Float Compression 9: LZSSE and Lizard
Introduction and index of this series is here.
Some people asked whether I have tested LZSSE or Lizard. I have not! But I have been aware of them for years. So here’s a short post, testing them on “my” data set. Note that at least currently both of these compressors do not seem to be actively developed or updated.
LZSSE and Lizard, without data filtering
Here they are on Windows (VS2022, Ryzen 5950X). Also included Zstd and LZ4 for comparison, as faint dashed lines:
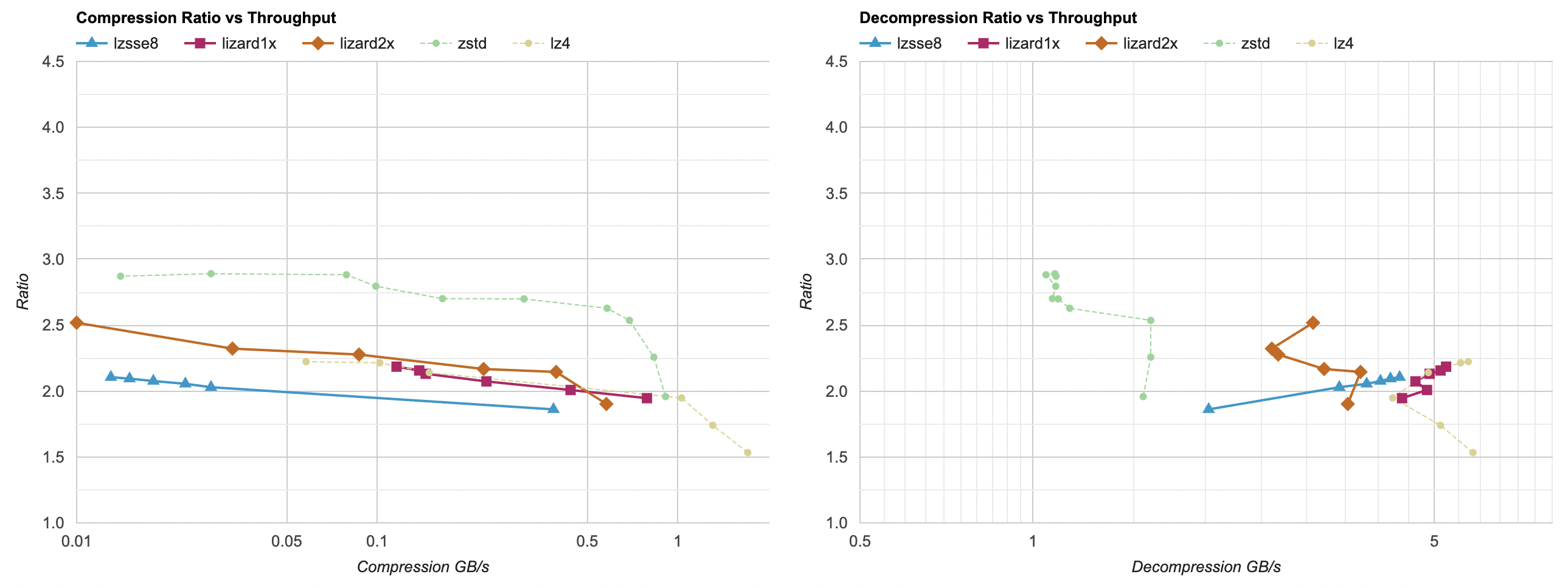
For LZSSE I have tested LZSSE8 variant, since that’s what readme tells to generally use. “Zero” compression level here is the “fast” compressor; other levels are the “optimal” compressor. Compression levels beyond 5 seem to not buy much ratio, but get much slower to compress. On this machine, on this data set, it does not look competetive - compression ratio is very similar to LZ4; decompression a bit slower, compression a lot slower.
