Curious lack of sprintf scaling
Some days ago I noticed that on a Mac, doing snprintf calls from multiple threads shows
curious lack of scaling (see tweet).
Replacing snprintf with {fmt} library can speed up the OBJ exporter
in Blender 3.2 by 3-4 times. This could have been the end of the story, filed under a
“eh, sprintf is bad!” drawer, but I started to wonder why it shows this lack of scaling.
Test case
A simple test: convert two million integers into strings. And then try to do the same on multiple threads at once, i.e. each thread converts two million integers. If the number of threads is below the number of CPU cores, this should take about the same time – each thread would just happily be converting their own numbers, and not interfere with the other threads. That is, a “this scales nicely” result would be where the graph is completely horizontal - no matter how many threads are doing the work at once, it takes the same amount of wall time.
Yes the reality is more complicated, with CPU thermals, shared caches and whatnot coming into play, but we’re interested in broad patterns, not exact science here!
And here’s what happens on an Apple M1 Max laptop. Horizontal axis is thread count; vertical axis
is milliseconds (log scale) taken. Again, a good result would be a horizontal line:
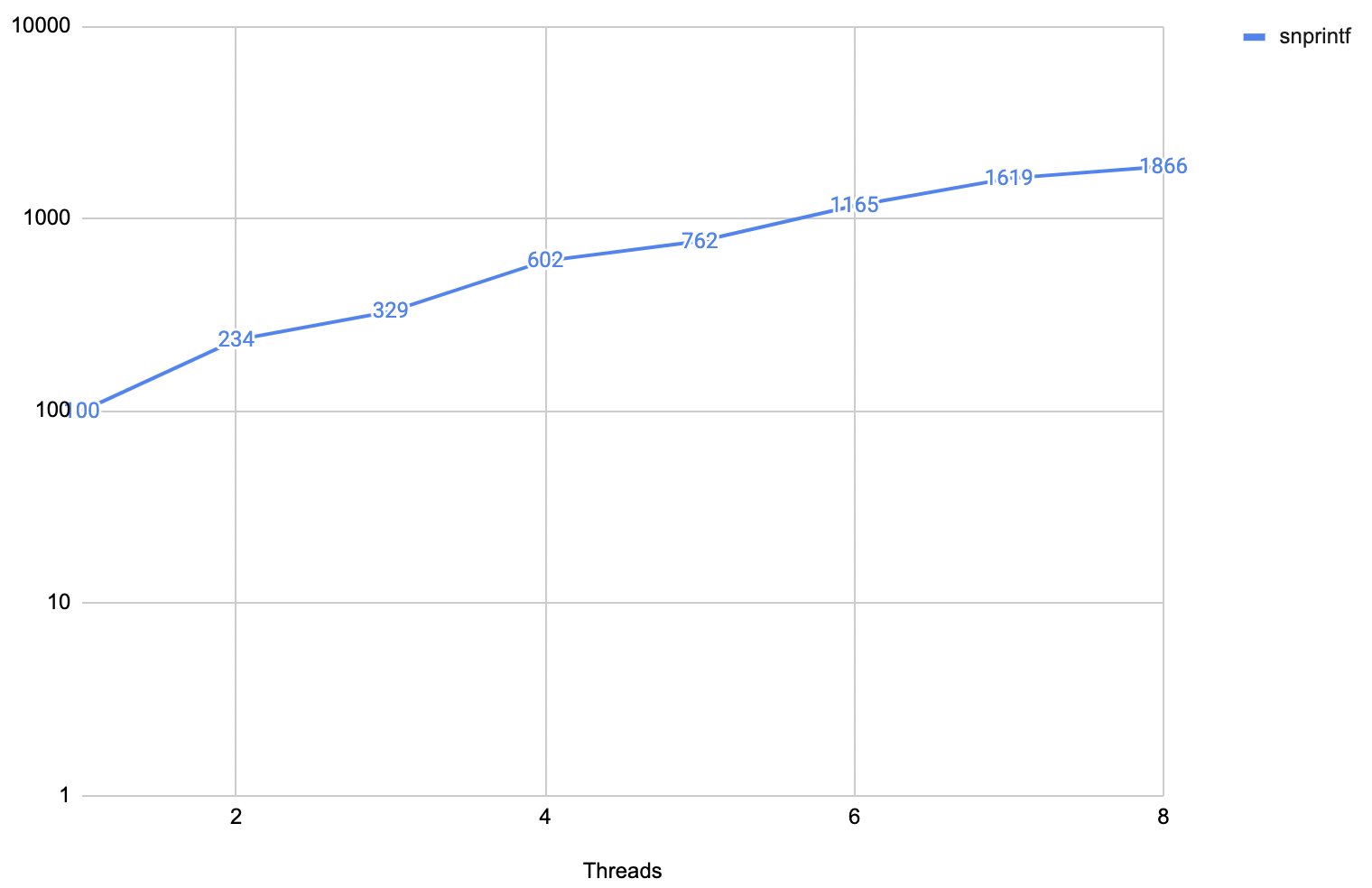
Converting two million numbers into strings takes 100 milliseconds when one CPU core is doing it. When all eight “performance” cores are doing it (i.e. in total 16 million integers), it takes 1.8 seconds, or 18 times as long. That’s, like, not great!
