Unreasonable Effectiveness of Profilers
A couple months ago I added profiling output to our build system (a fork of JamPlus). It’s a simple Chrome Tracing view, and adding support for that to Jam was fairly easy. Jam being written in C, I found a simple C library to do it (minitrace) and with a couple compilation fixes it was working and had profiler blocks around whatever tasks the build system was executing.
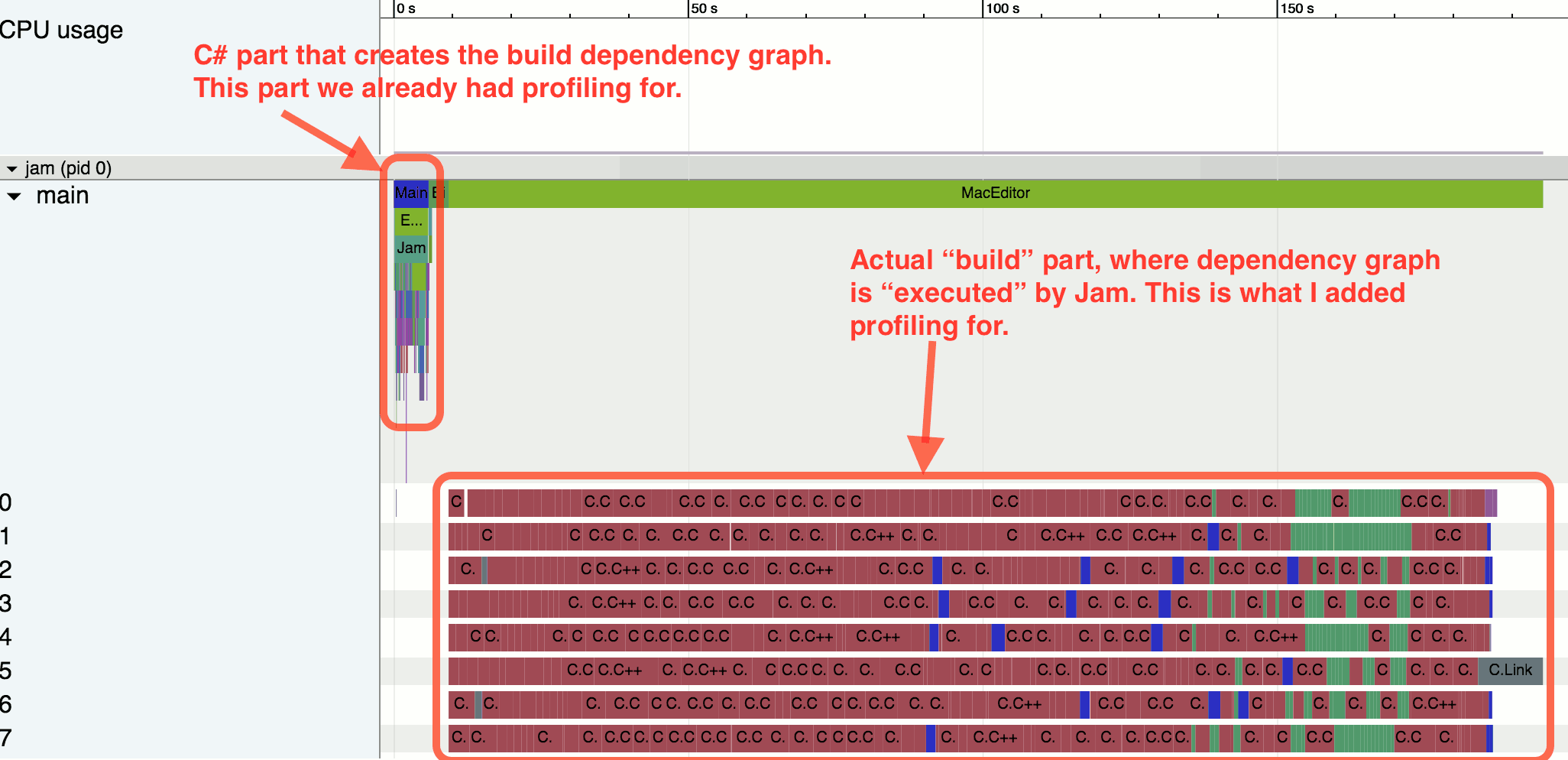
That by itself is not remarkable. However… once you have profiling output, you can start to…
Notice Things
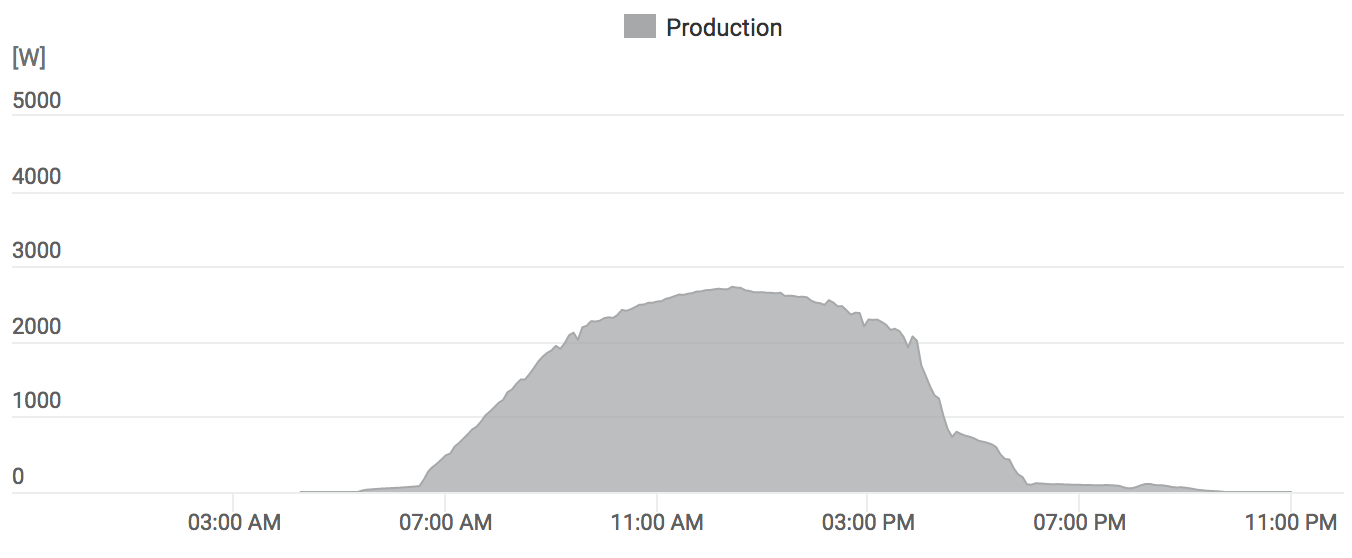
