Float Compression 8: Blosc
Introduction and index of this series is here.
Several people have asked whether I have tried Blosc library for compressing my test data set. I was aware of it, but have not tried it! So this post is fixing that.
In the graphics/vfx world, OpenVDB uses Blosc as one option for volumetric data compression. I had no idea until about two weeks ago!
What is Blosc?
Blosc is many things, but if we ignore all the parts that are not relevant for us (Python APIs etc.), the summary is fairly simple:
- It is a data compression library geared towards structured (i.e. arrays of same-sized items) binary data. There’s a fairly simple C API to access it.
- It splits the data into separate chunks, and compresses/decompresses them separately. This optionally allows multi-threading by putting each chunk onto a separate job/thread.
- It has a built-in compression codec
BloscLZ, based on FastLZ. Out of the box it also builds with support for Zlib, LZ4, and Zstd. - It has several built-in lossless data filtering options: “shuffle” (exactly the same as “reorder bytes” from part 3), “bitshuffle” and “delta”.
All this sounds pretty much exactly like what I’ve been playing with in this series! So, how does Blosc with all
default settings (their own BloscLZ compression, shuffle filter) compare? The below is on Windows, VS2022 (thin solid
lines are zstd and lz4 with byte reorder + delta filter optimizations from previous post; dashed lines are zstd and lz4 without any filtering; thick line
is blosc defaults):
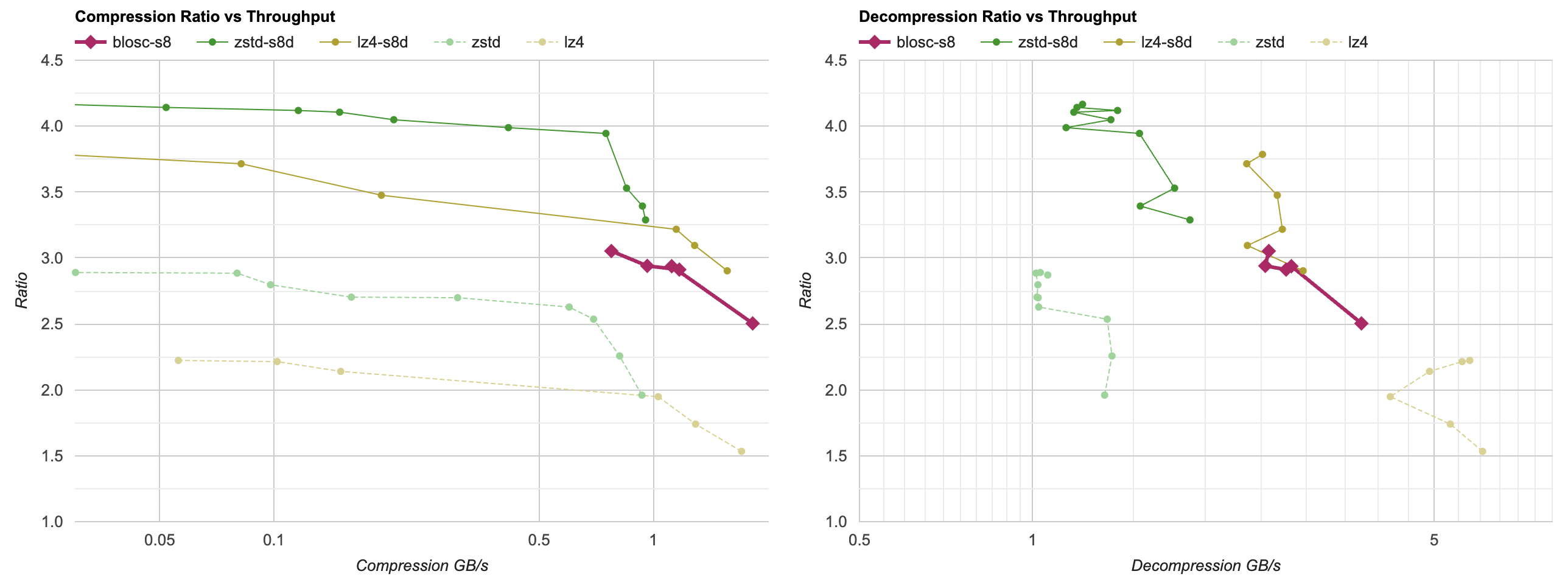
So, Blosc defaults are:
- Better than just throwing zstd at the data set: slightly higher compression ratio, faster compression, way faster decompression.
