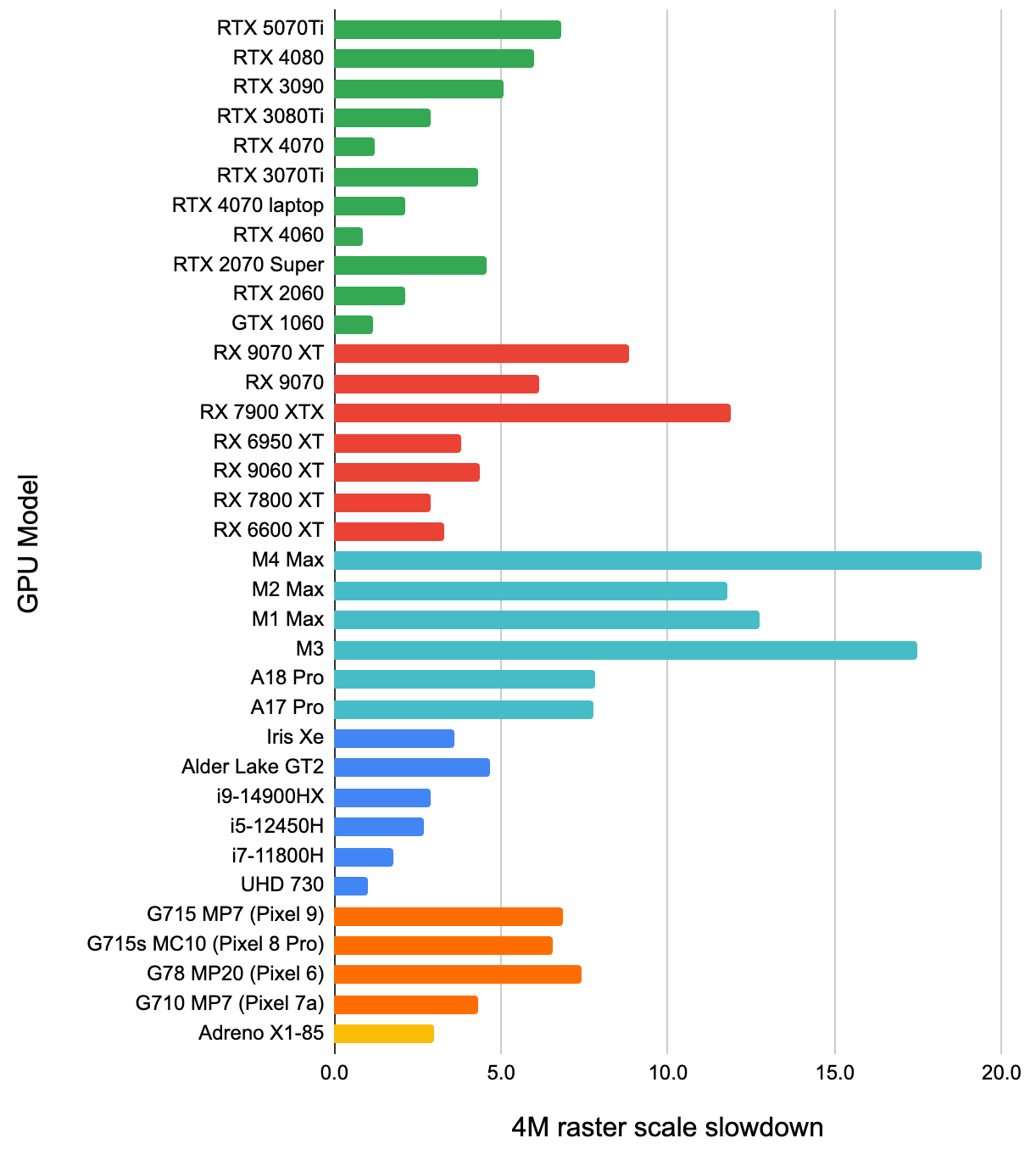
From the second chart we can see that even if conceptually the GPU does the same amount of work – same amount of points doing the same
type of animation and blending, and the 2x2 quad overshading affects both scenarios the same – all the GPUs render slower
when points hit a much smaller screen area. Everyone is slower by 2-5 times, and then there are Apple Mac GPUs that are
12-19 times slower. Also curiously enough, even within the same GPU vendor, it looks like the “high-end” GPUs experience
a relatively larger slowdown.