Yo dude, you should not use sprintf
“Well duh” you say, “obviously you should not use sprintf, you should use C++ iostreams”. Okay.
Here’s converting integers into strings via a std::stringstream <<.
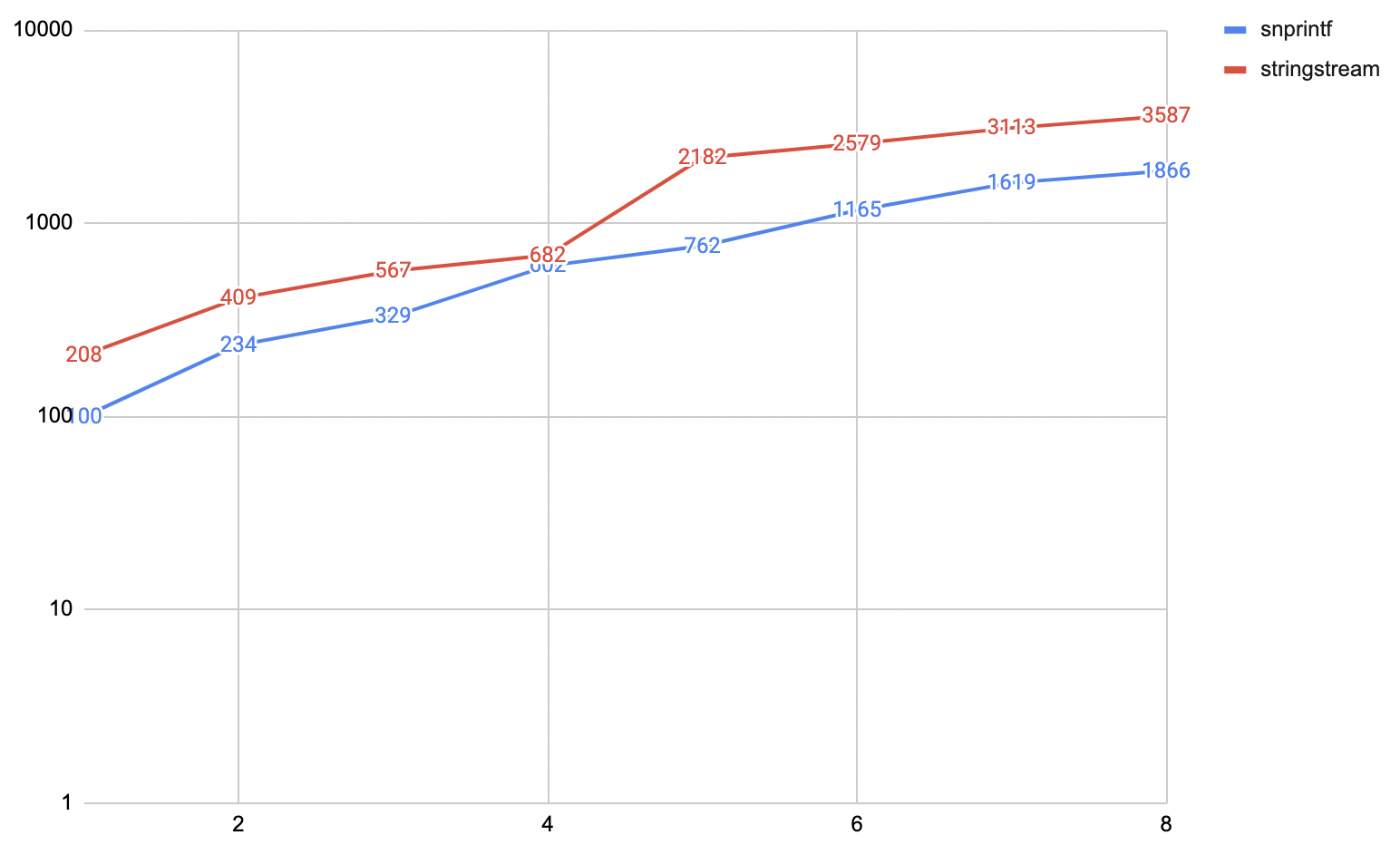
Same scaling issue, except iostreams are two times slower. “Zero cost abstractions”, you know :)
What’s going on?