- Mostly better than just using lz4: much better compression ratio, faster compression, decompression slightly slower but still fast.
- However, when compared to my filters from previous post, Blosc default settings do not really “win” – compression ratio is quite a bit lower (but, compression and decompression speed is very good).
Note that here I’m testing Blosc without using multi-threading, i.e. nthreads is set to 1 which is the default.
I’m not quite sure how they arrive at the “Blosc is faster than a memcpy()” claim on their website though. Maybe if all the data is literally zeroes, you could get there? Otherwise I don’t quite see how any LZ-like codec could be faster than just a memory copy, on any realistic data.
Blosc but without the Shuffle filter
Ok, how about Blosc but using LZ4 or Zstd compression, instead of the default BloscLZ? And for now, let’s also turn
off the default “shuffle” (“reorder bytes”) filter:
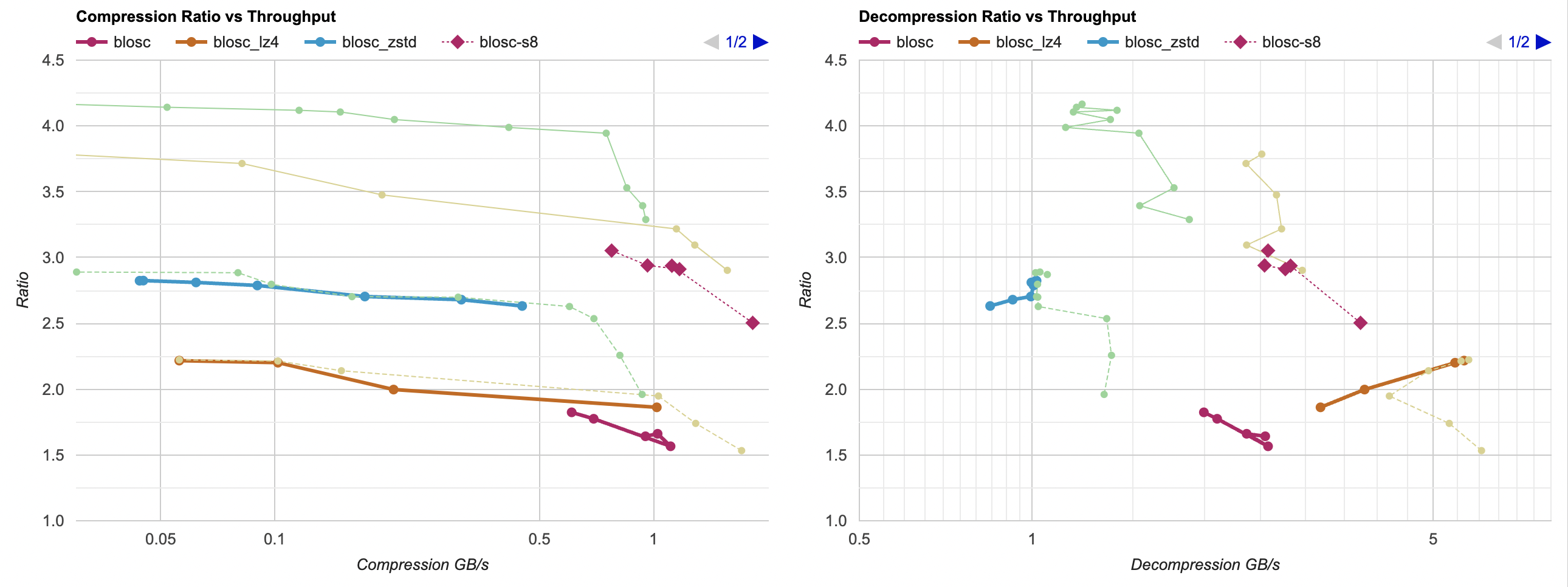
- Without “shuffle” filter, Blosc-Zstd basically is just Zstd, with a very small overhead and a tiny loss in compression ratio. Same for Blosc-LZ4; it is “just” LZ4, so to speak.
