Float Compression 1: Generic
Introduction and index of this series is here.
We have 94.5MB worth of data, and we want to make it smaller. About the easiest thing to do: use one of existing lossless data compression libraries, or as us old people call it, “zip it up”.
There are tons of compression libraries out there, I certainly will not test all of them (there’s lzbench and others for that). I tried some popular ones: zlib, lz4, zstd and brotli.
Here are the results (click for an interactive chart):
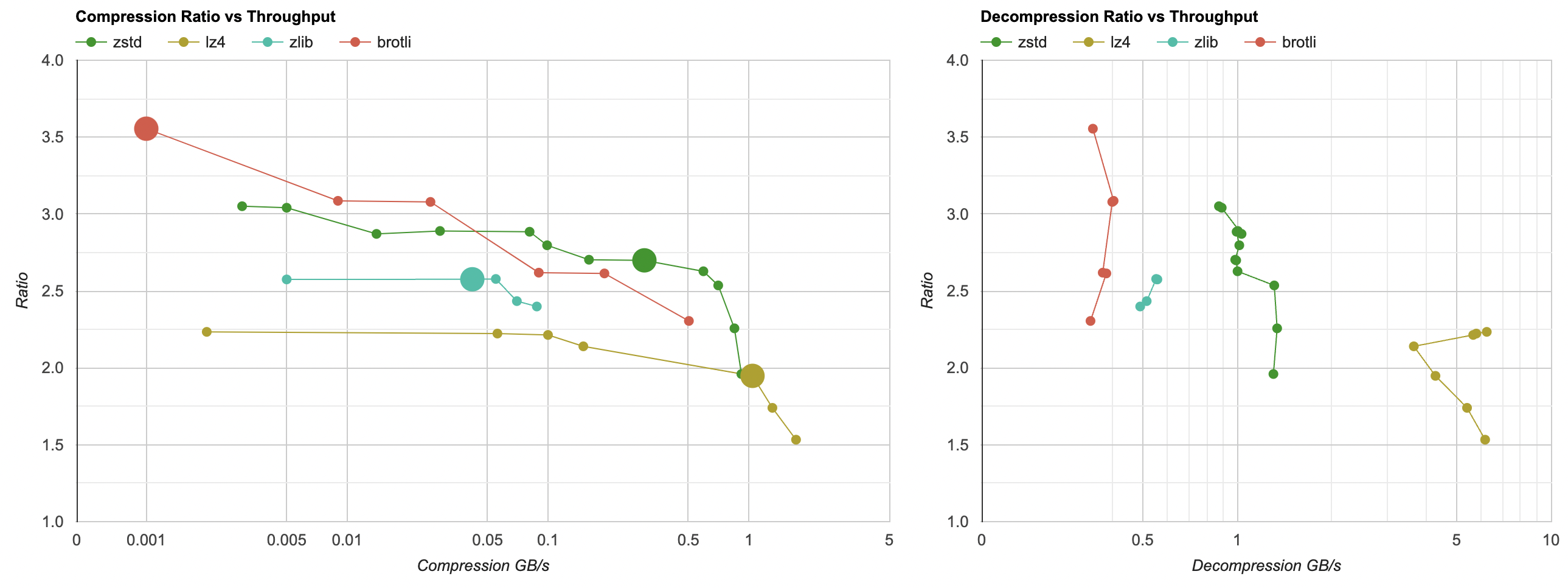
This is running on Windows, AMD Ryzen 5950X, compiled with Visual Studio 2022 (17.4), x64 Release build. Each of the four data files is compressed independently one after another, serially on a single thread.
I also have results on the same Windows machine, compiled with Clang 15, and on an Apple M1 Max, compiled with Clang 14.