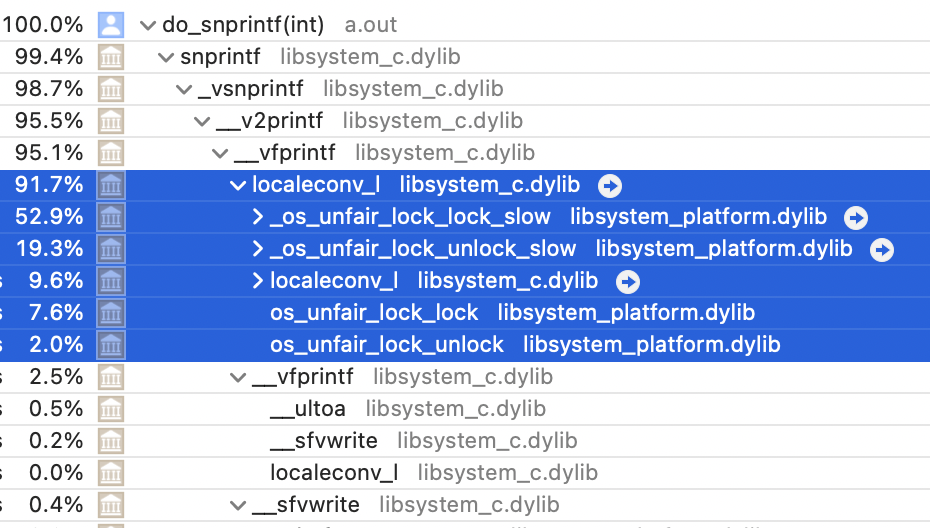
Instruments shows that with 8 threads, each thread spends over 90%
of the time in something called localeconv_l, where it is mostly mutex locks.
At this point you might be thinking, “ah-ha! well this is related to a locale, and a locale is global, so of
course some time spent on some mutex lock is expected”, which is “mmmaybe? but this amount of time feels
excessive?”. Given that this is an Apple operating system, we might know it has a
snprintf_l function
which takes an explicit locale, and hope that this would make it scale. Just pass NULL which means
“use C locale”:
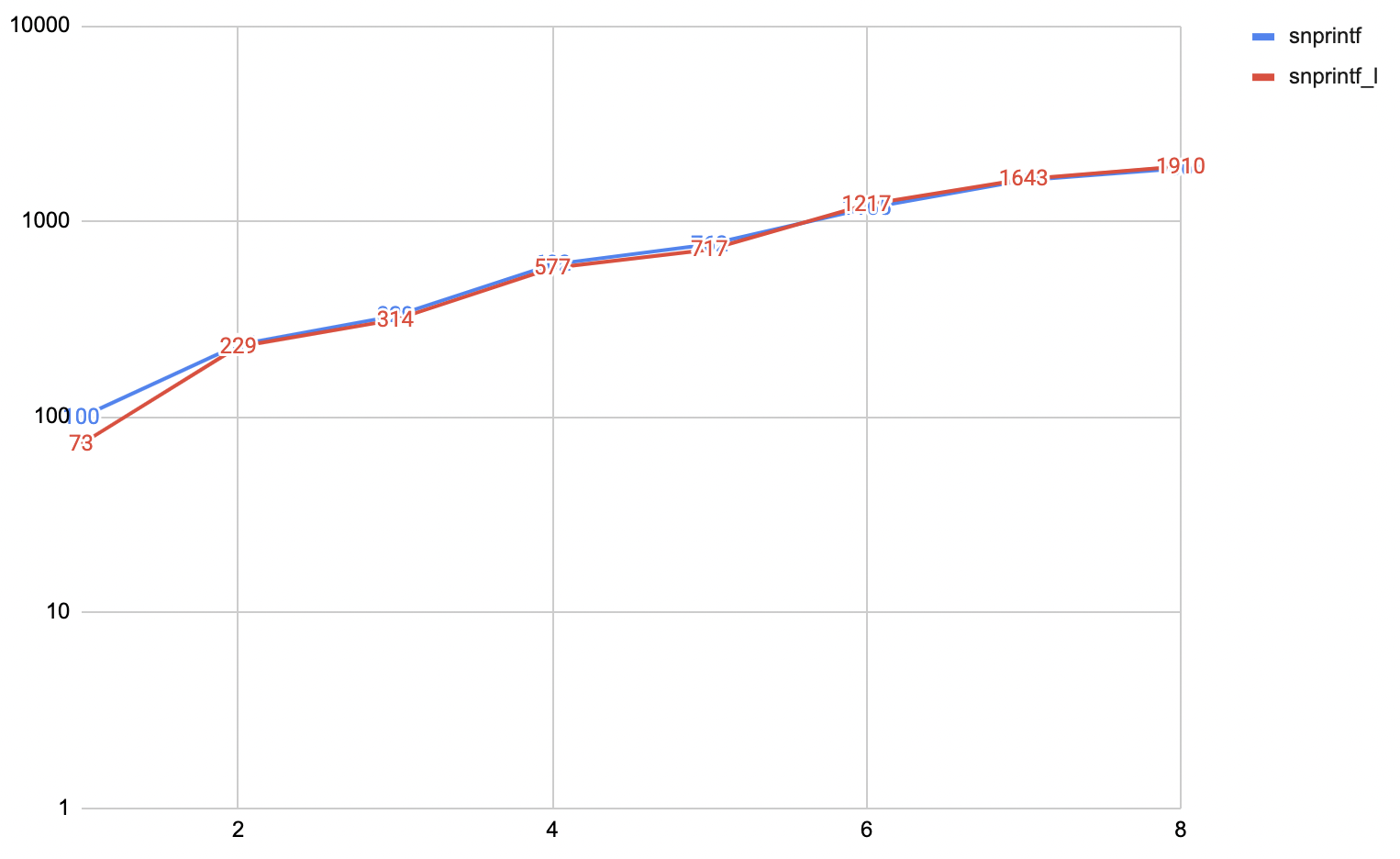
…aaand, nope. It is a tiny bit faster, but does not really address the issue.