- BloscLZ compressor without the shuffle filter is behind vanilla LZ4 both in terms of ratio and performance.
Blosc with Shuffle, and Zstd/LZ4
What if we turn the Shuffle filter back on, but also try LZ4 and Zstd?
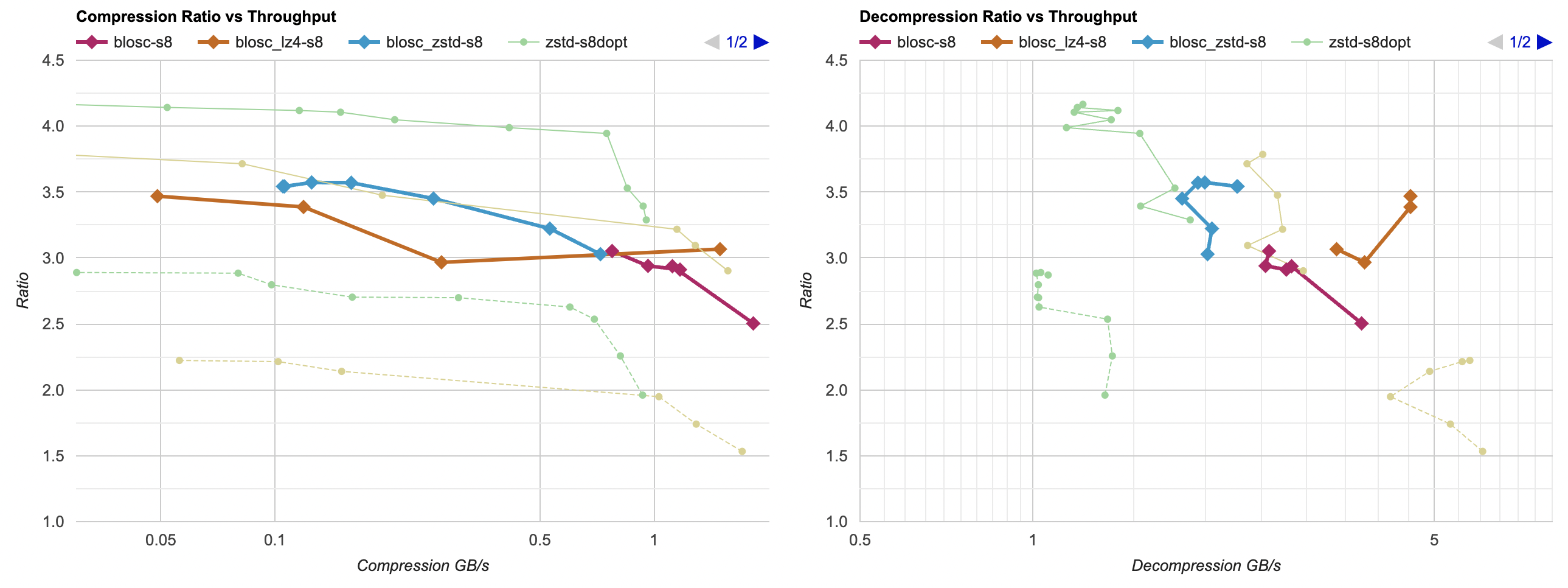
For both zstd and lz4 cases, the compression ratio is below what “my” filter achieves. But the decompression performance is interesting: Blosc-Zstd is slightly ahead of “zstd + my filter”, and Blosc-LZ4 is quite a bit ahead of “lz4 + my filter”. So that’s interesting! So far, Blosc-LZ4 with Shuffle is on the Pareto frontier if you need that particular balance between ratio and decompression performance.