My guess is that this shows the effect of blending units having a limited size “queue” and nature
of the fact that blending needs to happen serially and in-order (again, see
part 9 mentioned above). And Apple
GPUs affected way more than anyone else is… I don’t know why exactly. Maybe because they do not have fixed function
blending hardware at all (instead the shader reads current pixel value and does blending by modifying it), so in order to
maintain the correct blending ordering, the whole pixel execution needs to be in some sort of “queue”?
Curiously Apple’s own performance tools (Metal frame capture in Xcode) does not tell anything useful for this case,
except “your fragment shader takes forever!”. It is not entirely incorrect, but it would be useful
if it said “it is not the part of your code that is slow, it is blending”.
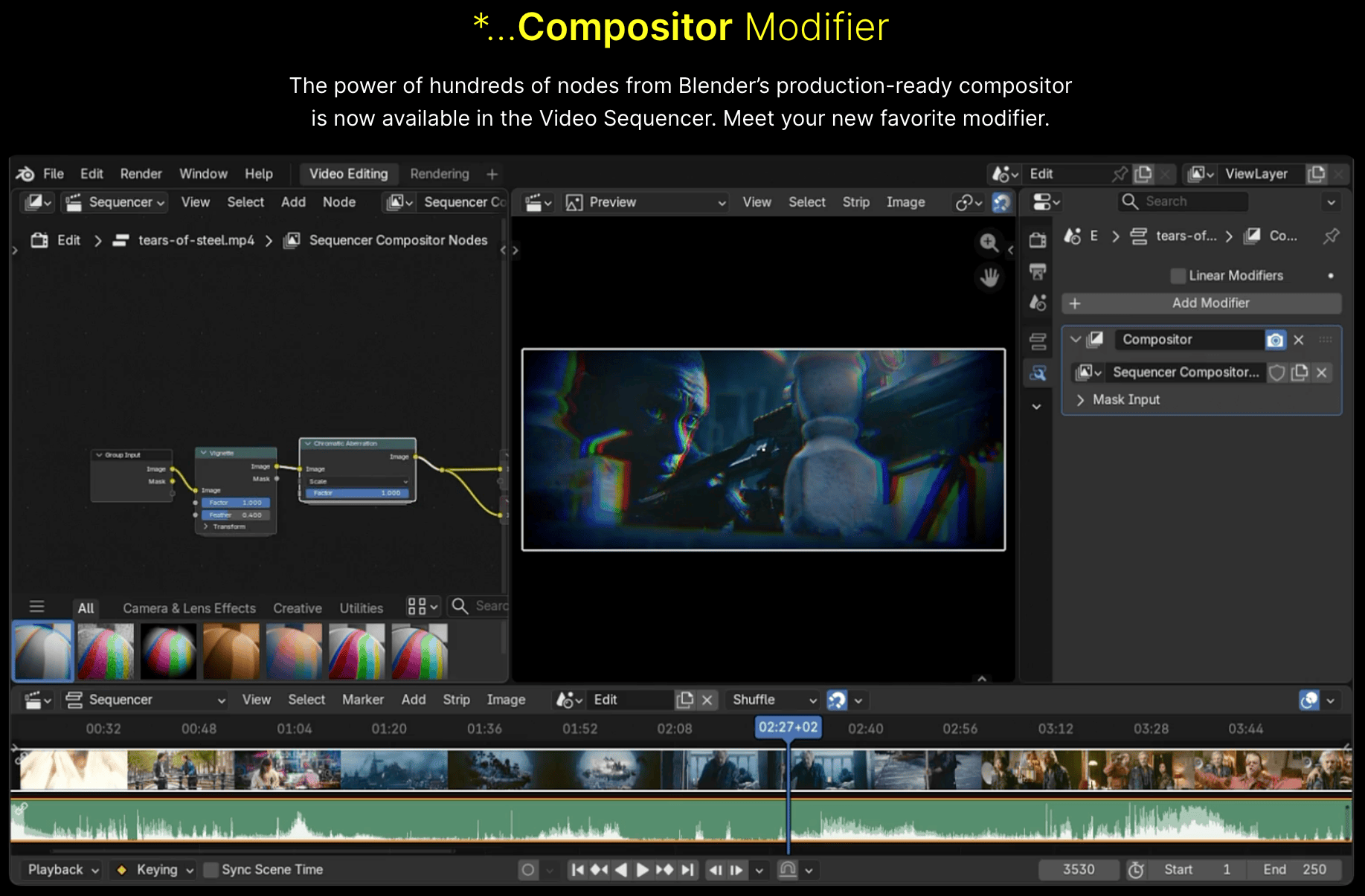
Let’s do some compute shader point rendering!
