Comparing .obj parse libraries
Wavefront .obj file format is a funny one. Similar to GIF, it’s a format from the 1990s, that absolutely should not be widely used anymore, yet it refuses to go away. Part of the appeal of OBJ is relative simplicity, I guess.
In the previous blog post I asked myself a question, “is this new Blender OBJ parsing code even good?” Which means, time to compare it with some other existing libraries for parsing Wavefront OBJ files.
OBJ parsing libraries
There’s probably a thousand of them out there, of various states of quality, maintenance, feature set, performance, etc. I’m going to focus on the ones written in C/C++ that I’m aware about. Here they are, along with the versions that I’ve used:
| Library | Version | License |
|---|---|---|
| tinyobjloader | 2021 Dec 27 (8322e00a), v1.0.6+ | MIT |
| fast_obj | 2022 Jan 29 (85778da5), v1.2+ | MIT |
| rapidobj | 2022 Jun 18 (0e545f1), v0.9 | MIT |
| blender | 2022 Jun 19 (9757b4ef), v3.3a | GPL v3 |
| assimp | 2022 May 10 (ff43768d), v5.2.3+ | BSD 3-clause |
| openscenegraph | 2022 Apr 7 (68340324), v3.6.5+ | LGPL-based |
Some notes:
blenderis not a “library” that you can really use without the rest of Blender codebase.- In the performance comparisons below there will also be a
tinyobjloader_opt, which is the multi-threaded loader fromtinyobjloader“experimental” folder. openscenegraphwill be shortened toosgbelow.
Let’s have a quick overview of the feature sets of all these libraries:
| Feature | tinyobjloader | fast_obj | rapidobj | blender | assimp | osg |
|---|---|---|---|---|---|---|
| Base meshes | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Base materials | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| PBR materials | ✓ | ✓ | ✓ | |||
| Vertex colors (xyzrgb) | ✓ | ✓ | ✓ | ✓ | ||
| Vertex colors (MRGB) | ✓ | ✓ | ||||
Lines (l) |
✓ | ✓ | ✓ | ✓ | ✓ | |
Points (p) |
✓ | ✓ | ✓ | |||
Curves (curv) |
✓* | |||||
2D Curves (curv2) |
||||||
Surfaces (surf) |
||||||
Skin weights (vw) |
✓ | |||||
Subdiv crease tags (t) |
✓ | |||||
Line continuations (\) |
✓ | ✓ | ✓ | |||
| Produces GPU-ready data | ✓ | |||||
| Language / Compiler | C++03 | C89 | C++17 | C++17 | C++??* | C++??* |
- Blender OBJ parser has only limited support for curves: only
bsplinecurve type is supported. - It’s not clear to me which version of C++
assimprequires. It’s also different from all the other libraries, in that it does not return you the “raw data”, but rather creates “ready to be used for the GPU” mesh representation. Which might be what you want, or not what you want. osgOBJ parser does not compile under C++17 out of the box (uses features removed in C++17), I had to slightly modify it.
As you can see, even if “base” functionality of OBJ/MTL is fairly simple and supported by all the parsing libraries, some more exotic features or extensions are not supported by all of them, or even not supported by any of them.
Some libraries also differ in how they handle/interpret the more under-specified parts of the format. OBJ is a file format without any “official” specification; all it ever had was more like a “readme” style document. It’s funny that more modern alternatives, like Alembic or USD also don’t really have their specifications - they are both “here’s a giant code library and some docs, have fun”.
Test setup
I’m going to test the libraries on several files:
rungholt: “Rungholt” Minecraft map from McGuire Computer Graphics Archive. 270MB file, 2.5M vertices, 1 object with 84 materials.splash: Blender 3.0 splash screen ("sprite fright"). 2.5GB file, 14.4M vertices, 24 thousand objects.


Test numbers are from a Windows PC (AMD Ryzen 5950X, Windows 10, Visual Studio 2022) and a Mac laptop (M1 Max, macOS 12.3, clang 13). “Release” build configuration is used. Times are in seconds, memory usages in megabytes.