Blosc with Shuffle and Delta filters
Looks like Blosc default Shuffle filter is exactly the same as my “reorder bytes” filter. But in terms of best compression ratio,
“reorder bytes + delta” was the best option so far. Oh hey, Blosc (since version 2.0) also has a filter named “Delta”! Let’s try that
one out:
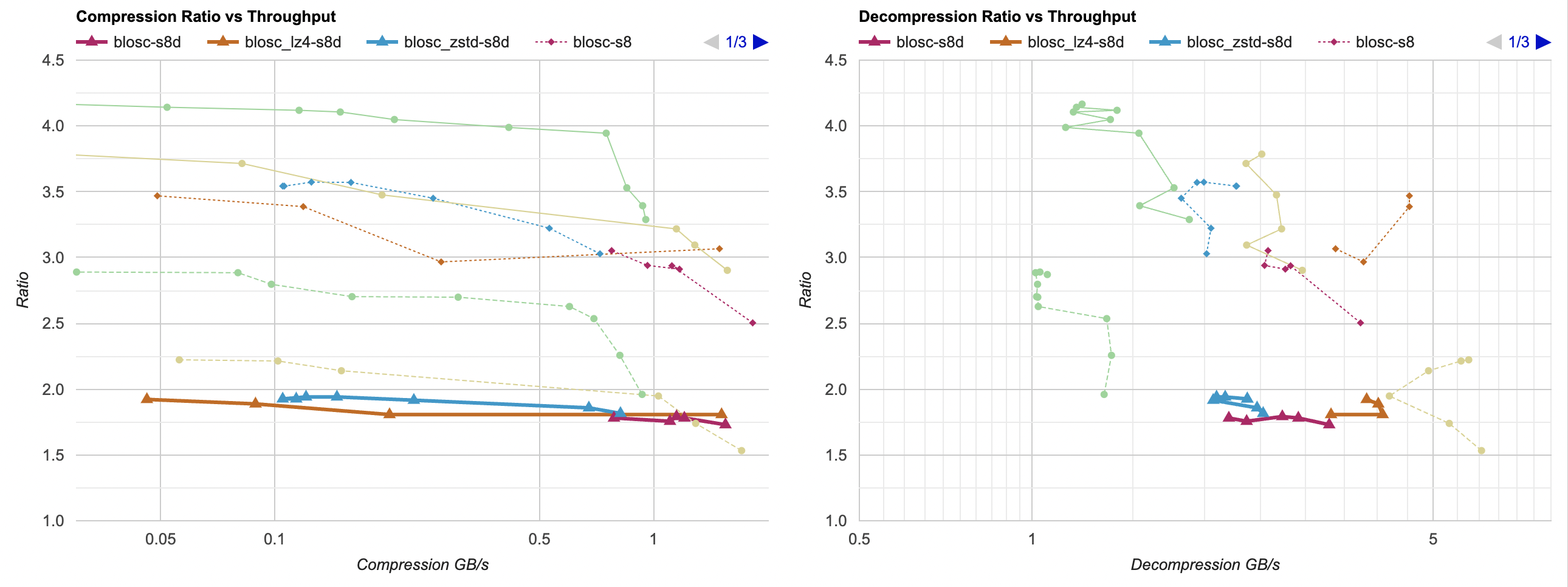
Huh. The Shuffle + Delta combination is, like, not great at all? The compression ratio is below 2.0 everywhere; i.e. worse than just zstd or lz4 without any data filtering? 🤔
Oh wait, looks like Blosc’ “Delta” filter is not a “delta” at all. Sometime in 2017 they changed it to be a XOR filter instead (commit). The commit message says “for better numerical stability”, no idea what that means since this is operating all on integers.
Ah well, looks like at least on this data set, the Delta filter does not do anything good, so we’ll forget about it. Update: look at “bytedelta” filter below, new in Blosc 2.8!
Input data chunking
The question remains, why and how is Blosc-LZ4 with Shuffle faster at decompression than “my” filter with LZ4? One reason could be that my filter is not entirely optimized (very possible). Another might be that Blosc is doing something differently…
And that difference is: by default, Blosc splits input data into separate chunks. The chunk sizes seem to be 256 kilobytes by default. Then each chunk is filtered and compressed completely independently from the other chunks. Of course, the smaller the chunk size, the lower is the compression ratio that you get, since the LZ compression codec can’t “see” data repetitions outside the chunk boundaries.