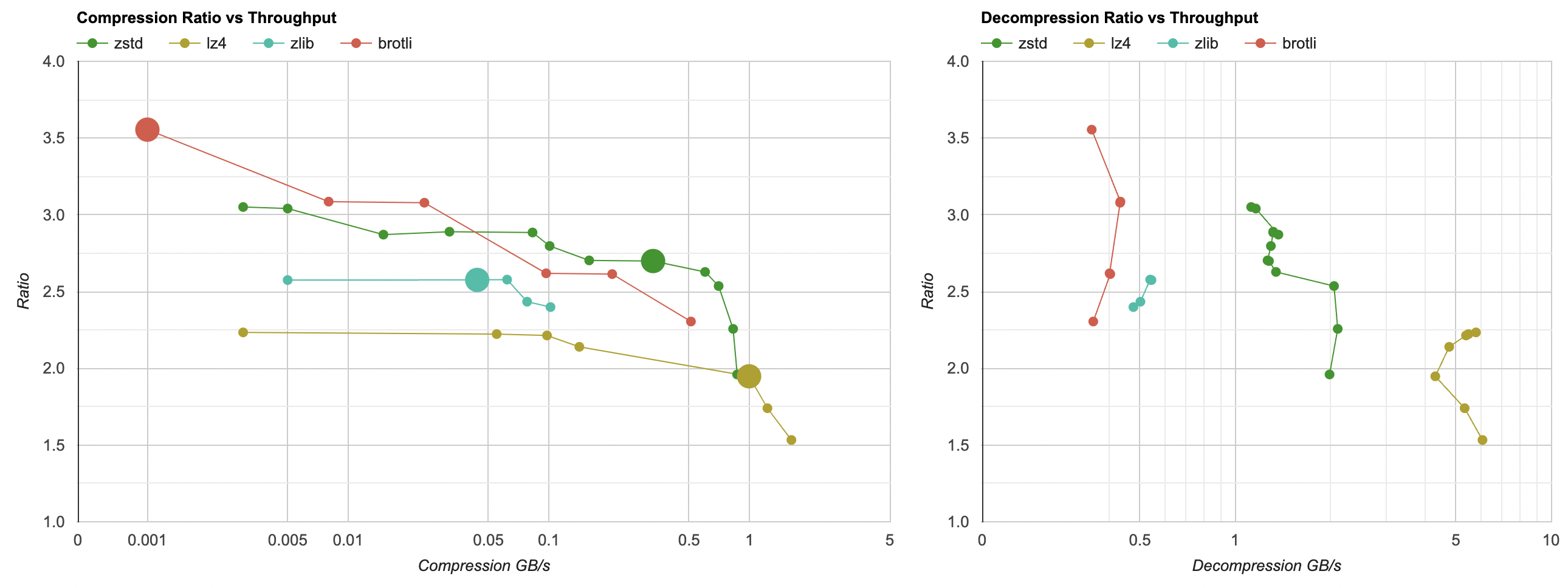
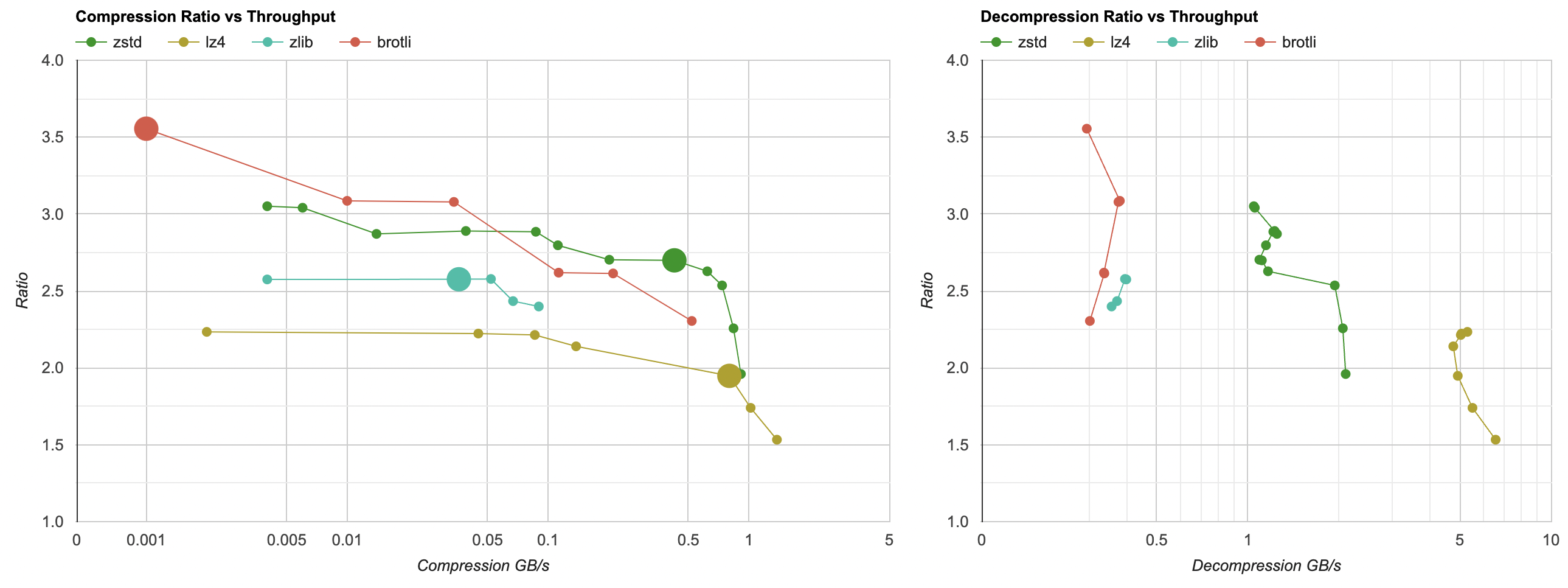
What can we see from this?