All the code I used is in a git repository. Nothing fancy really, just loads some files using all the libraries above and measures time. I have not included the large obj files into the git repo itself though.
Performance
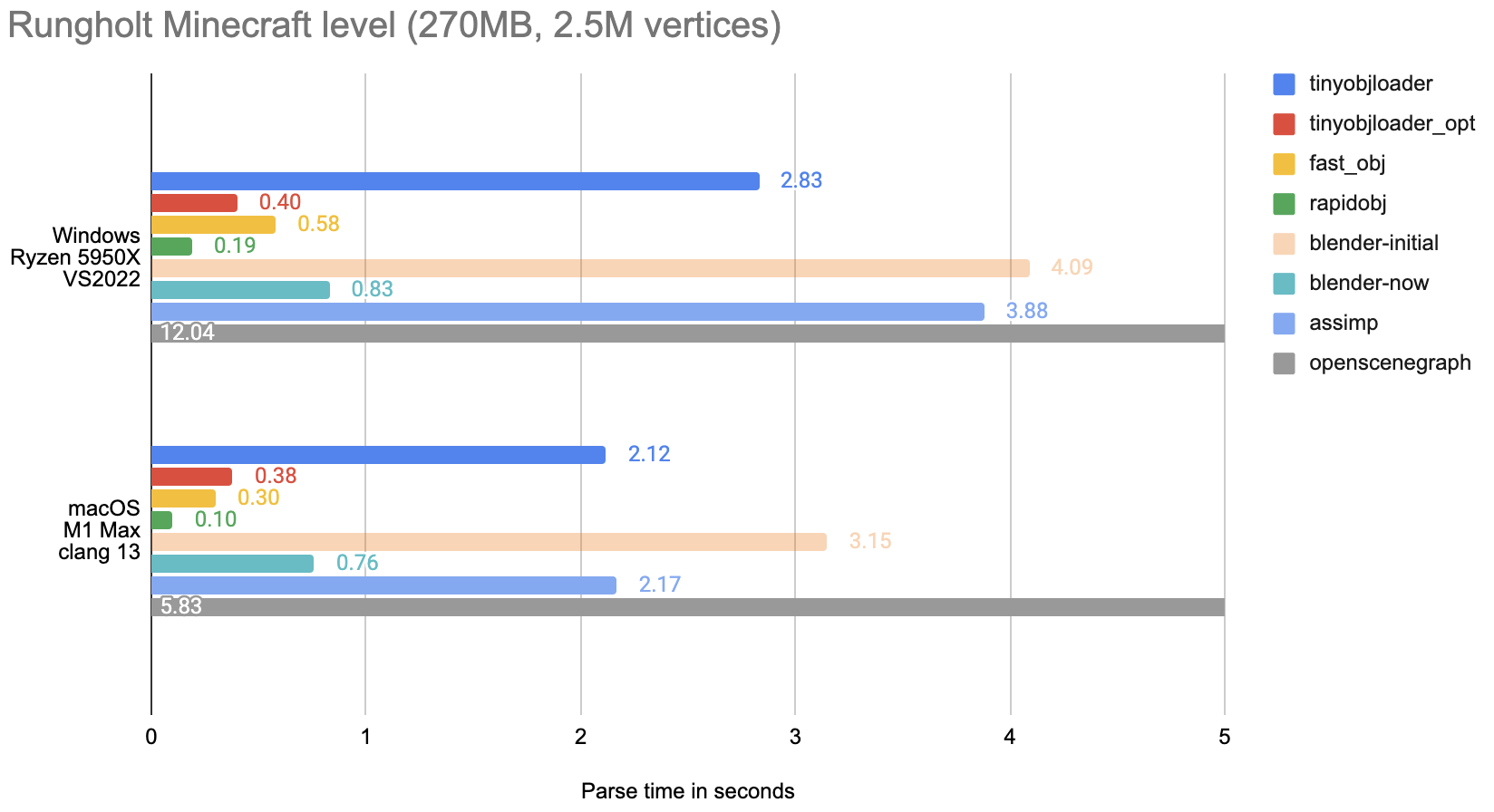