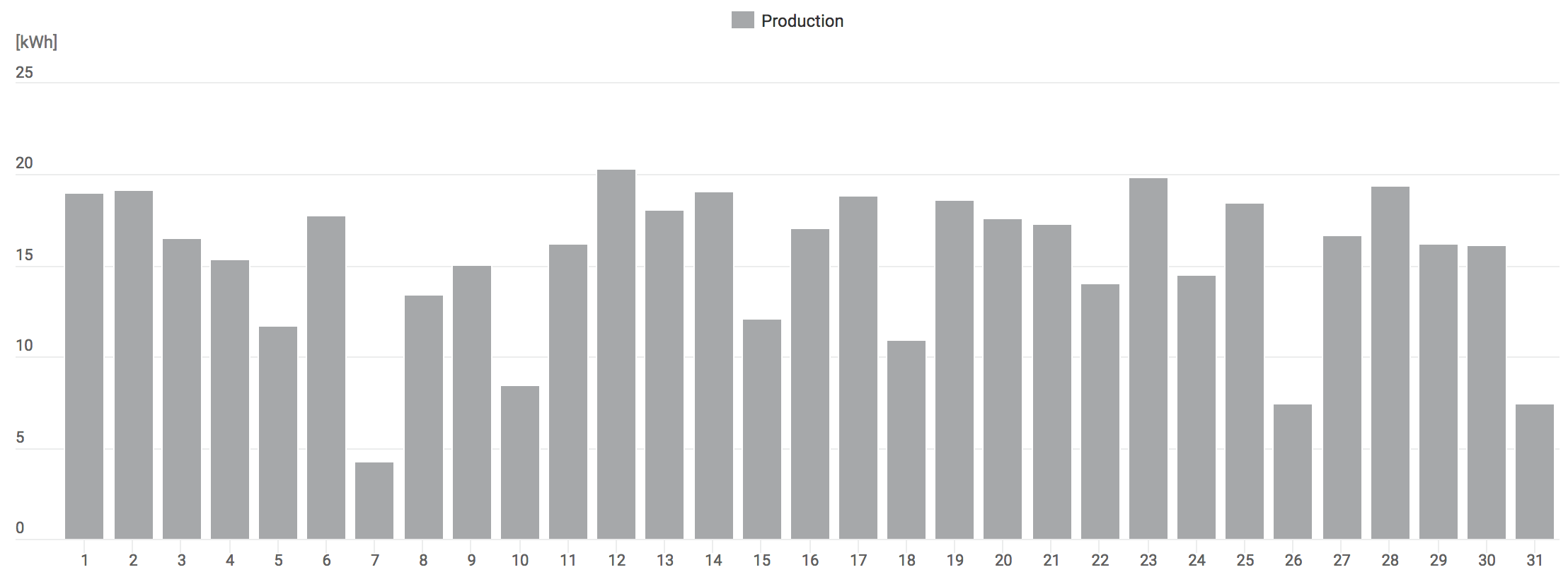
The other day I was doing something unrelated, and for some reason looked at a profiler output of Unity editor build I’ve just done. “Common sense” about C++ codebases tells us that usually it’s the linking time that’s The Worst, however here it was not that:
There’s a whole gap right before linking starts, when everything else is done, just the build is waiting for one C++ file to compile. I was busy with something else right then, so added a TODO card to our team task board, to be looked at later.
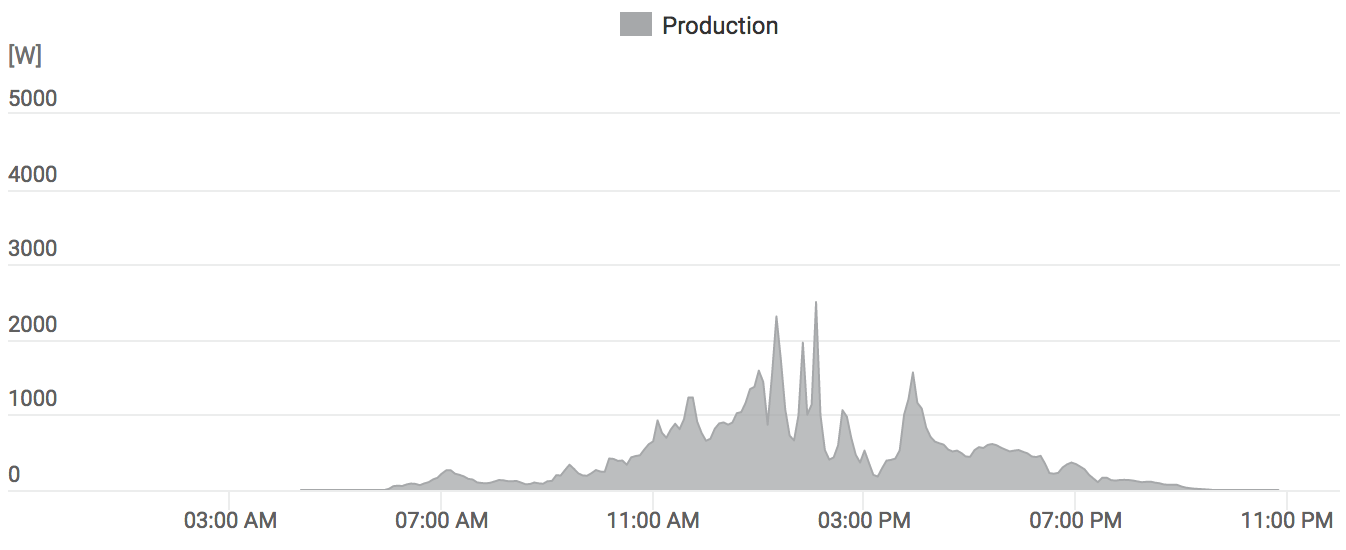
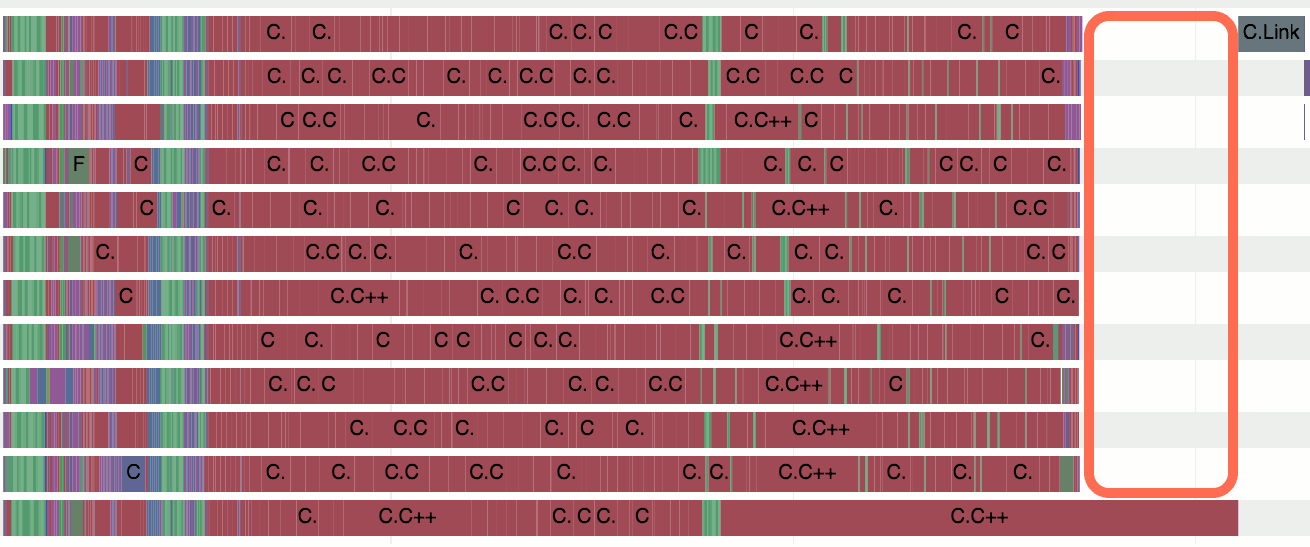
Sometime later I was doing a different build (of just the “engine” without the editor bits), and looked at the profiler too:
Now that looks pretty bad. The total build time (this was a “full rebuild”) was ten minutes, and almost five of them were “wait for that one C++ file to finish compiling”. The file in question had a compile time of seven minutes.
This sounded like a build inefficiency that is too large to ignore, so I dug in for a bit.
Aside: at the moment our small “build team” has not even started to look into “full build” performance, for various reasons. Mostly repaying tech debt (with interest!), optimizing incremental build performance and improving things like IDE projects. Optimizing full build time we will get to, but haven’t just yet.
7 minutes compile time for one file? Craaazyy!
Yes, it is crazy. Average compile time for C++ files in this project and this config (win64 Release) is about 2 seconds. 400+ seconds is definitely an outlier (though there’s a handful of other files that take 30+ seconds to compile). What is going on?!
I did some experiments and figured out that:
- Our Lump/Batch/Unity builds are not the culprit; there’s one .cpp file in that particular lump that takes all the time to compile.