The compute shader is trivially naïve approach: have R,G,B uint per pixel buffers, each point does atomic add of the fixed point color,
finally a regular fragment shader resolves these buffers to visible colors. It is a “baby’s first compute”
type of approach really, without any tricks like using wave/subgroup operations to detect whole wavefront hitting the same pixel,
or distributing points into tiles + prefix sum + rasterize points inside tiles, or trying to pack the color buffers into something
more compact. None of that, so I was not expecting the compute shader approach to be much better.
Here’s two charts: how much faster is this simple compute shader approach, compared to built-in GPU point rendering. First for the
“4M points in 460x460 pixel area” case, then for the 5x5 pixel area case:
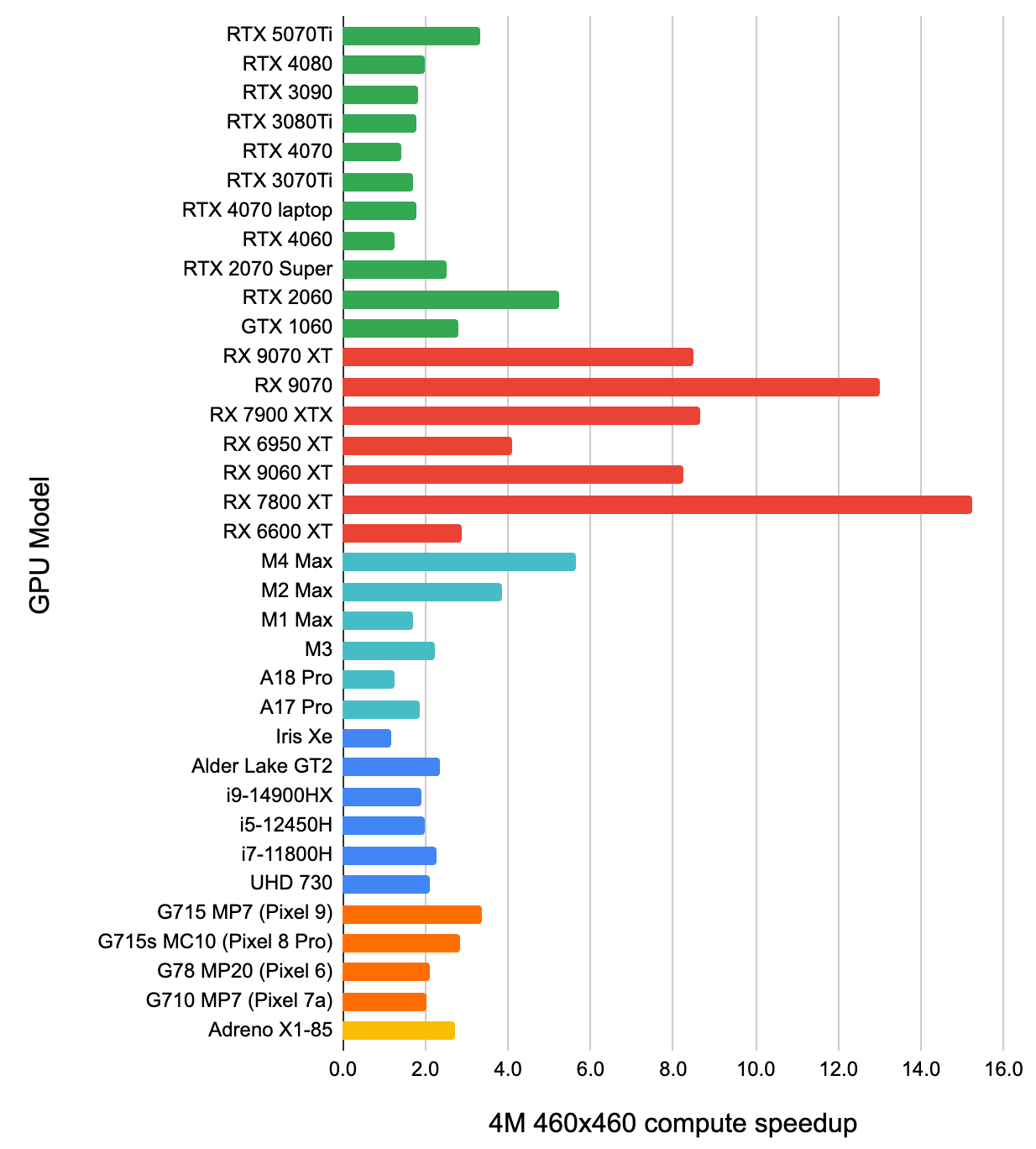
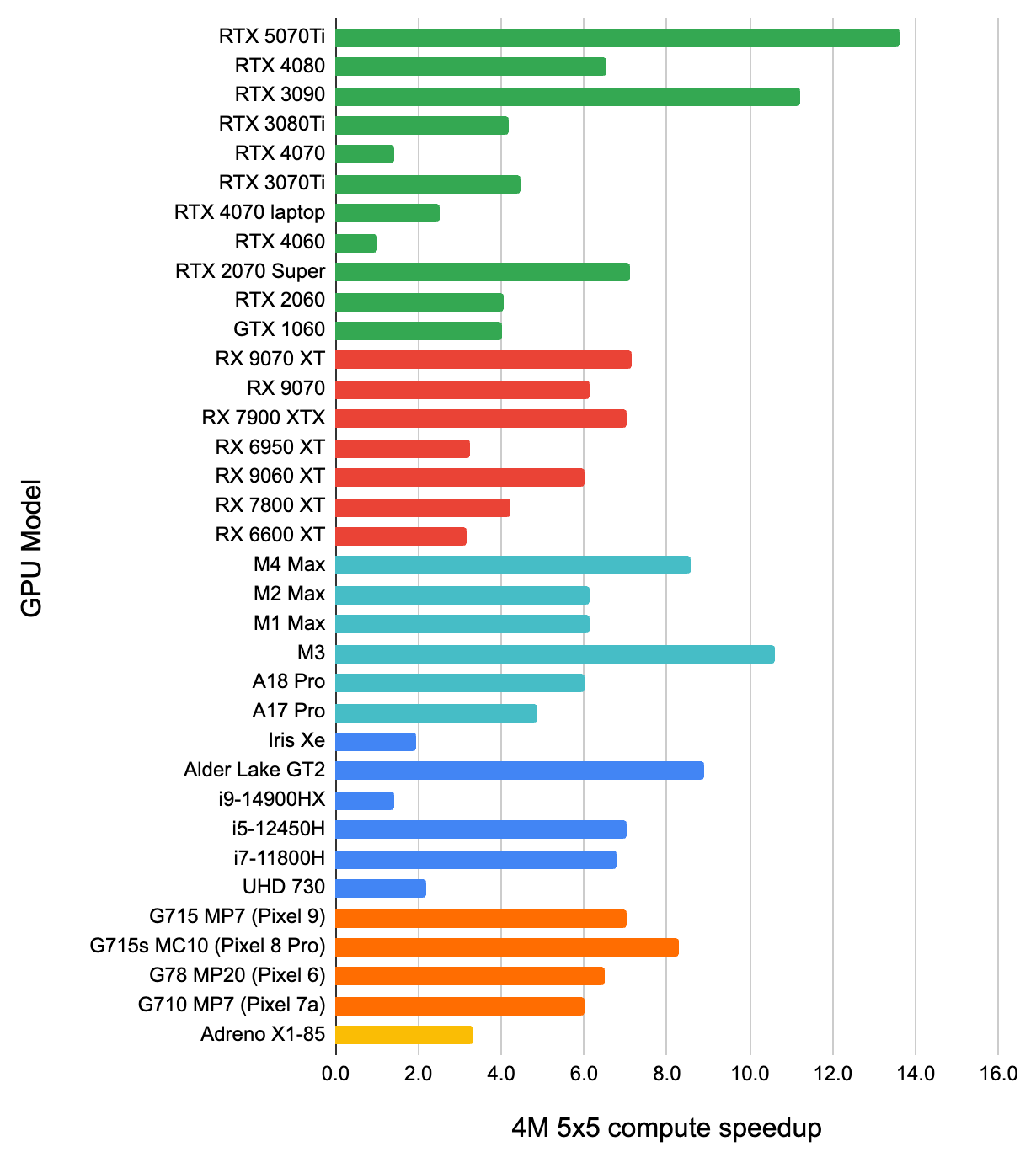
Several surprising things:
- Even this trivial compute shader for the not-too-crazy-overdraw case, is faster than built-in point rasterization on all GPUs.