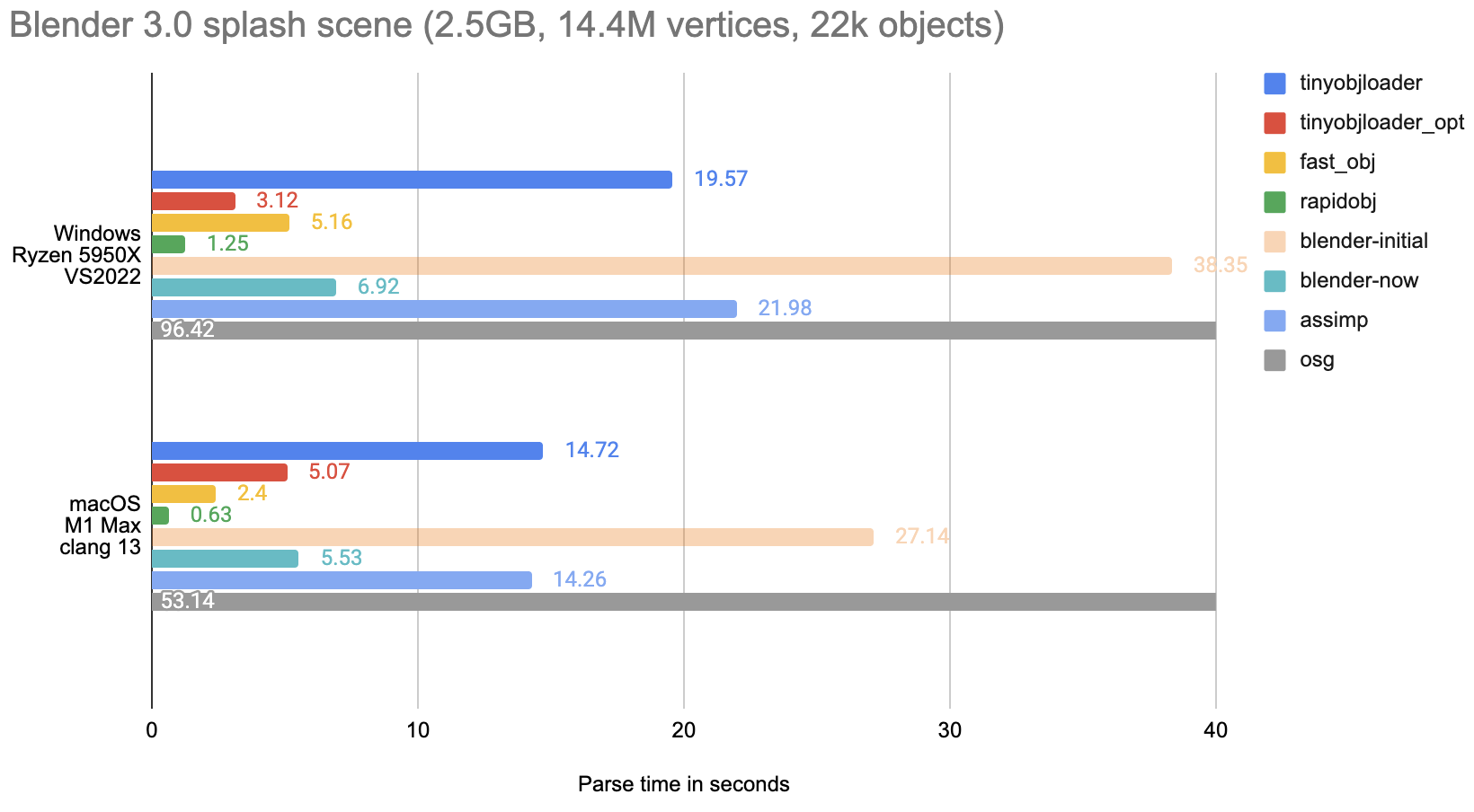
Look at that – even if all the parsing libraries are written in “the same” programming language, there is up to 70 times performance difference between them. For something as simple as an OBJ file format!