For Lizard (née LZ5), it really is like four different compression algorithms in there
(fastLZ4, LIZv1, fastLZ4 + Huffman, LIZv1 + Huffman). I have not tested the Huffman variants since they can not co-exist with Zstd
in the same build easily (symbol redefinitions). The fastLZ4 is shown as lizard1x here, and LIZv1 is shown as lizard2x.
lizard1x (i.e. Lizard compression levels 10..19) seems to be pretty much the same as LZ4. Maybe it was faster than LZ4 back in
2019, but since then LZ4 gained some performance improvements?
lizard2x is interesting - better compression ratio than LZ4, a bit slower decompression speed. In the middle between Zstd and LZ4
when it comes to decompression parameter space.
What about Mac?
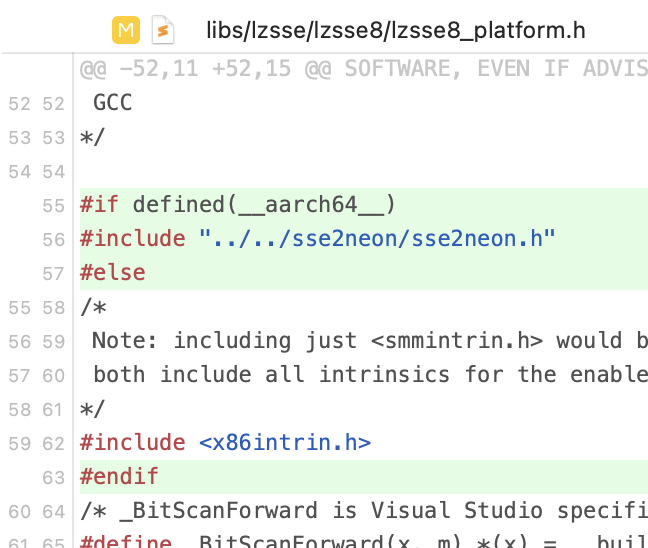 The above charts are on x64 architecture, and Visual Studio compiler. How about a Mac (with a Clang compiler)? But first, we need
to get LZSSE working there, since it is very much written with raw SSE4.1 intrinsics and no fallback or other platform paths.
Luckily, just dropping a sse2neon.h into the project and doing a
tiny change in LZSSE source make it just work on an Apple M1 platform.
The above charts are on x64 architecture, and Visual Studio compiler. How about a Mac (with a Clang compiler)? But first, we need