- MSVC compiler exhibits this slow compilation behavior; clang compile times on that file are way better (10+ times faster).
- Only Release builds are this slow (or more specifically, builds where inlining is on).
- The fairly old VS2010 compiler that we use is not the culprit; compiling with VS2015 is actually a tiny bit slower :(
- In general the files that have 30+ second compile time in Release build with MSVC compiler tend to be heavy users of our “SIMD math library”, which provides a very nice HLSL-like syntax for math code (including swizzles & stuff). However the implementation of that is… shall we say… quite template & macro heavy.
- That 7 minute compile file had a big SIMD math heavy function, that was templated to expand into a number of instantiations, to get rid of runtime per-item branches. This is in CPU performance sensitive code, so that approach does make sense.
Whether the design of our math library is a good trade-off or not, is a story for another day. Looks like it has some good things (convenient HLSL-like usage, good SIMD codegen), and some not so good things (crazy complex implementation, crazy compile times on MSVC at least). Worth discussing and doing something about it in the future!
Meanwhile… could some lo-tech changes be made, to speed up the builds?
Speeding it up
One easy change that is entirely in “build systems” area even, is to stop including these “slow to compile” files into lump/batch/unity builds. Lump builds primarily save time on invoking the compiler executable, and doing preprocessing of typically similar/common included code. However, all that is sub-second times; if a single source file takes 10+ seconds to compile then there’s little point in lumping. By itself this does not gain much, however for incremental builds people won’t have to wait too long if they are working on a fast-to-build file that would have ended in the same lump as a slow file.
Could also somehow make the build system schedule slow files for compilation as soon as possible. The earlier they start, the sooner they will finish. Ideally the build system would perhaps have historical data of past compile times, and use that to guide build task scheduling. We don’t have that in our build system (yet?)… However in our current build code, moving slow files out of lumps makes them be built earlier as a by-product. Good!
The above things didn’t actually speed up compilation of that 7-minute file, but were trivial to do and gained a minute or so out of full build time (which was 10 minutes originally).
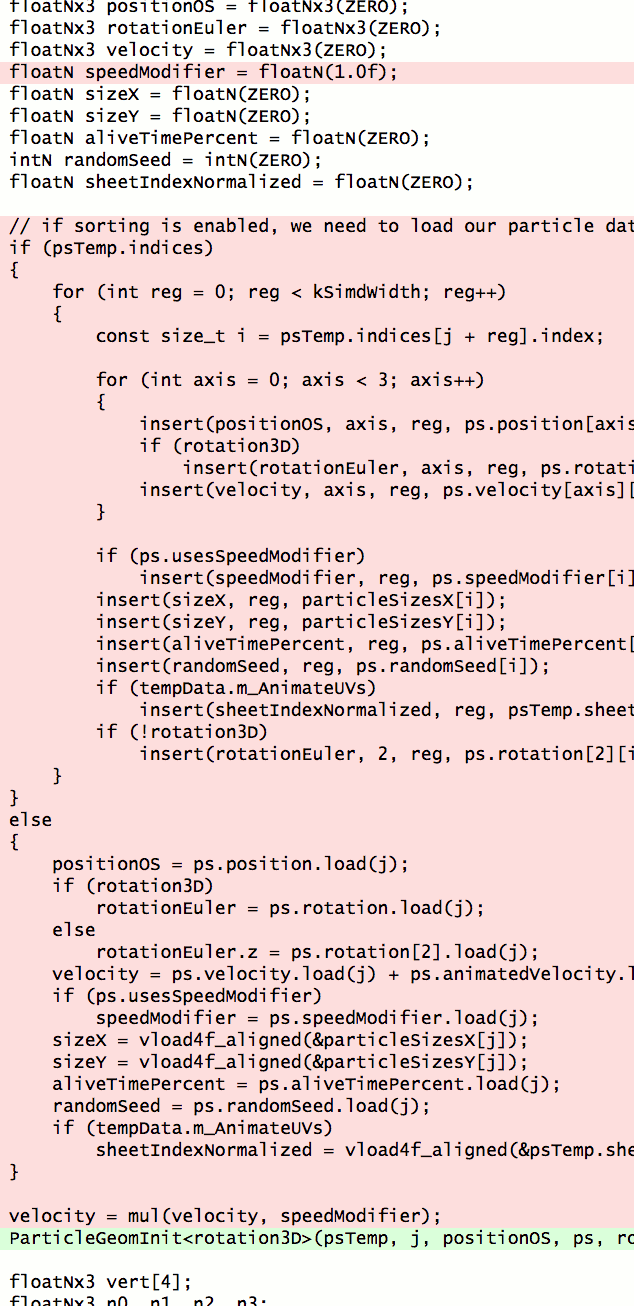
And then I tried something that I didn’t have high hopes of working - in that slow file, factor out parts of the big templated function into smaller, less-templated functions.
