Float Compression 4: Mesh Optimizer
Introduction and index of this series is here.
The previous post investigated some lossless filtering of data, before passing it to a regular compression library. Our result so far is: 94.5MB of data can get filtered+compressed down to 23.0MB in one second (split/shuffle bytes, delta encode, zstd or kraken compression). It decompresses back in about 0.15 seconds (which quite a bit slower than without data filtering, but that’s something for later day).
In this post, I’ll look at one open source library that does not feel like it would immediately be suitable for compressing my data set.
zeux/meshoptimizer
meshoptimizer by Arseny Kapoulkine is a very nice library for processing, optimizing, and compressing 3D model (“mesh”) data. It can do vertex and index reordering for efficiency of various GPU caches, mesh simplification, quantization and conversion of the vertex data, has index and vertex data compression utilities, and various tools to do all that on glTF2 geometry files.
Notice the “vertex data compression utilities” bit? We’re going to try that one. Since the meshoptimizer compression is an official glTF extension, there’s a specification for it even (EXT_meshopt_compression).
It’s not immediately obvious that it can also be used for anything else than actual 3D model vertex data compression. But look at it:
- It is completely lossless,
- It takes “size of each vertex in bytes” and “number of vertices” as an input. But who says these need to be vertices? It’s just some data.
- It assumes that there is some correllation / smoothness between neighboring vertices; that’s how it gets compression after all. We don’t have “vertices”, but our “data items” from water or snow simulation are nicely laid out in memory one after another, and their values do vary fairly smoothly.
In our case, water, snow simulation and float4 data files are all going to be “yeah, we are totally 16-byte vertices”, and the float3
data file is going to be “I’m full of 12-byte vertices, really”. And then we just use meshopt_encodeVertexBufferBound, meshopt_encodeVertexBuffer
and meshopt_decodeVertexBuffer functions from the library.
So does it work?
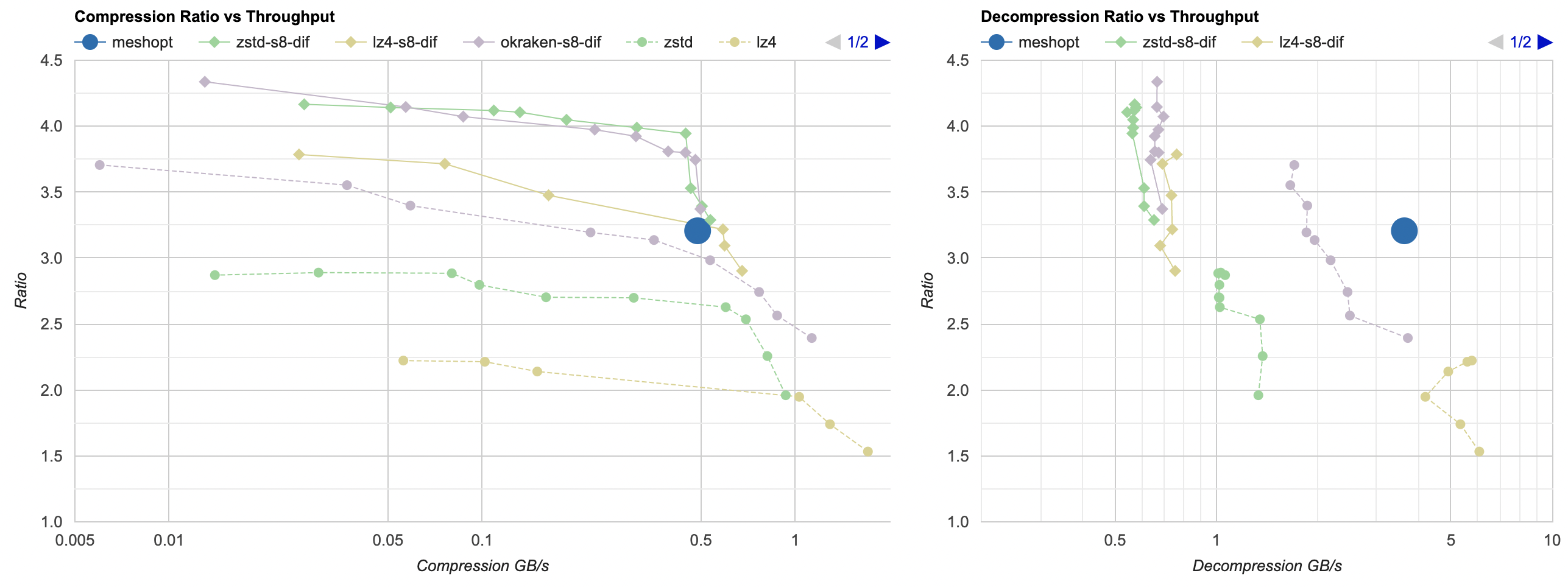
The chart here shows our three regular compressors (zstd, lz4, kraken; dashed lines), as well as the same compressors with best filtering from previous post (solid lines). meshoptimizer is the large blue point, since it has no “compression levels” to speak of.