But! Large parts of macOS Darwin kernel and system libraries have source code available, so
let’s look at what’s going on. Here’s the latest localeconv_l at the time of writing:
github link.
It’s basically a:
lconv* localeconv_v(locale_t loc)
{
lock_on(loc);
if (loc->something_changed)
{
// do some stuff
}
unlock_on(loc);
// ...
}
and the lock used internally is just a os_unfair_lock macOS primitive. What is curious, is that this code
has very recently changed; before 2022 February
it was like:
lconv* localeconv_v(locale_t loc)
{
if (loc->something_changed)
{
lock_on(loc);
if (loc->something_changed)
{
// do some stuff
}
unlock_on(loc);
}
// ...
}
Which to me feels like the previous code was trying to do a “double checked locking” pattern, but without using actual atomic memory reads. Which probably happens to work just fine on Intel CPUs, but might be more problematic elsewhere, like maybe on Apple’s own CPUs? And then someone decided to just always take that mutex lock, instead of investigating possible use of atomic operations.
Now, Apple’s OS is BSD-based, so we can check what other BSD based systems do.
- FreeBSD does not have any mutexes there, and before 2021 September was just checking a flag. Since then, the flag check was changed to use atomic operations.
- OpenBSD does not use any atomics or mutexes at all, and the “has something changed?” flag is not even per-locale, it’s just a global variable. YOLO!
So given all this knowledge, presumably, if each thread used a physically different locale object and snprintf_l, then it
would scale fine. And it does:
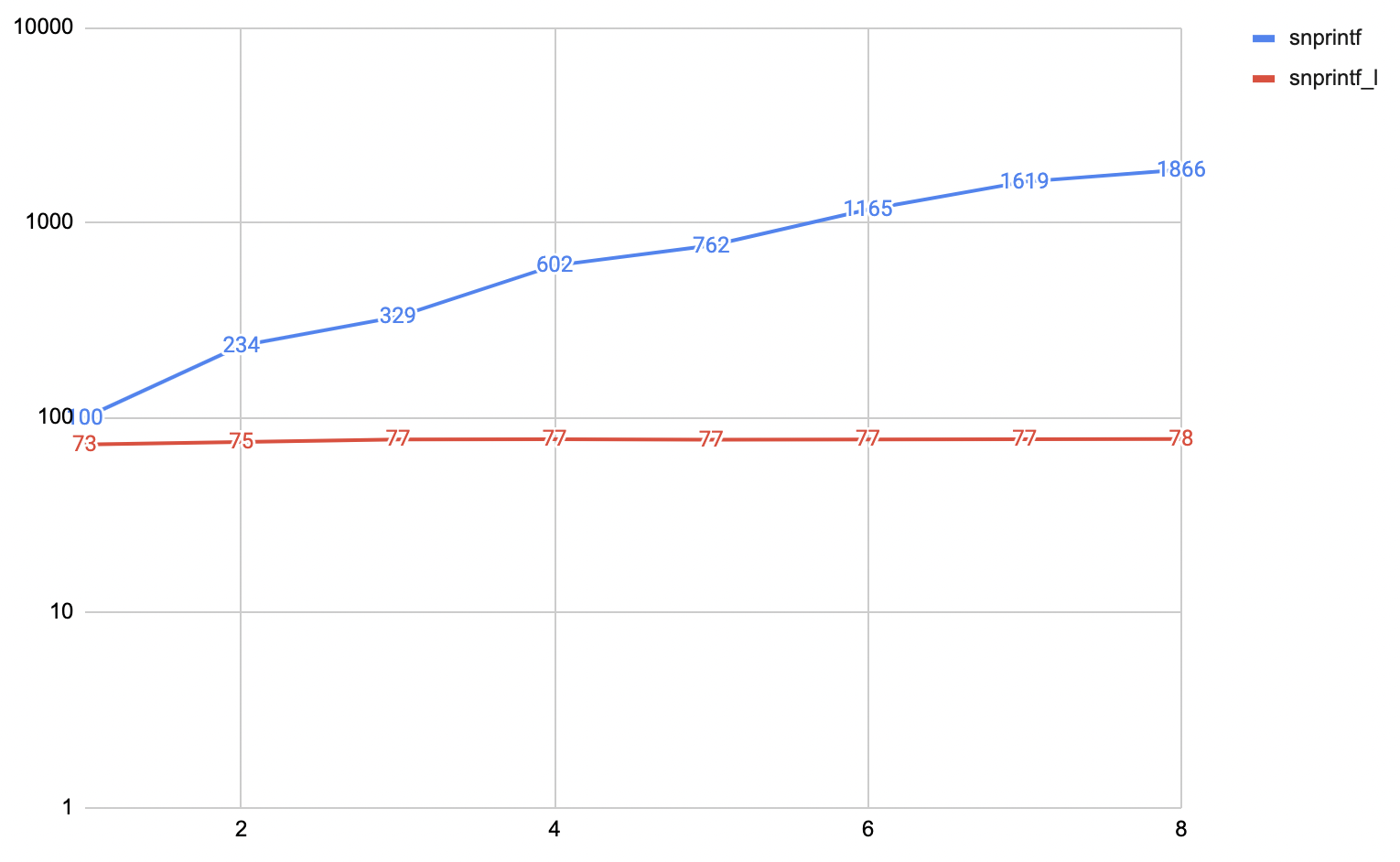
What else can we do?