Note that I clipped the horizontal part of the graph, or otherwise the
openscenegraphline length would make hard to see all the others :)
Random observations and conclusions:
rapidobjis the performance winner here. On the technical level, it’s the most “advanced” out of all of them – it uses asynchronous file reading and multi-threaded parsing.However, it does not support macOS(update: rapidobj 0.9 added macOS support!). It also requires a fairly recent C++ compiler (C++17) support.fast_objis the fastest single-threaded parser. It also compiles pretty much anywhere (any C compiler would do), but also has the least amount of features. However I could make it crash on syntax it does not support (\line continuation); it might be the least robust of the parsers.tinyobjloader_opt, which is the multi-threaded experimental version oftinyobjloader, is quite fast. However, it very much feels “experimental” – it has a different API than the regulartinyobjloader, is missing some parameters/arguments for it to be able to find.mtlfiles if they are not in the current folder, and also see below for the memory usage.blenderis not the fastest, but “not too bad, eh”, especially among the single threaded ones. The difference betweenblender-initialandblender-nowis what I’ve described in the previous post.assimpis not fast. Which is by design – their website explicitly says “The library is not designed for speed”. It also does more work than strictly necessary – while all the others just return raw data, this one creates a “renderable mesh” data structure instead.tinyobjloader, which feels like it’s the default go-to choice for people who want to use an OBJ parser from C++, is actually not that fast! It is one of the more fully featured ones, though, and indeed very simple to use.osgis just… Well, it did not fit into the graphs on the horizontal axis, nothing more to say :)