to get LZSSE working there, since it is very much written with raw SSE4.1 intrinsics and no fallback or other platform paths.
Luckily, just dropping a sse2neon.h into the project and doing a
tiny change in LZSSE source make it just work on an Apple M1 platform.
With that out of the way, here’s the chart on Apple M1 Max with Clang 14:
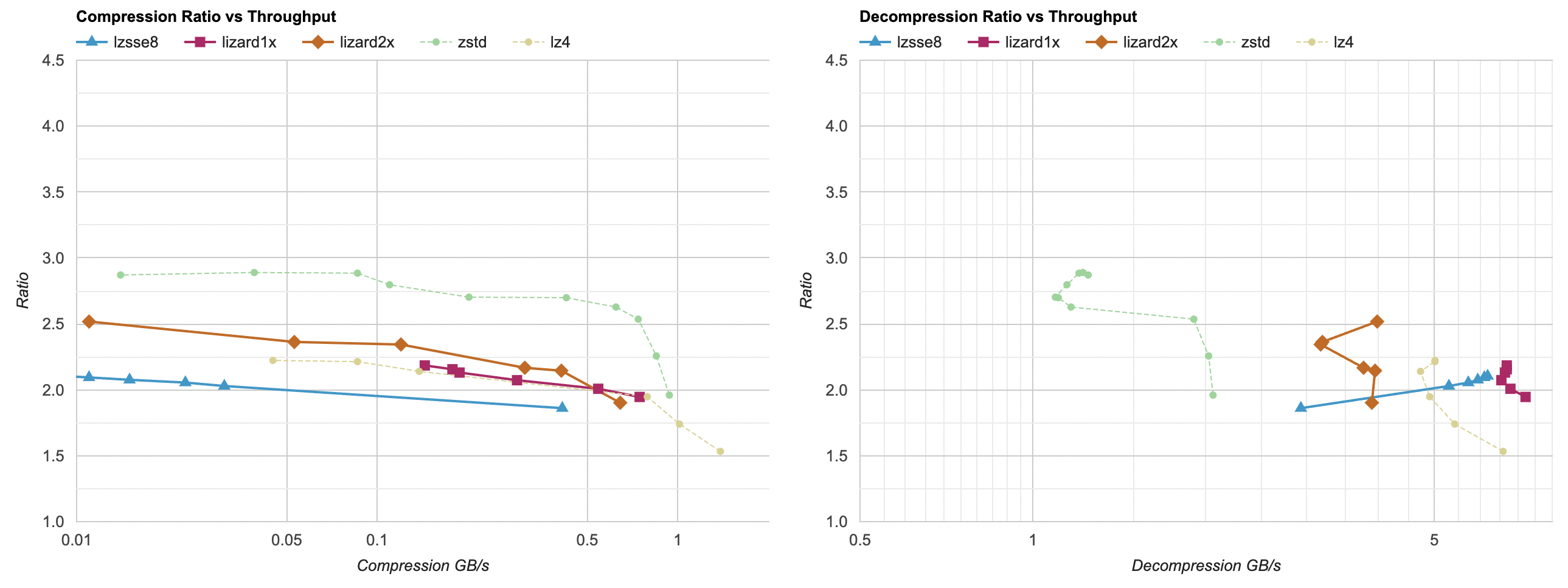
Here lzsse8 and lizard1x do get ahead of LZ4 in terms of decompression performance. lizard1x is about 40% faster than LZ4 at
decompression at the same compression ratio. LZSSE is “a bit” faster (but compression performance is still a lot slower than LZ4).
LZSSE and Lizard, with data filtering and chunking
If there’s anything we’ve learned so far in this whole series, is that “filtering” the data before compression can increase the compression ratio a lot (which in turn can speed up both compression and decompression due to data being easier or smaller). So let’s do that!
Windows case, all compressors with “split bytes, delta” filter from part 7,
and each 1MB block is compressed independently (see part 8):
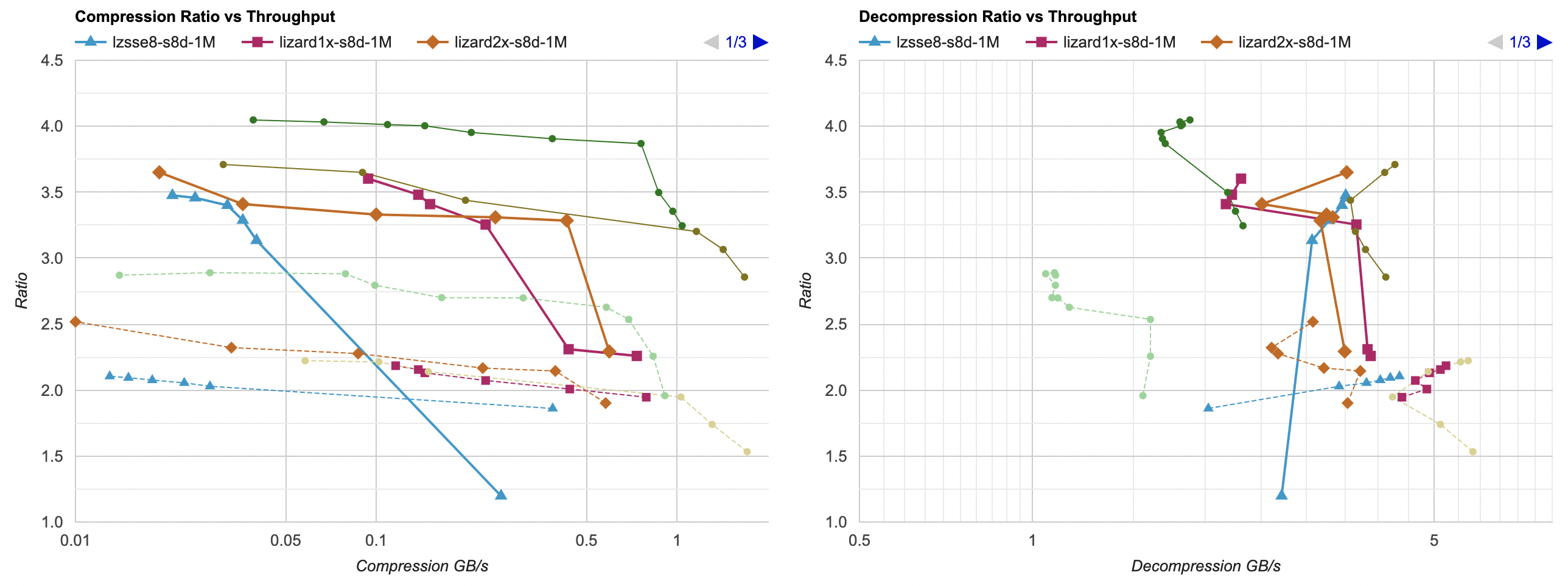
Well, neither LZSSE nor Lizard are very good here – LZ4 with filtering is faster than either of them, with a slightly better compression ratio too. If you’d want higher compression ratio, you’d reach for filtered Zstd.