Fairly trivial stuff; if you’re into fancy refactoring IDEs that is done by “select some code lines, press Extract Method/Function button”. Except this is C++, and the IDEs don’t quite get this right (at least in this code), so you do it manually.
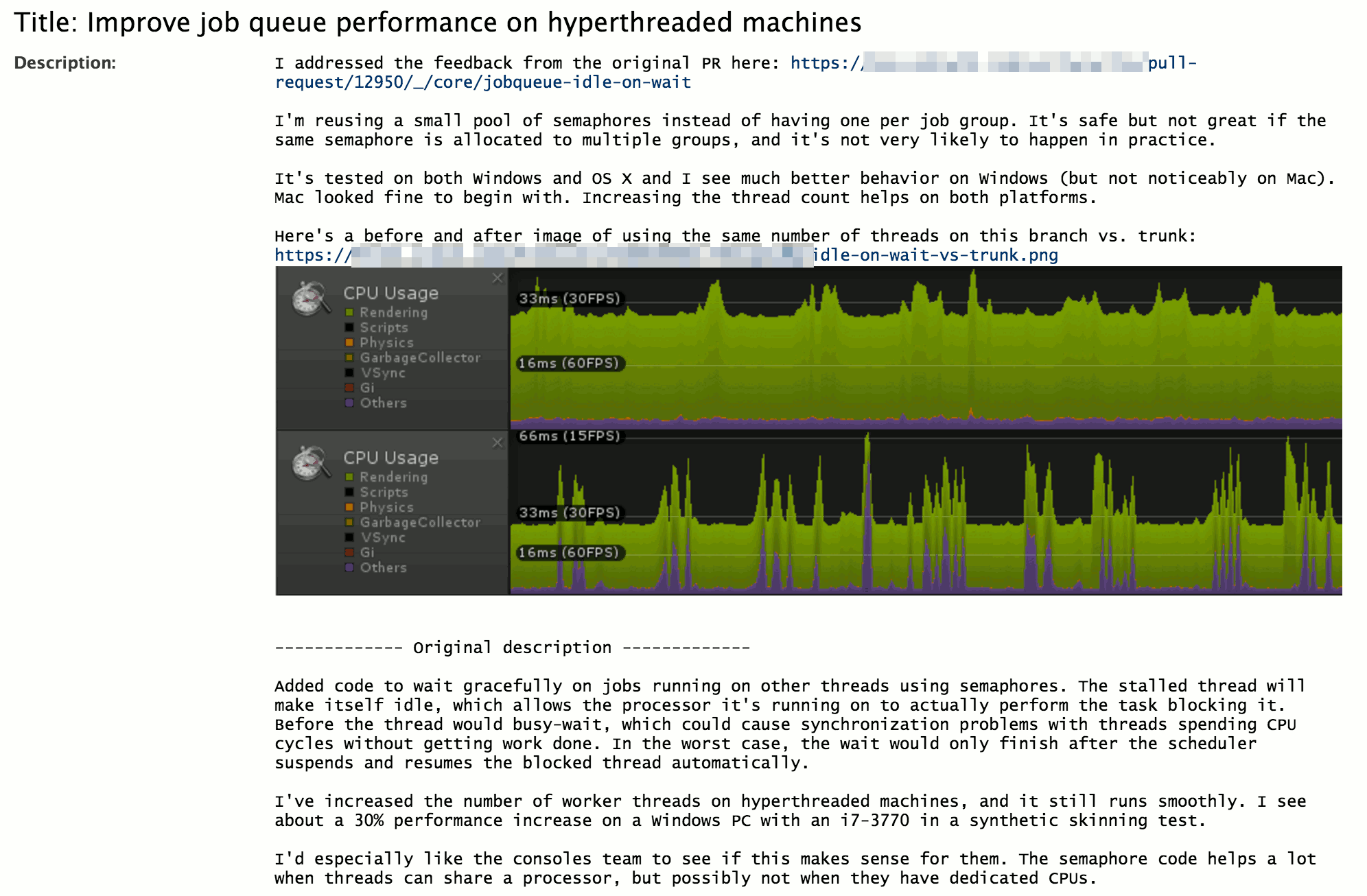
I split off five or so functions like that and… compile time of that file went from 420 seconds to 70 seconds. That is six times faster!