The compression charts have compression ratio (higher = better) on the vertical axis, and throughput on the horizontal axis (higher = better). Note that the horizontal axis is logarithmic scale; performance of the rightmost point is literally hundreds of times faster than the leftmost point. Each line on the graph is one compression library, with different settings that it provides (usually called “compression levels”).
Compression graph is the usual “Pareto front” situation - the more towards upper right a point is, the better (higher compression ratio, and better performance). The larger points on each compression curve are the “default” levels of each library (6 for zlib, 3 for zstd, “simple” for lz4).
Decompression graph, as is typical for many data compression algorithms, is much less interesting. Often decompression performance is more or less the same when using the same compression library; no matter what the compression level is. You can ballpark and say “lz4 decompresses at around 5GB/s” for this data set.
Anyway, some takeaway points:
- Generic data compression libraries can get this data set from 94.5MB down to 32-48MB, i.e. make it 2x-3x smaller.
- They would take between 0.1s and 1.0s to compress the data, and between 0.02s and 0.2s to decompress it.
- With Brotli maximum level (11), you can go as low as 27MB data (3.5x ratio), but it takes over two minutes to compress it :/
- zstd is better than zlib in all aspects. You can get the same compression ratio, while compressing 10x faster; or spend same time compressing,
and get better ratio (e.g. 2.6x -> 2.9x). Decompression is at least 2x faster too.
- Current version of zstd (1.5.2, 2022 Jan) has some dedicated decompression code paths written in assembly, that are only used when compiling with clang/gcc compilers. On a Microsoft platform you might want to look into using Clang to compile it; decompression goes from around 1GB/s up to 2GB/s! Or… someone could contribute MSVC compatible assembly routines to zstd project :)
- If you need decompression faster than 2GB/s, use lz4, which goes at around 5GB/s. While zstd at level -5 is roughly the same compression ratio and compression performance as lz4, the decompression is still quite a bit slower. lz4 does not reach more than 2.2x compression ratio on this data set though.
- If you need best compression ratio out of these four, then brotli can do that, but compression will not be fast. Decompression will not be fast either; curiously brotli is slower to decompress than even zlib.
- There’s basically no reason to use zlib, except for the reason that it likely exists everywhere due to its age.
Which place exactly on the Pareto front is important to you, depends on your use case:
- If compression happens once on some server, and the result is used thousands/millions of times, then you much more care about compression ratio, and not so much about compression performance. A library like brotli seems to be targeted at exact this use case.
- On the completely opposite side, you might want to “stream” some data exactly once, for example some realtime application sending profiling data for realtime viewing. You are compressing it once, and decompressing it once, and all you care about is whether the overhead of compression/decompression saves enough space to transmit it faster. lz4 is primarily targeted at use cases like this.
- If your scenario is similar to a “game save”, then for each compression (“save”), there’s probably a handful of decompressions (“load”) expected. You care both about compression performance, and about decompression performance. Smaller file like with brotli level 11 would be nice, but if it means almost three minutes of user waiting (as opposed to “one second”), then that’s no good.
My use case here is similar to a “game save”; as in if compressing this data set takes longer than one or two seconds then it’s not acceptable. Later posts will keep this in mind, and I will not even explore the “slow” compression approaches much.
In general, know your use case! And don’t just blindly use “maximum” compression level; in many libraries it does not buy you much, but compression becomes much, much slower (brotli here seems to be an exception - while compression is definitely much slower, going from level 10 to the maximum level 11 does increase compression ratio quite a bit).
What’s next?
Next up, we’ll look at some simple data filtering (i.e. fairly similar to EXR post from a while ago)
a couple more generic data compressors. Until then!