On a Mac things are a bit more interesting for lzsse8 case; it can get ahead of filtered LZ4 decompression performance at expense of some
compression ratio loss:
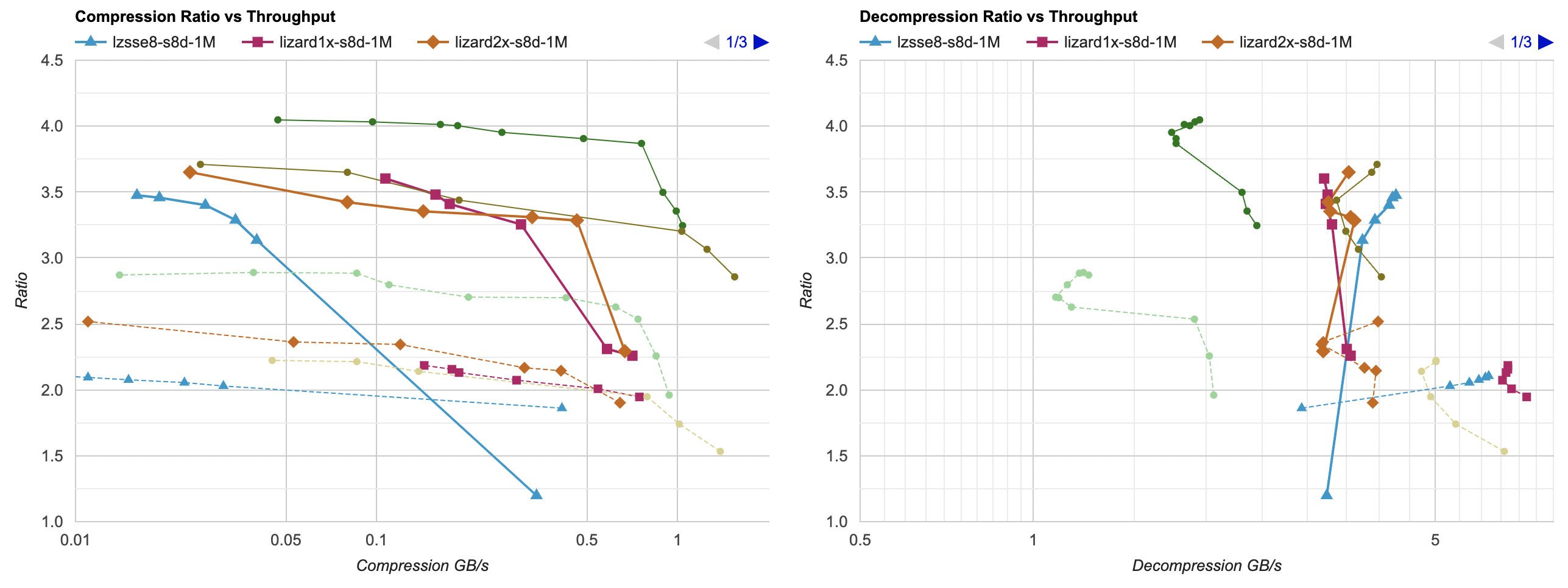
I have also tested on Windows (same Ryzen 5950X) but using Clang 15 compiler. Neither LZSSE nor Lizard are on the Pareto frontier here:
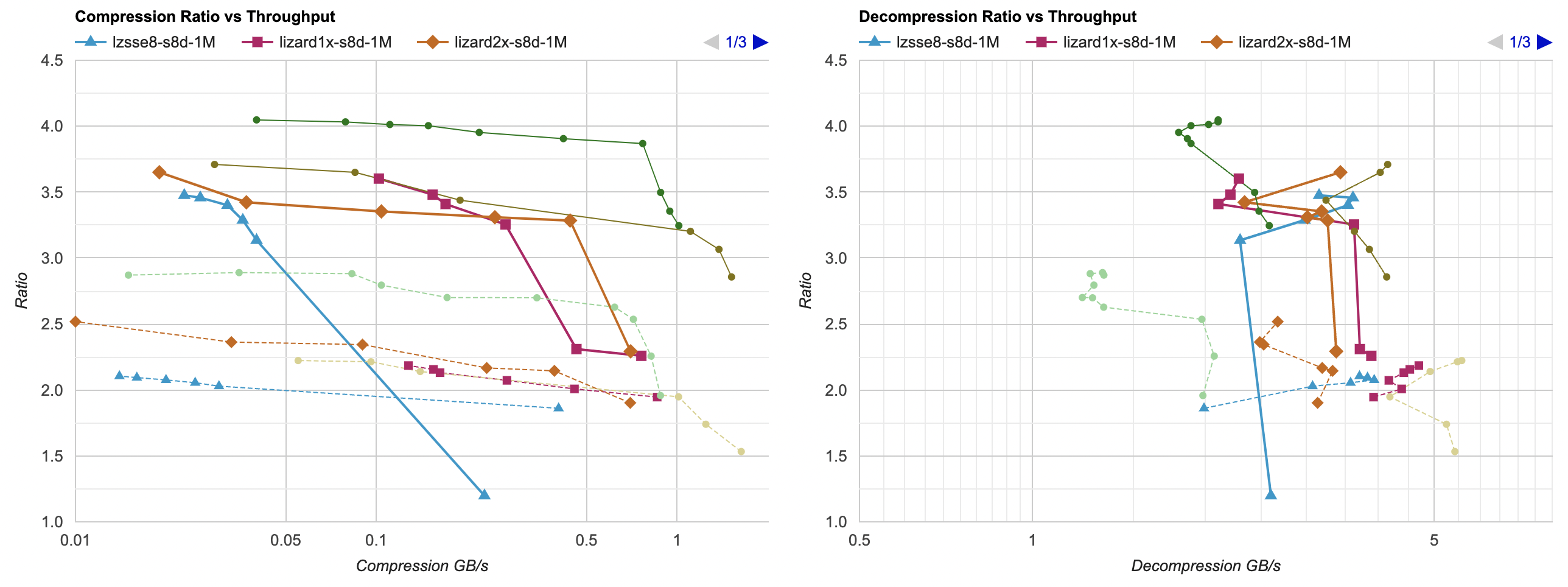
Conclusions
On my data set, neither LZSSE nor Lizard are much competetive against (filtered or unfiltered) LZ4 or Zstd. They might have been several years ago when they were developed, but since then both LZ4 and Zstd got several speedup optimizations.
Lizard levels 10-19, without any data filtering, do get ahead of LZ4 in decompression performance, but only on Apple M1.
LZSSE is “basically LZ4” in terms of decompression performance, but the compressor is much slower (fair, the project says as much in the readme). Curiously enough, where LZSSE gets ahead of LZ4 is on an Apple M1, a platform it is not even supposed to work on outside the box :)
Maybe next time I’ll finally look at lossy floating point compression. Who knows!