Of course, factoring out functions can mean they are no longer inlined, and the original code will have to call them. So that’s time spent in passing the arguments, doing the jump etc. However, it could make parent function use registers better (or worse…), could result in lower amount of total code (less I$ misses), etc. We have profiled the code change on several platforms, and the difference in performance seems to be negligible. So in this particular case, it’s a go!
Now of course, a minute to compile a C++ file is still crazy, but additional speedups probably involve changing the design of our math library or somesuch – needs more work than someone clueless randomly trying to speed it up :)
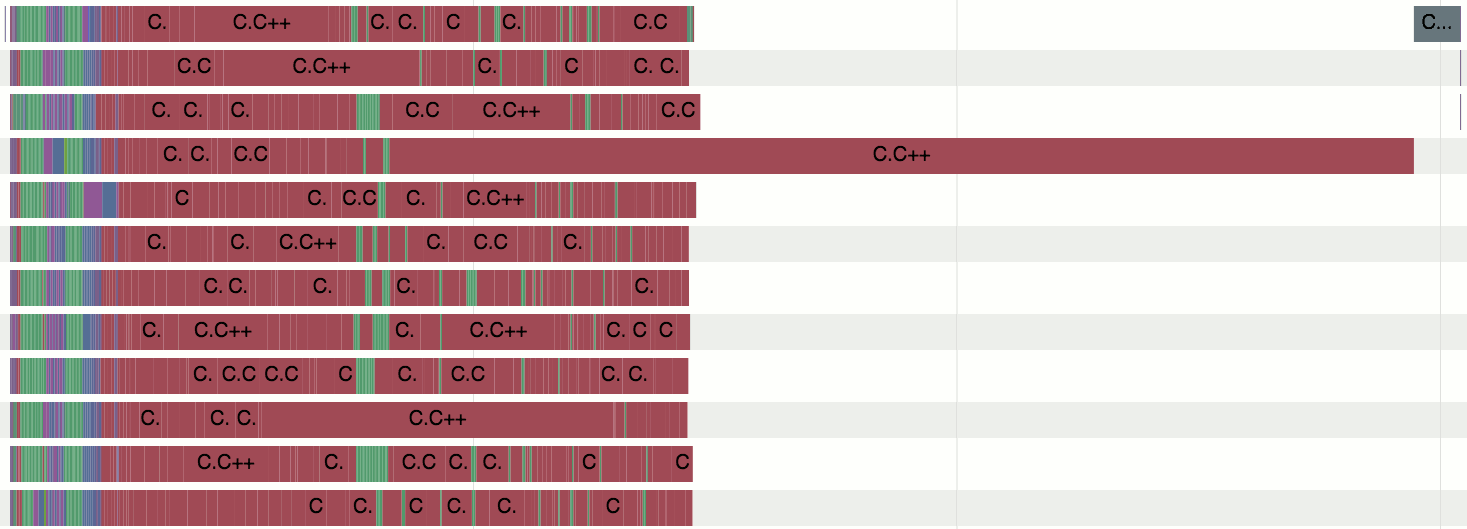
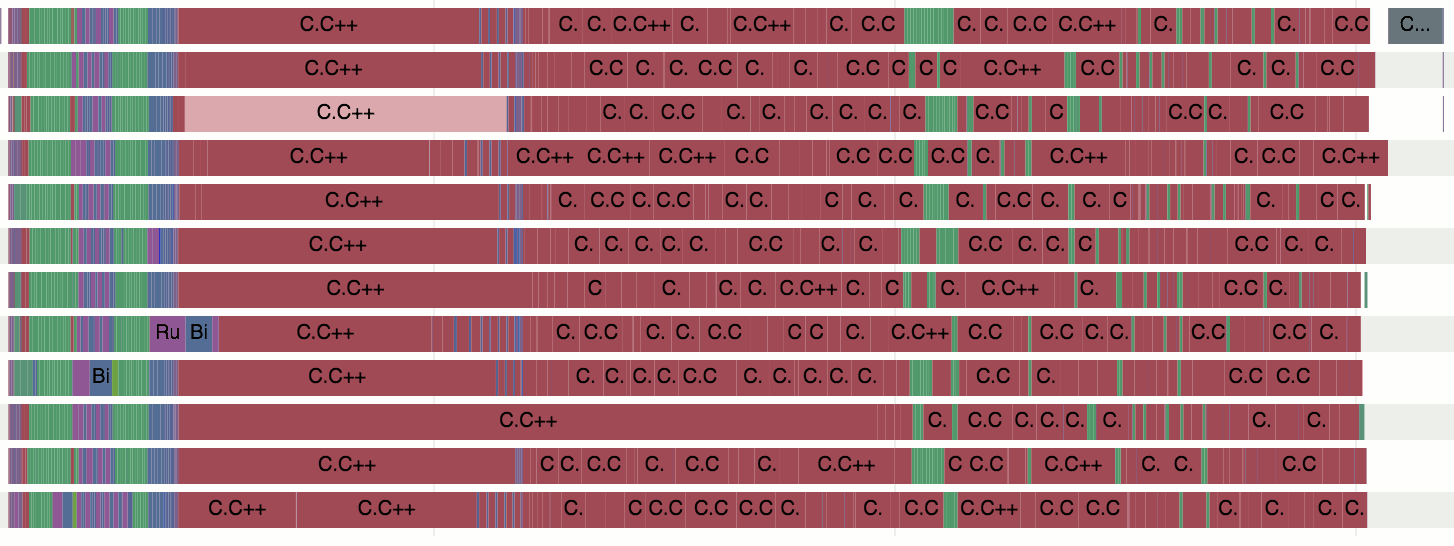
The build profile looks much better after the change. No longer gaps of “all the CPU cores wait for one job to finish” type of stuff! Well ok, linking is serial but that is old news. Full build time went from 10 minutes down to 5min 10sec, or almost 2x faster!
Takeaways
- Add some sort of profiling data capture to everything you care about. Had I not added the profiler output,
who knows when (or if?) someone would have noticed that we have one super-slow to compile C++ source file.
In my case, adding this simple profiling capture to our build system took about a day… most of that spent
learning about Jam’s codebase (my first change in it).
- Seriously, just do it. It’s easy, fun and worth it!
- Every template instantiation creates additional work for the compiler’s optimizer; pretty
much as if the instantiated functions were literally copy-pasted. If a templated function was slow to compile
and you instantiate the template 20 times… well now it’s very slow to compile.
- Factoring out parts into less-templated functions might help things.
- Complicated template-heavy libraries can be slow to compile (“well duh”, right). But not necessarily due to parsing (“it’s all header files”); the optimizer can spend ages in them too. In MSVC case in this code, from what I can tell it ends up spending all the time deciding what & how to inline.
- Speeding up builds is good work, or at least I like to think so myself :) Less time spent by developers waiting for them; better throughput and lower latency in build farms, etc. etc.