Mostly it is 1.5-2 times faster, with some outliers (AMD GPUs love it – it is like 10x faster than rasterization!).
- For the “4M points in just a 5x5 pixel area” case, the compute shader approach is even better. I was not expecting that –
the atomic additions it does would get crazily contended – but it is around 5x faster that rasterization across the board.
My only guess is that while contended atomics are not great, they perhaps are still better than contended blending units?
Finally, a chart to match the rasterization chart: how many times the compute shader rendering gets slower, when 460x460
area gets reduced to 5x5 one:
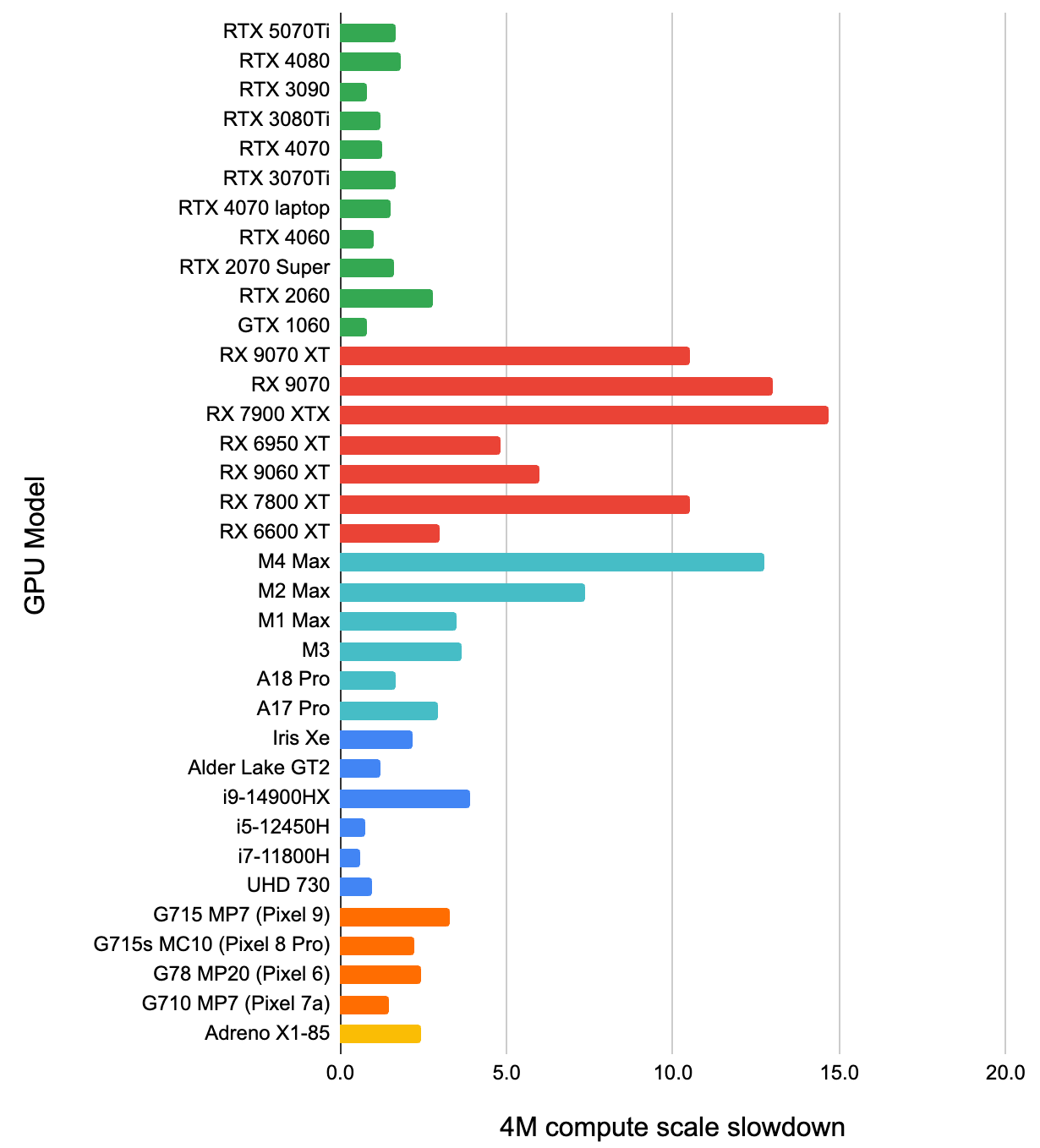
I think this shows “how good the GPU is at dealing with contended atomics”, and it seems to suggest that relatively speaking,
AMD GPUs and recent Apple GPUs are not that great there. But again, even with this relative slowdown, the compute shader
approach is way faster than the rasterization one, so…
Compute shaders are useful! What a finding!