Now, besides the old snprintf and std::stringstream, there are other things we can do. For example:
- stb_sprintf, a trivial to integrate, public domain C library that is a full sprintf replacement, but without any locale specific stuff. It’s also presumably faster, smaller and works the same across different compilers/platforms.
- {fmt}, a MIT-licensed C++ library “providing a fast and safe alternative to C stdio and C++ iostreams”. {fmt} was a base for C++20 formatting additions.
- Not a general replacement, but if we only need to turn numbers into strings, C++17 has to_chars.
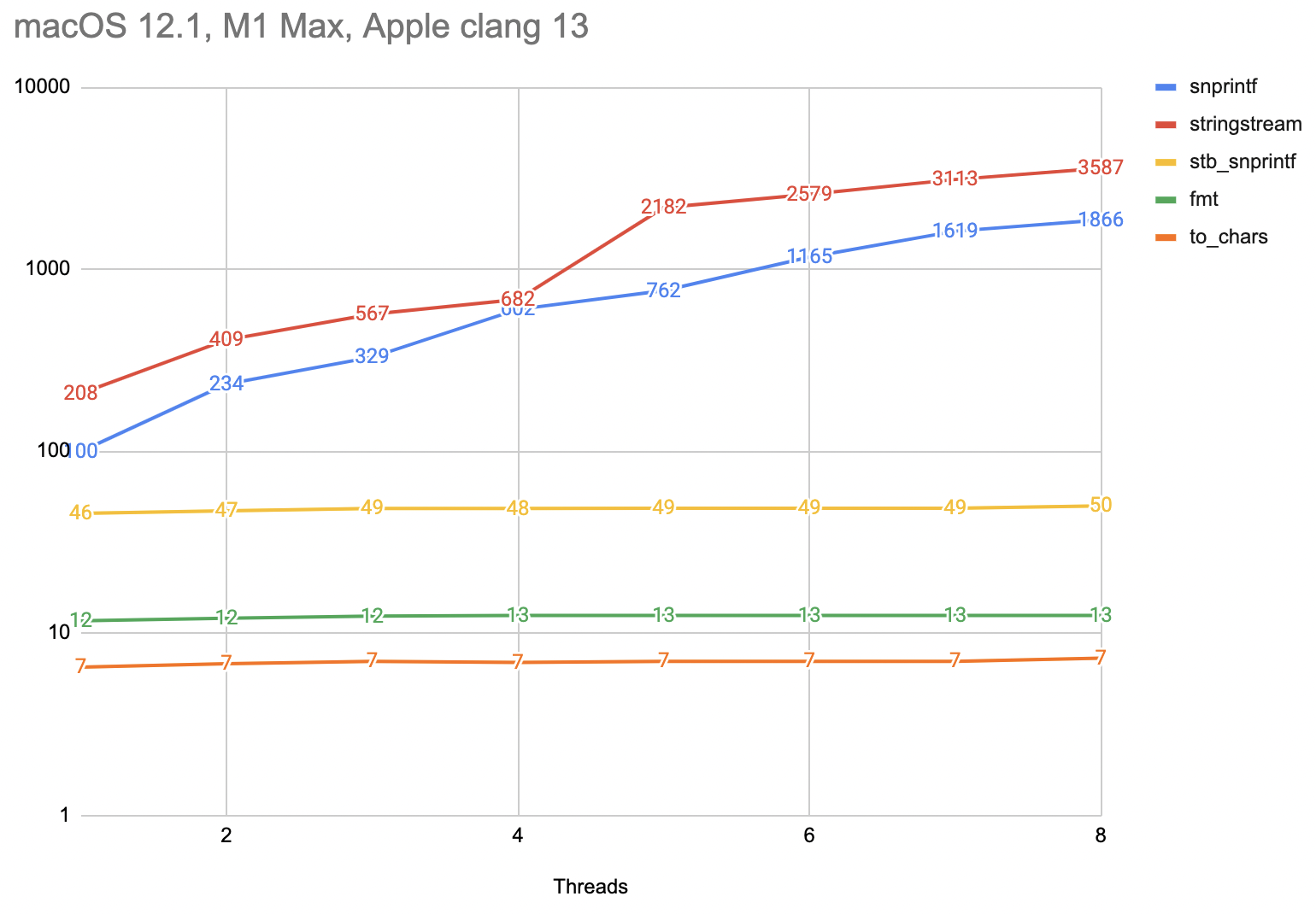
All of those scale with increased thread usage just fine, and all of them are way faster in single threaded case too. {fmt} looks very impressive. Yay!
Is this all Apple/Mac specific?