Memory usage
Memory usage on Windows, both peak usage, and what is used after all the parsing is done.
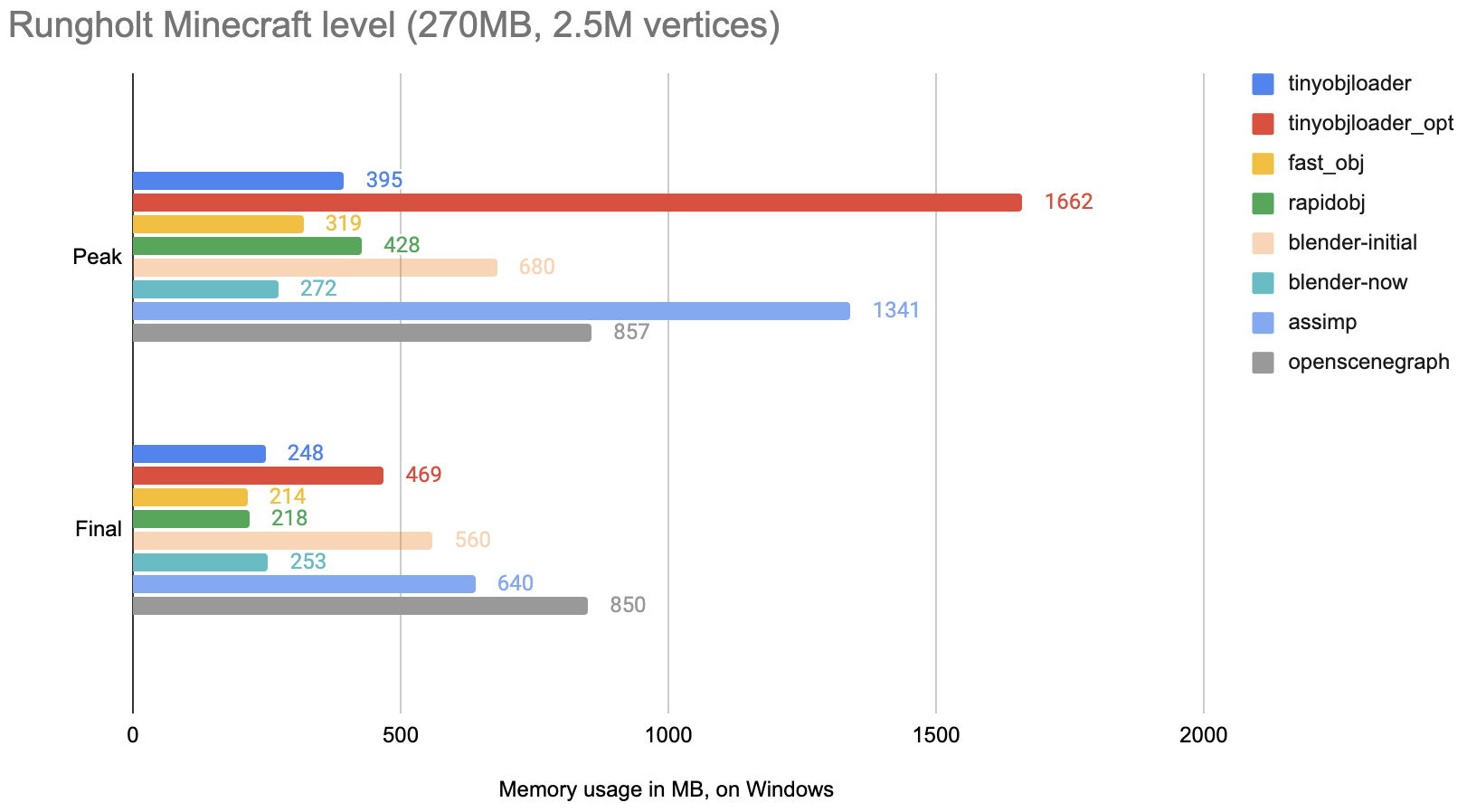
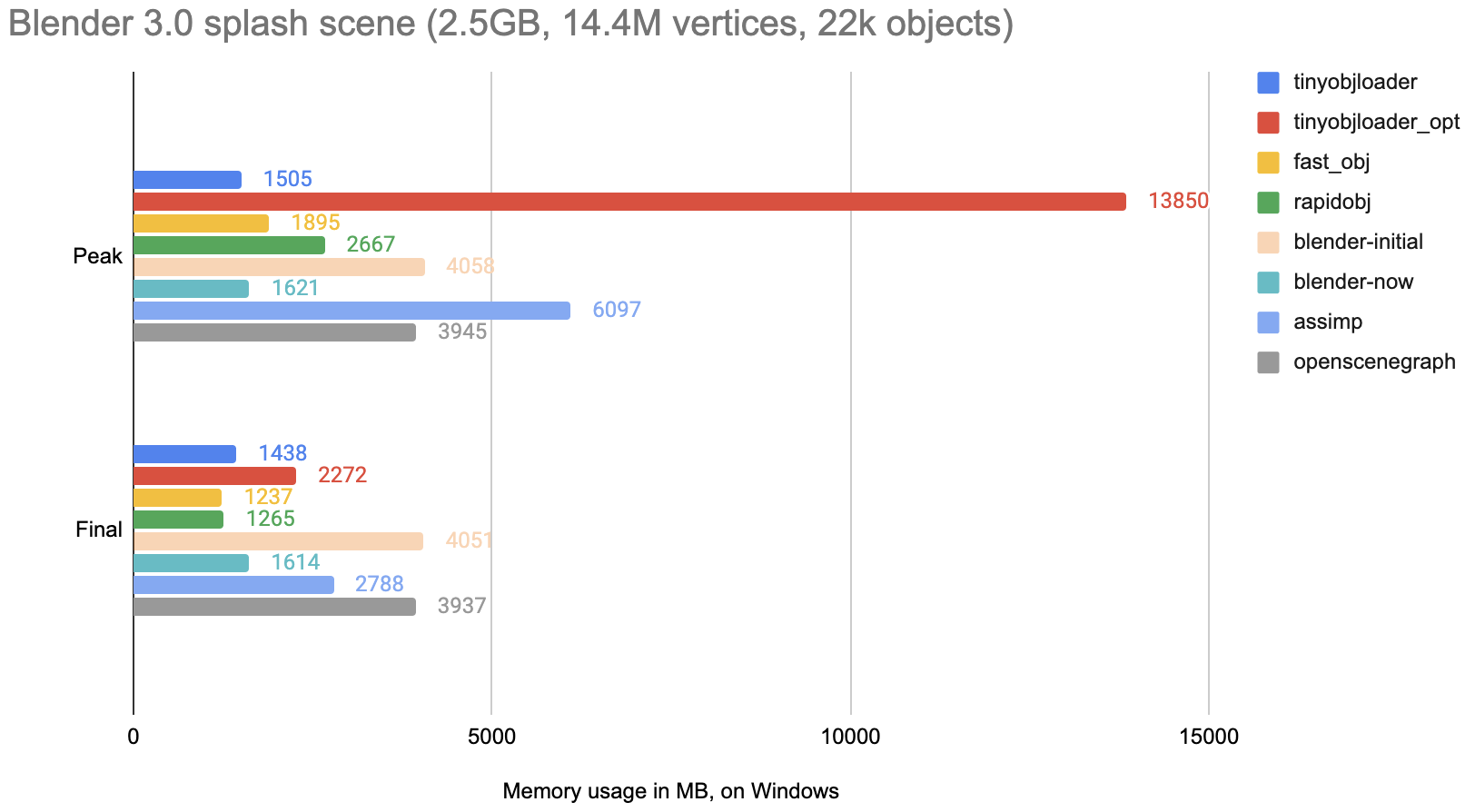
Notes:
tinyobjloader,fast_obj,rapidobj,blenderare all “fine” and not too dissimilar from each other.tinyobjloader_optpeak usage is just bad. For one, it needs to read all the input file into memory, and then adds a whole bunch of “some data” on top of that during parsing. The final memory usage is not great either.assimpandosgmemory consumption is quite bad. So was theblender-initial:)
Wait, how do you multi-thread OBJ parsing?
A whole bunch of things inside an OBJ file are “stateful” - negative face indices are relative to the vertex counts, meaning you need to know all the vertices that came in before; commands like smooth group or material name set the “state” for the following lines, etc. This can feel like it’s not really possible to do the parsing in parallel.
But! Most of the cost of OBJ parsing, besides reading the file, is parsing numbers from a text representation.
What rapidobj and tinyobjloader_opt both do, is split the file contents into decently large “chunks”, parse them in parallel
into “some representation”, and then produce the final data out of the parsed representation. They slightly differ in what’s their
representation, and whether the whole file needs to be first read into memory or not (yes for tinyobjloader_opt, whereas rapidobj