This is actually pretty impressive!
- Really fast to compress (0.2 seconds), and really fast to decompress (3.5GB/s, almost at lz4 speeds).
- For a “compress in under a second” task, it beats zstd on ratio, and achieves the same ratio as Oodle Kraken. 😮 We have a 29.5MB file.
- It does not quite achieve the compression ratio of regular compressors with filtering applied. But hey, we are mis-using “mesh” optimizer library for data that is almost certainly not meshes :)
Oh but hey, meshoptimizer readme says:
The result of the encoding is generally significantly smaller than initial data, and remains compressible with general purpose compressors
So let’s try just that: compress our data with meshoptimizer, and then try adding our old friends zstd/lz4/kraken on top of that.
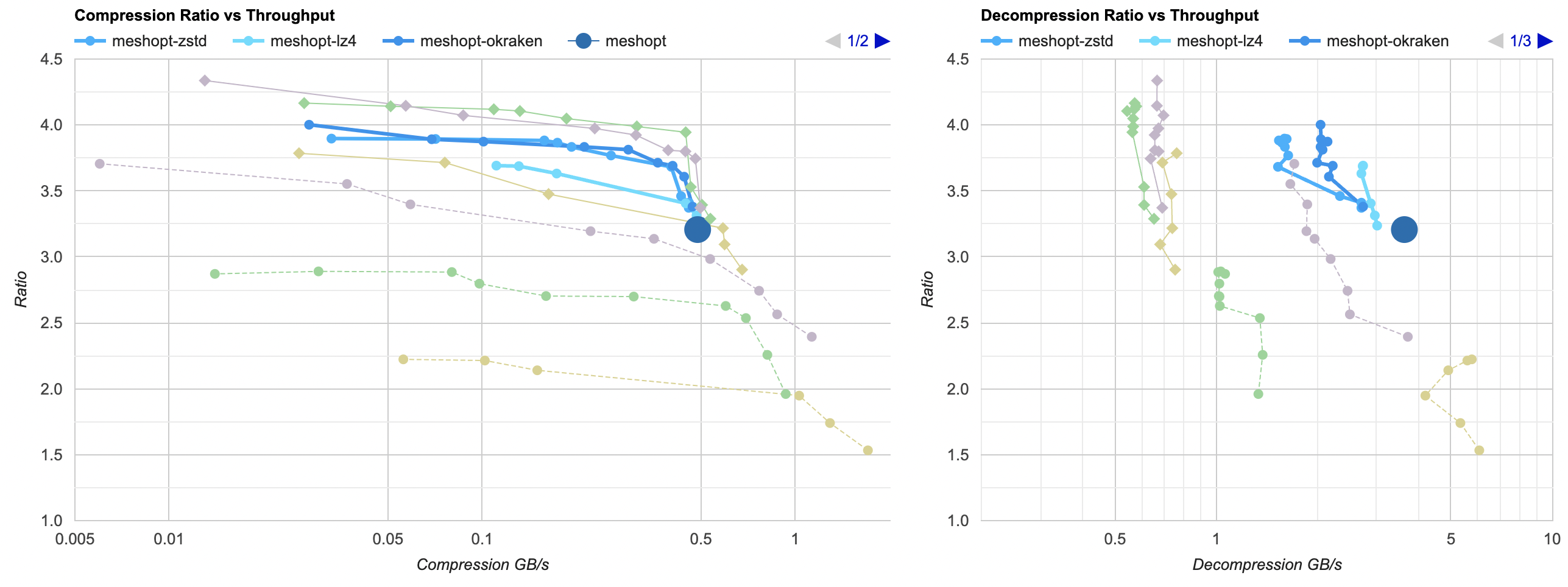
- For compression under one second, this now achieves 24.4MB file size. Nice!
- Kraken and zstd are almost the same performance and ratio here.
- Still not as small as filtering + regular compression (which gets down to 23.0MB), but pretty close.
- Decompression is still very fast; 3x faster than with filtering + regular decompression. Nice!
I have also tried various filtering approaches before doing mesh optimizer compression (split floats, split bytes, delta, xor, rotate floats left by one bit, etc.). And these do not actually help; often making compression ratio worse. This makes sense; mesh optimizer vertex compression codec has a lot of similarities to a data filter itself, so additional filtering just gets in the way and “confuses” it. Or that’s my impression.
Conclusion and what’s next
My takeaway is that if you have structured data that is mostly floating point and inherently has some similarities / smoothness across it, then you should take a look at using meshoptimizer vertex compression codec. Even if your data is not meshes at all!
It makes the data smaller by itself, but you can also pass that down into any other regular data compression library for further compression.
And it’s really fast at both compression and decompression. There’s a pure-JavaScript version too in there, if you’re targeting the web platform.
Next up, I’ll look into several libraries specifically targeted at floating point data compression, that are mostly coming from the scientific community. And then after that, maybe at lossy compression.