Let’s try all the above things on Windows with Visual Studio 2022. This one supports more things compared to clang 13 that I have on a Mac:
- There is C++20 formatting library with
format_to_n. This uses the same type safe syntax as {fmt} library, and we can hope it would be of a similar performance and scaling. - Similar to BSD-specific
snprintf_l, Visual Studio has its own_snprintf_l. - Speaking of not-so-general solutions, Visual Studio also has
itoato convert integers into strings.
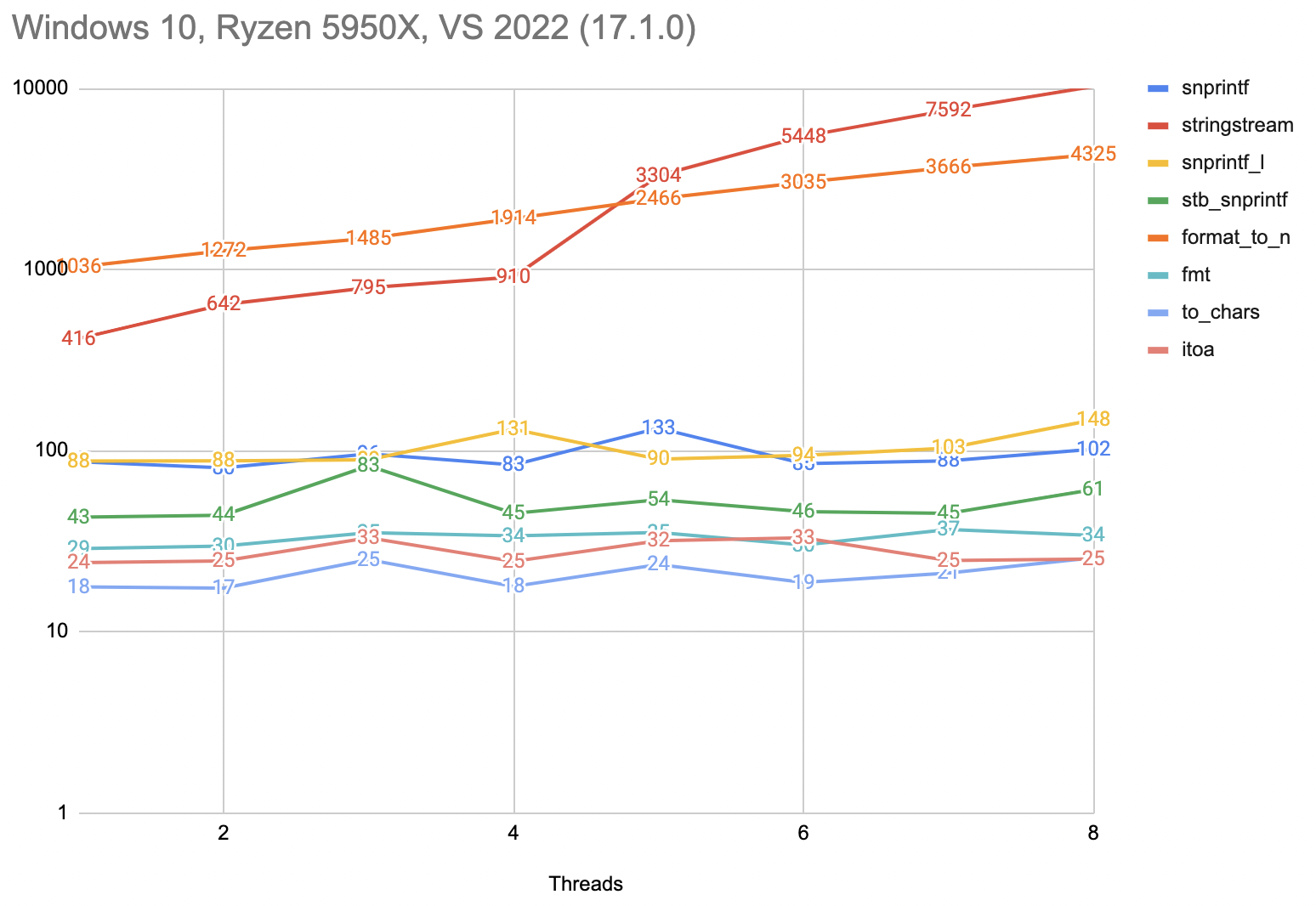
- Unlike the Mac case, just the regular
snprintfdoes not have the multi-threaded scaling issue! It takes around 100 milliseconds for two million integers, no matter how many threads are doing it at the same time. - C++
stringstreamperformance and scaling is really bad. It starts being 4x slower than snprintf at one thread, and goes up to be hundred times slower at 8 threads. - The new, hot, C++20 based formatting functionality using
format_to_nis really bad too! It starts being 10x slower than snprintf (!), and goes to be 40x slower at 8 threads.
Ok, what is going on here?! Superluminal profiler to the rescue, and here’s what it says:
The stringstream, in one thread case, ends up spending most of the time in the infamous “zero-cost abstractions” of C++ :) A bunch of
function calls, a tiny bit of work here and there, and then somewhere deep inside it ends up calling snprintf anyway. Just all around
that, tiny bits and pieces of cost all add up. In the 8 threads case, it ends up spending all the time inside mutex locks, quite
similar to how Mac/Apple case was doing. Just here it’s C++, so it ends up being worse - there’s not a single mutex lock, but rather
what looks like three mutex locks on various parts of the locale object (via std::use_facet of different bits), and then there’s
also reference counting, with atomic increase/decrease operations smashing the same locale object.