What if I added very similar “data chunking” to “my” tests, i.e. just zstd/lz4, my filters, and all that split
into independent chunks? Here’s without chunks, plus graphs for 64KB, 256KB, 1MB, 4MB chunk sizes:
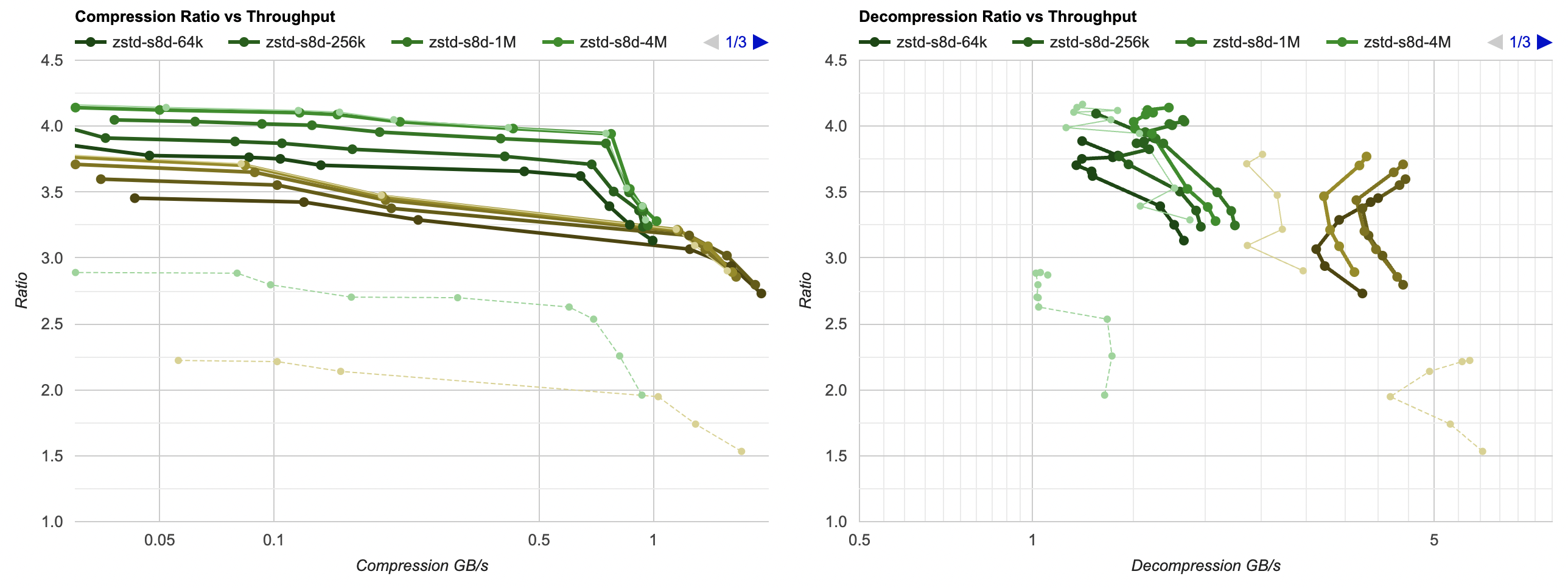
It is a bit crowded, but you can see how splitting data into 4MB chunks practically does not lose any compression ratio,
yet manages to make LZ4 decoding quite a bit faster. With much smaller chunk sizes of 64KB, the compression ratio
loss seems to be “maybe too large” (still way better than without any data filtering though). It feels like chunk size of 1MB
is quite good: very small compression ratio loss, good decompression speedup:
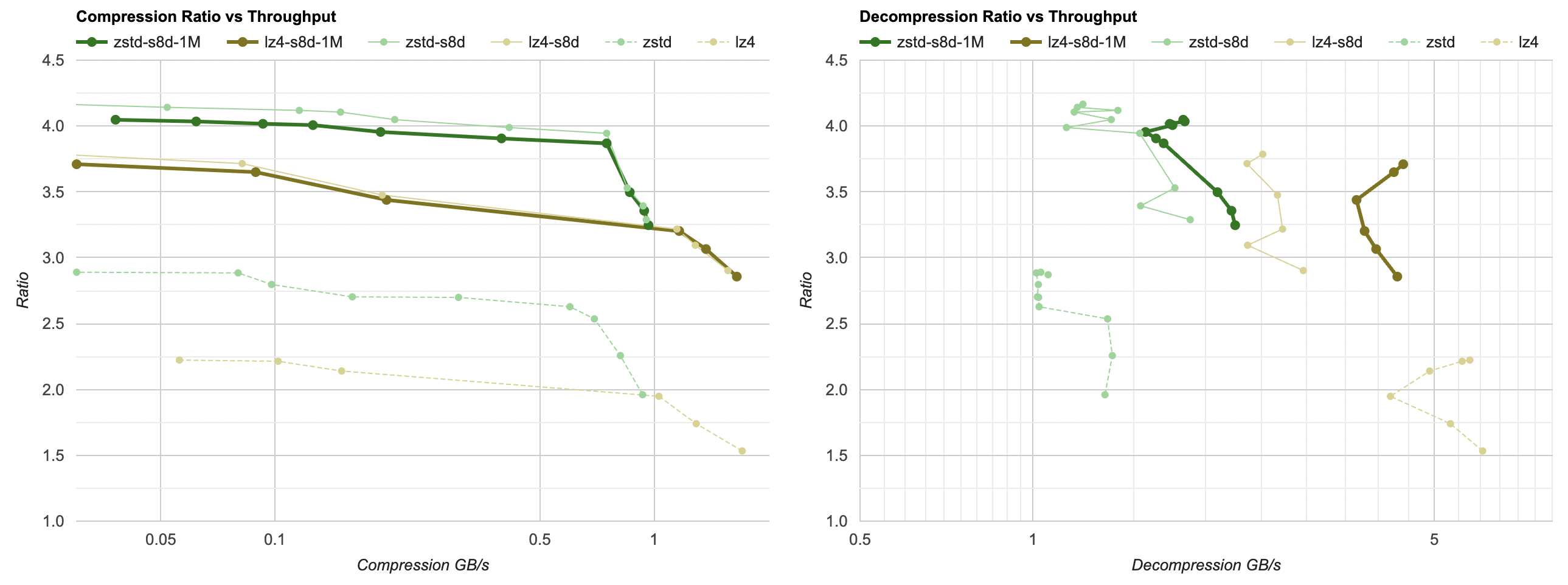
So this is another trick that is not directly related to Blosc: splitting up your data into separate 256KB-1MB chunks might be worth doing. Not only this would enable operating on chunks in parallel (if you wish to do that), but also it speeds things up, especially decompression. The reason being that the working set memory needed to do decompression now neatly fits into CPU caches.
Update: “bytedelta” filter in Blosc 2.8
Something quite amazing happened: seemingly after reading this same blog post and the previous one, Blosc people added a new filter called “bytedelta”, that, well, does exactly what you’d think it would – it is delta encoding. Within Blosc, you would put a “shuffle” (“split bytes” in my posts) filter, followed by a “bytedelta” filter.
This just shipped in Blosc 2.8.0, and they have an in-depth blog post testing it on ERA5 data sets, a short video, and a presentation at LEAPS Innov WP7 (slides). That was fast!