But let’s get back to Blender.
Blender Scopes on the GPU, with a compute shader
So that’s what I did then - I made the Blender video sequencer waveform/parade/vectorscope be calculated and rendered on the
GPU, using a compute shader to do point rasterization. That also allowed to do “better” blending than what would be possible
using fixed function blending, actually – since I am accumulating the points hitting the same pixel, I can do a non-linear
alpha mapping in the final resolve pass.
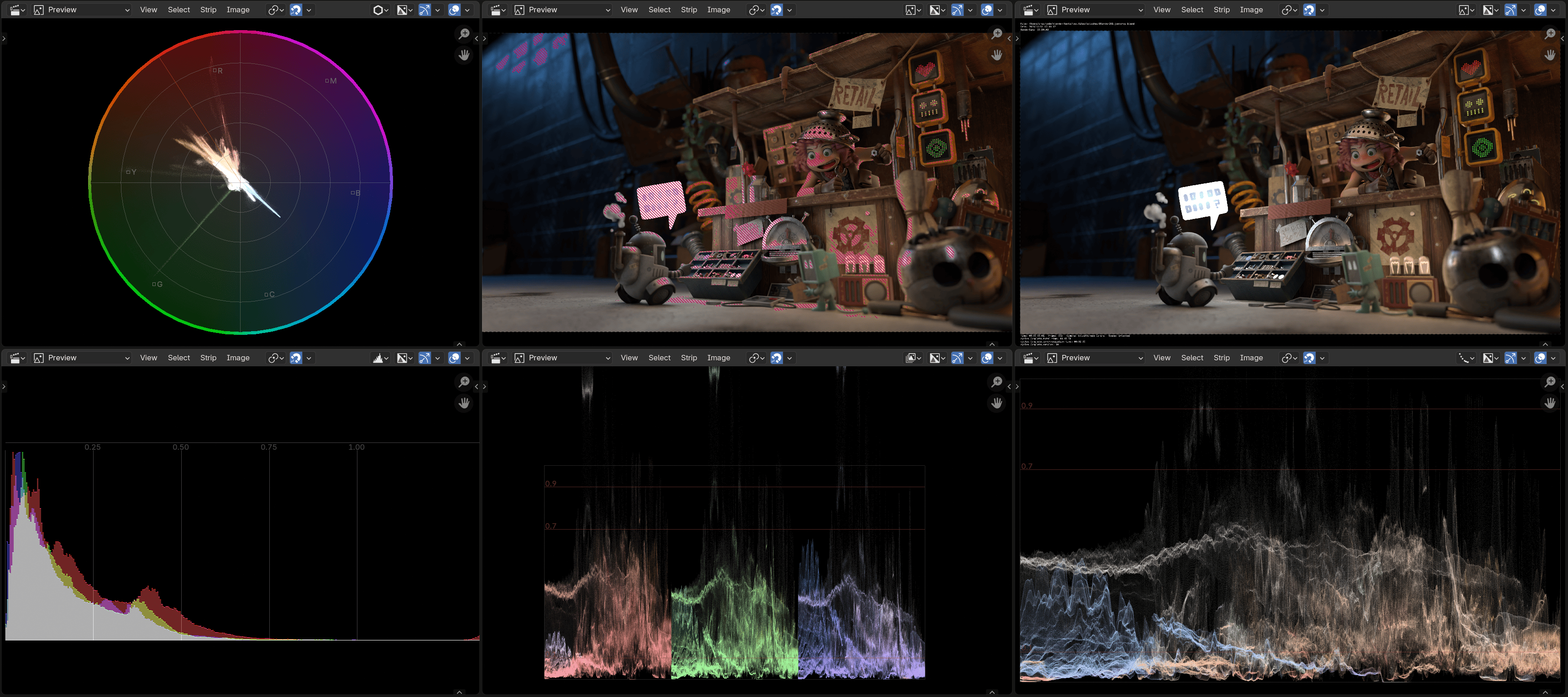
The pull request #144867 has not landed yet has just landed,
so scopes in Blender 5.0 will get faster and look better. All the scopes, everywhere, all at once, now look like this:
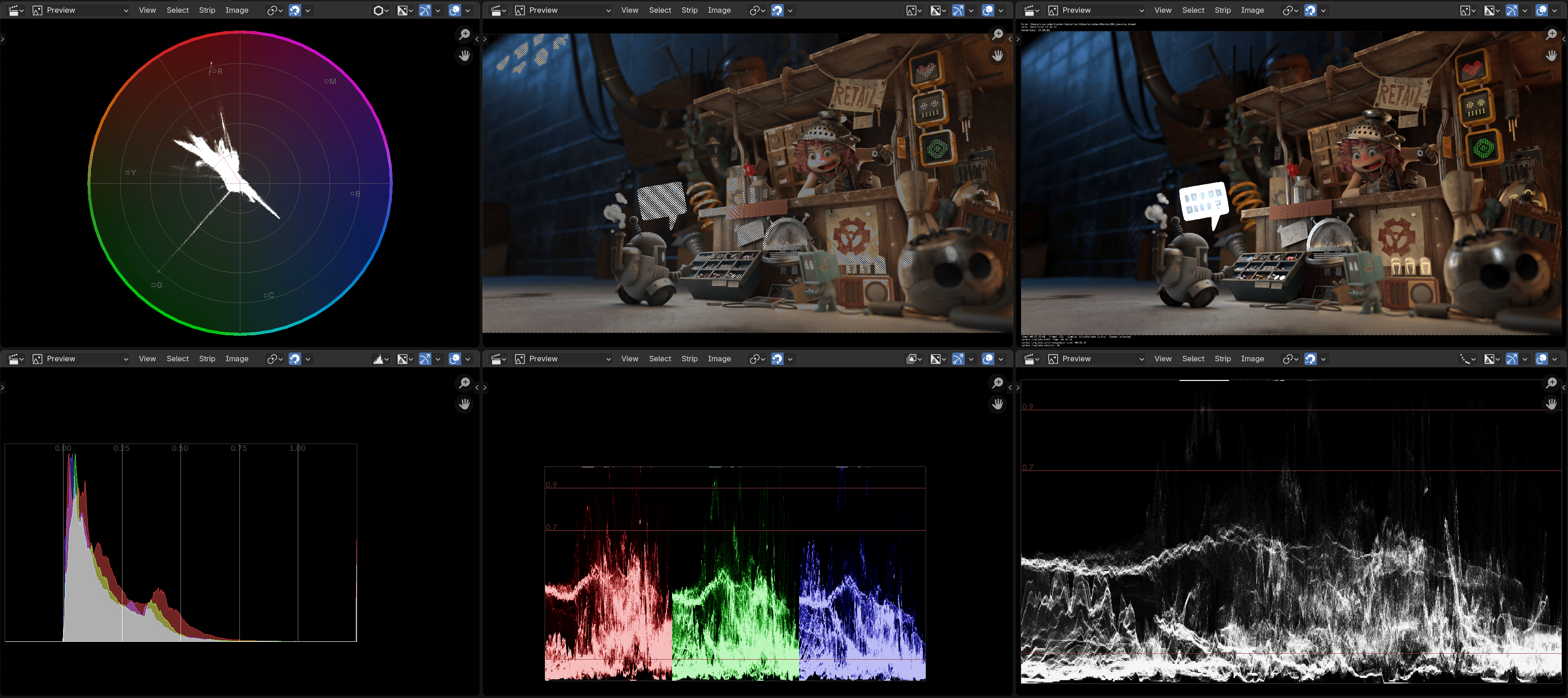
Whereas in current Blender 4.5 they look like this:
And for historical perspective, two years ago in Blender 4.0, before I started to
dabble in this area, they looked like this:
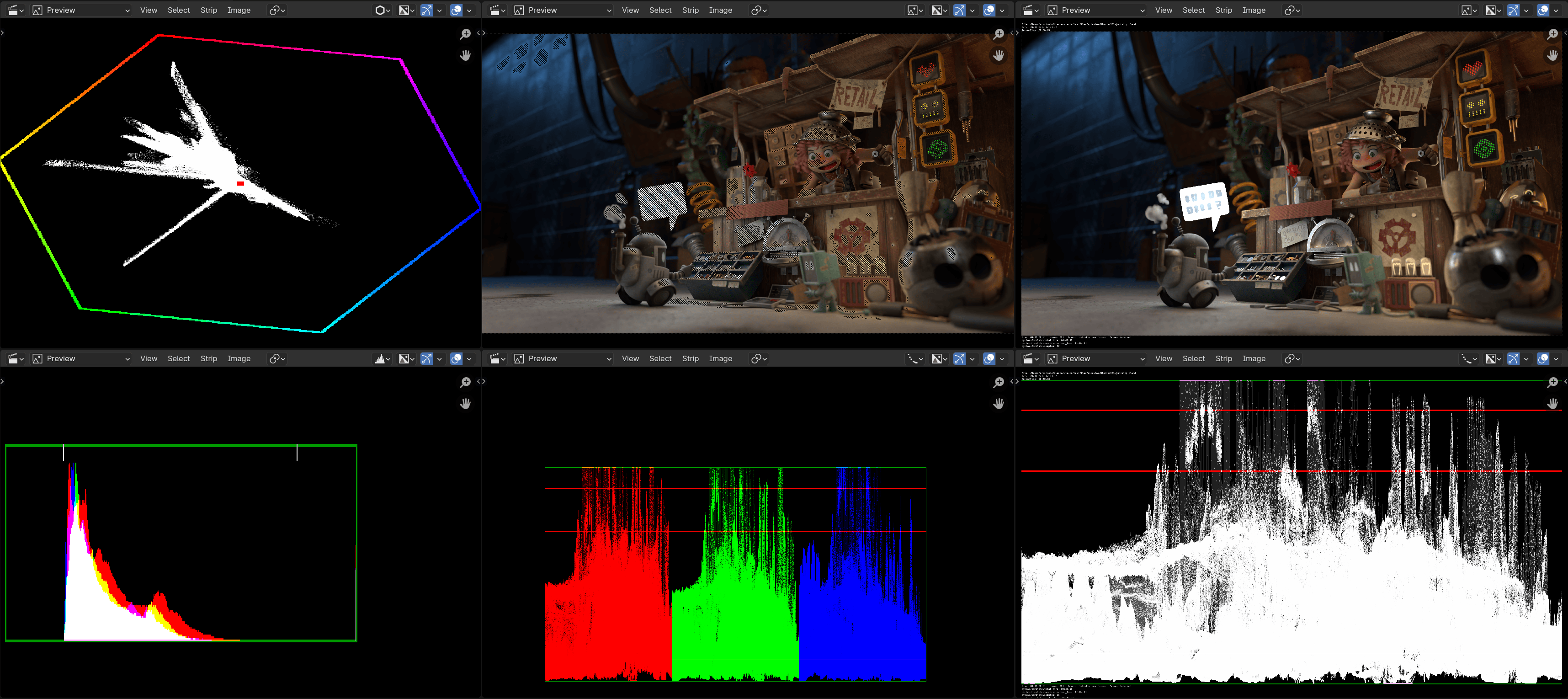
Also, playback of this screen setup (4K EXR images, all these views/scopes) on my PC was at 1.1FPS in Blender 4.0; at 7.9FPS
in Blender 4.5; and at 14.1FPS with these GPU scopes. Still work to do, but hey, progress.
That’s it, bye!