does not need the full file).
In rapidobj case, they only start doing multi-threaded parsing for files larger than 1MB in size, which makes sense – for small
files the overhead of spawning threads would likely not give a benefit. But for giant files it pays off – the cost of converting
text to numbers is much larger than the cost of final data fixup/merge.
Does Blender need a yet faster OBJ parser?
Maybe? But also, at this point OBJ parsing itself is not what’s taking up most of the time. Notice how splash file time is
45 seconds in the previous post, and 7 seconds in this one?
That’s the thing – in order to fully “import” this 2.5GB OBJ file into Blender, right now 7 seconds are spent loading & parsing the OBJ file, and then 38 seconds are doing something with the parsed data, until it’s ready to be used by a user inside Blender. For reference, this “other work” time breakdown is roughly:
- 20 seconds - ensuring that object names are unique. Blender requires objects to have unique names, and the way it’s implemented right now is basically quadratic complexity with the scene object count. Maybe I should finish up some WIP code…
- 10 seconds - assigning materials to the objects. Note, not creating materials, but just assigning them to object material slots. Likely some optimization opportunity there; from a quick look it seems that assigning a material to an object also needs to traverse the whole scene for some reason (wut?).
- 10 seconds - some processing/calculation of normals, after they are assigned from the imported data. I don’t quite understand what it does, but it’s something heavy :)
…anyway, that’s it! Personally I’m quite impressed by rapidobj.