So how does it compare?
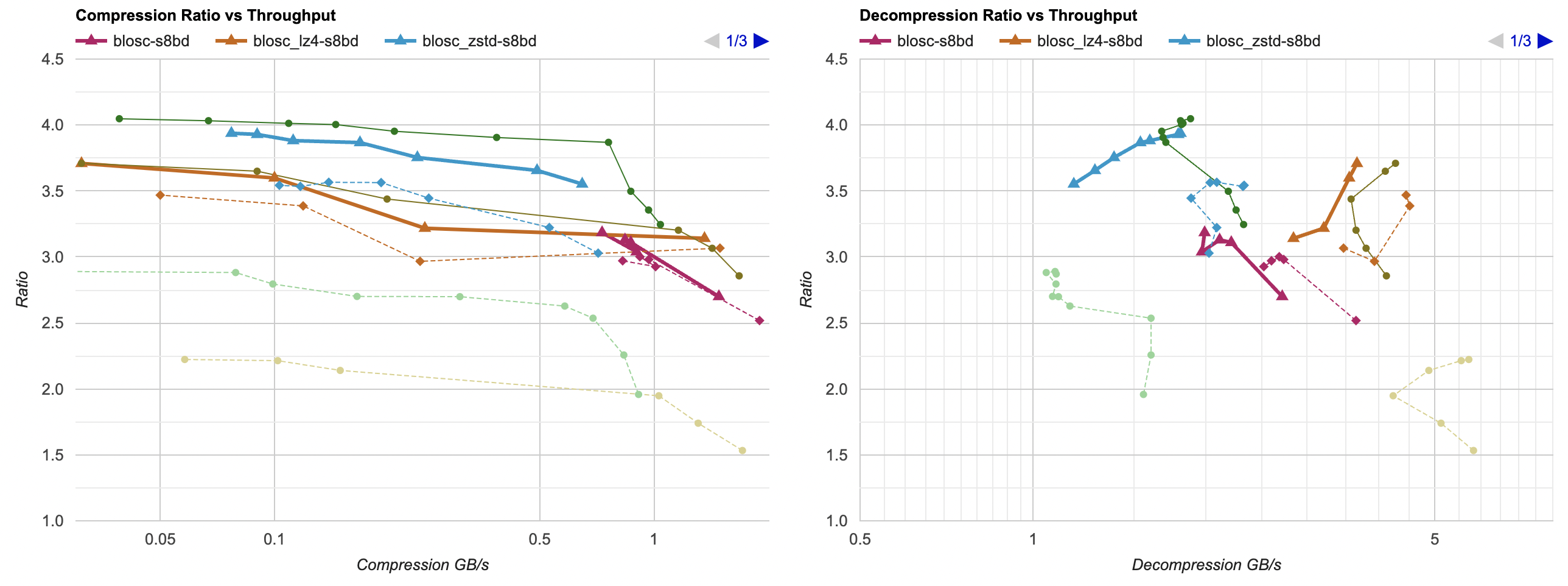
- Thick solid lines are Blosc shuffle+bytedelta, for the three bases of Blosc built-in BLZ compression, as well as Blosc using LZ4 and Zstd compression.
- For comparison, Blosc with just shuffle filter are dashed lines of the same color.
- There’s also “my own” filter from previous post using LZ4 and Zstd and splitting into 1MB chunks on the graph for comparison.
So, Blosc bytedelta filter helps compression ratio a bit in BLZ and LZ4 cases, but helps compression ratio a lot when using Zstd. It is a sligth loss of compression ratio compared to best result we have without Blosc (Blosc splits data into ~256KB chunks by default), and a bit slower too, probably because the “shuffle” and “bytedelta” are separate filters there instead of combined filter that does both in one go.
But it’s looking really good! This is a great outcome. If you are using Blosc, check whether “shuffle” + “bytedelta” combination works well on your data. It might! Their own blog post has way more extensive evaluation.
Aside: “reinventing the wheel”
Several comments I saw about this whole blog post series were along the lines of “what’s the point; all of these things were already invented”. And that is true! I am going down this rabbit hole mostly for my own learning purposes, and just writing them down because… “we don’t ask why, we ask why not”.
I have already learned a bit more about compression, data filtering and SIMD, so yay, success. But also:
- The new “bytedelta” filter in Blosc 2.8 is very directly inspired by this blog post series. Again, this is not a new invention; delta encoding has been around for many decades. But a random post on the interwebs can make someone else go “wait, turns out we don’t have this trick, let’s add it”. Nice!
- After writing part 7 of these series, I looked at OpenEXR code again, saw that while they do have Intel SSE optimizations for zip-compressed .exr files reading, they do not have ARM NEON paths. So I added those, and that makes loading .exr files that use zip compression almost 30% faster on a Mac M1 laptop. That shipped in OpenEXR 3.1.6, yay!
So I don’t quite agree with some random internet commenters saying “these posts are garbage, all of this has been invented before”. The posts might be garbage, true, but 1) I’ve learned something and 2) improvements based on these posts have landed into two open source software libraries by now.
Don’t pay too much attention to internet commenters.
Conclusions
Blosc is pretty good!
I do wonder why they only have a “shuffle” filter built-in though (there’s also “delta” but it’s really some sort of “xor”).
At least on my data, “shuffle + actual delta” would result in much better compression ratio. Without having that filter,
blosc loses to the filter I have at the end of previous post
in terms of compression ratio, while being roughly the same in performance (after I apply 1MB data chunking in my code). Update: since 2.8 Blosc has a “bytedelta” filter; if you put that right after “shuffle” filter
then it gets results really close to what I’ve got in the previous post.