The format_to_n, in one thread case, ends up spending all the time in… 🥁… Loading resource files.
:WAT: Each and every call
“plz turn this integer into a string” ends up doing:
- Create something called a
_Fmt_codecobject, which - Calls
__std_get_cvt, which - Figures out “information about installed or available code page” via
GetCPInfoExW, which - Ends up calling
FindResourceExWandLoadResourceon something. Which then callLdrpLoadResourceFromAlternativeModuleandLdrpAccessResourceDataNoMultipleLanguageand so on and so on.
In the 8 threads case, that is all the same, except all that resource loading is presumably on the same “thing”, so it ends up
spending a ton of time deep inside the OS kernel doing MiLockVadShared, and MiUnlockAndDereferenceVadShared, and
LOCK_ADDRESS_SPACE_SHARED and so on.
So that is something I would not have expected to see, to be honest. Curiously enough, there is a similar sounding issue on Github of Microsoft’s STL, which is marked resolved since 2021 April.
And no, usual Internet advice of “MSVC sucks, use Clang” does not help in this particular case. Using Clang 13, the C++20 formatting library is not available yet, but otherwise all other options look pretty much the same, including the disappointing performance of stringstream:
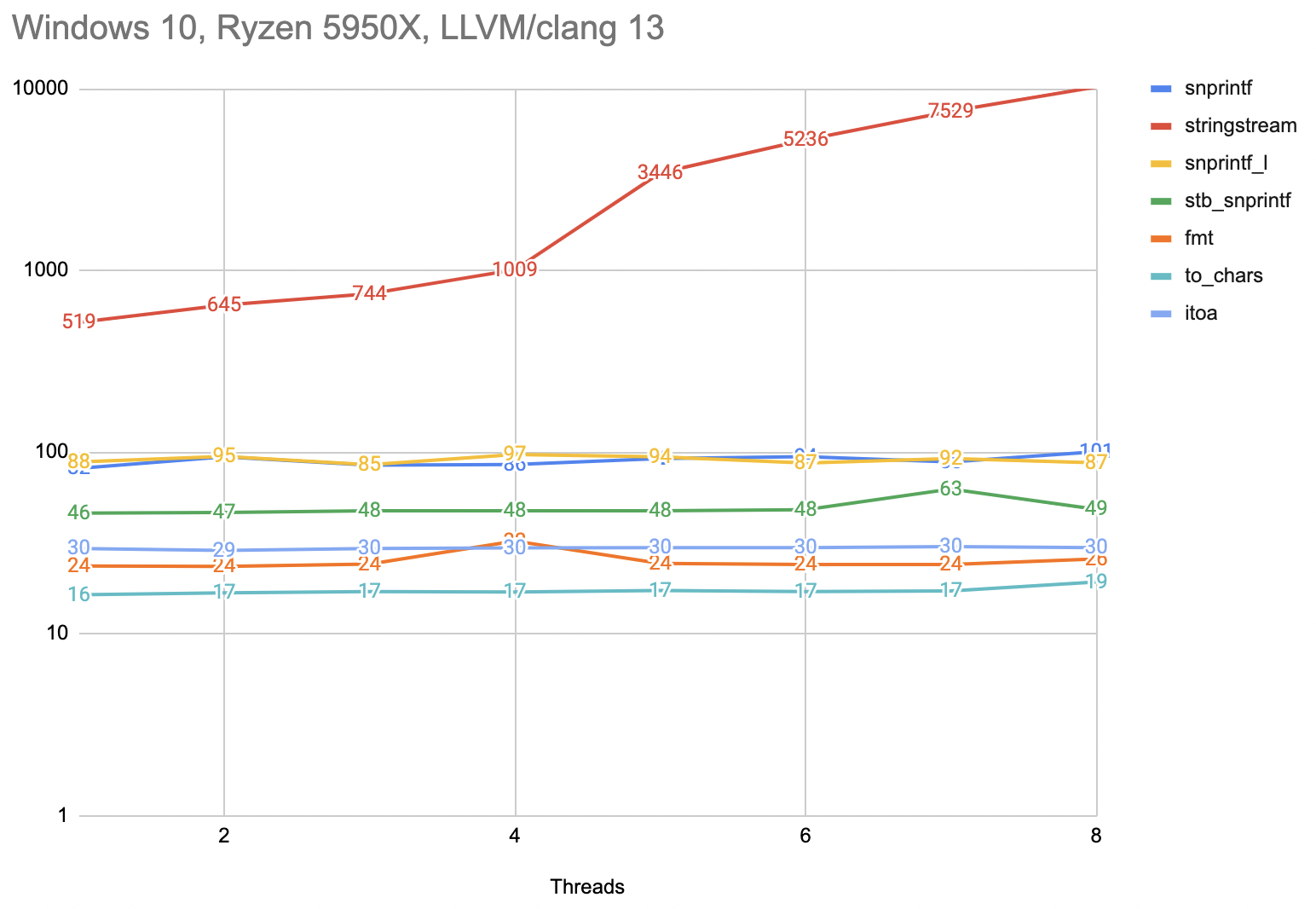
What about Linux?
I only have an Ubuntu 20 install via WSL2 here to test, and using the default compilers there (clang 10 and gcc 9.3),
things look pretty nice:

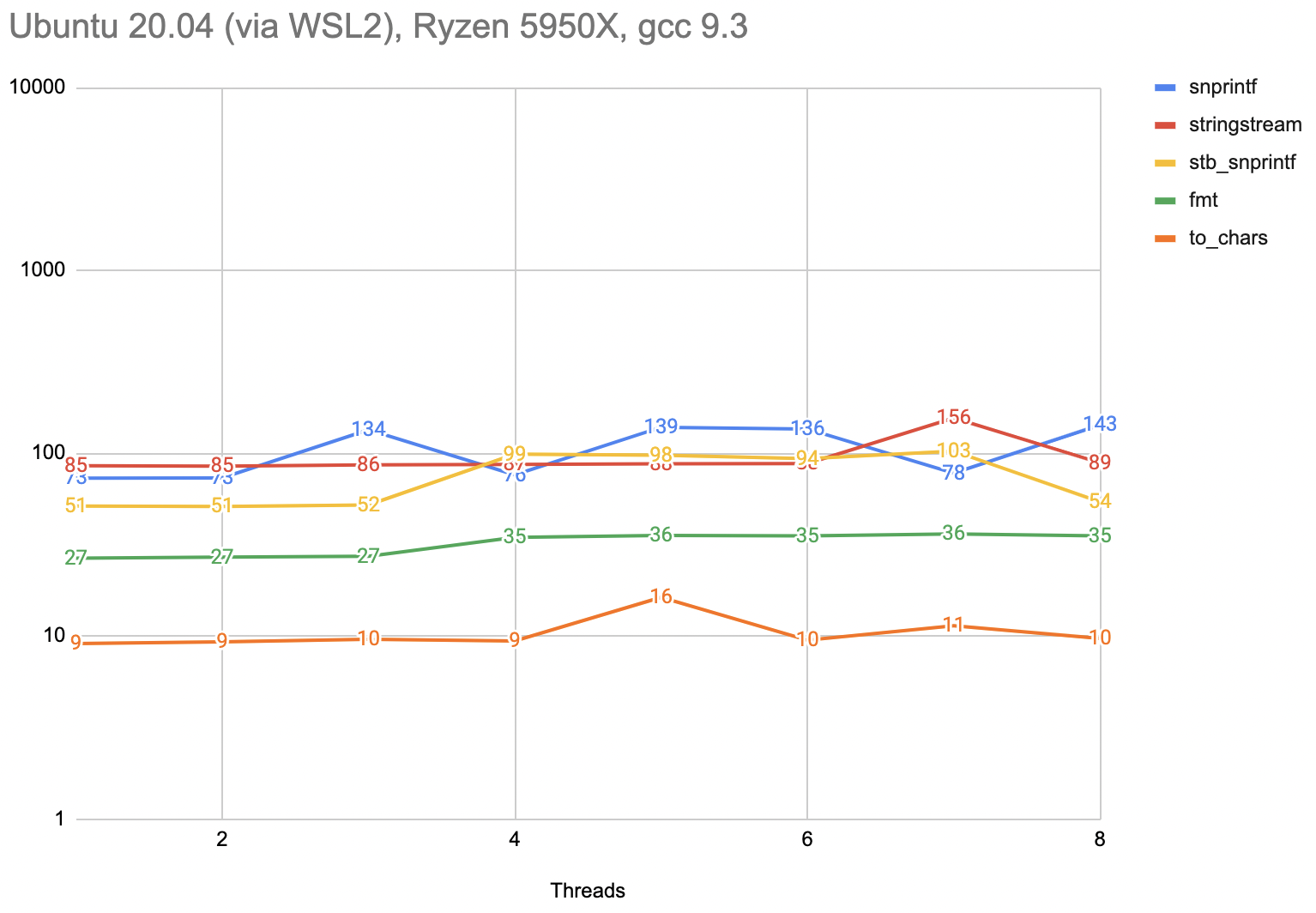
C++20 format library is not available in either of these compilers to test, but everything else scales really well with increased thread count. {fmt} continues to be impressive there as well.
Conclusion
Would you have expected a “turn an integer into a string” routine to be loading resource file information blocks from some library, for each and every call? Yeah, me neither.
Technically, there are no bugs anywhere above - all the functions work correctly, as far as standard is concerned. But some of them have interesting (lack of) multi-core scaling behavior, some others have just regular performance overheads compared to others, etc.
If you need to target multiple different compilers & platforms, and want consistent performance characteristics, then avoiding some parts of C or C++ standard libraries might be one way. Or at least, do not assume anything about performance (and especially about multi-thread scaling) characteristics of the standard libraries.
If you need to do string formatting in C++, I can highly recommend using {fmt}.