Hello! End of June & start of July we were traveling in Iceland, so here’s some photos and stuff.

I’ve heard that some folks somehow don’t know that Iceland is absolutely beautiful. How?! Here’s my
attempt at helping the situation by dumping a whole bunch of photos into the series of tubes.
Planning
We’ve been to Iceland before; what we did differently this time was:
- Almost 2x longer trip (11 days),
- Our kids are 5 years older (15 and 9yo), which makes it easier! We are five years older too though :/
- Six people in total, since now we also took my parents. This meant renting two cars.
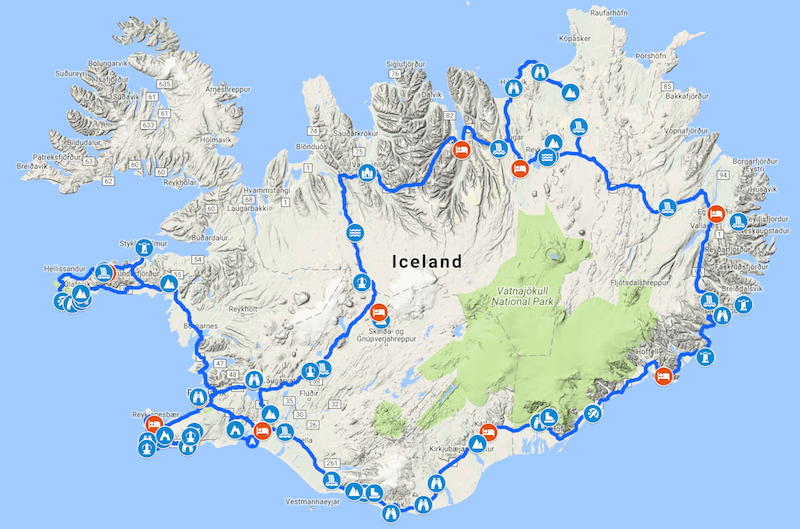
Similar to last time, I used internets and google maps to scout for locations
and do rough planning. It was basically “go around the whole country” (on the main Route 1),
cutting in one place via the highland Route F35, and then a detour
into Snæfellsnes peninsula.
Total driving distance ended up ~2600km (200-300km per day). That does not sound a lot, but we did not end up
having “lazy days”; there is a lot to see in Iceland, and every stop along the way is basically an hour or two.
For example you might want to hike up the waterfall, or get down to some cliffs in the water, etc.
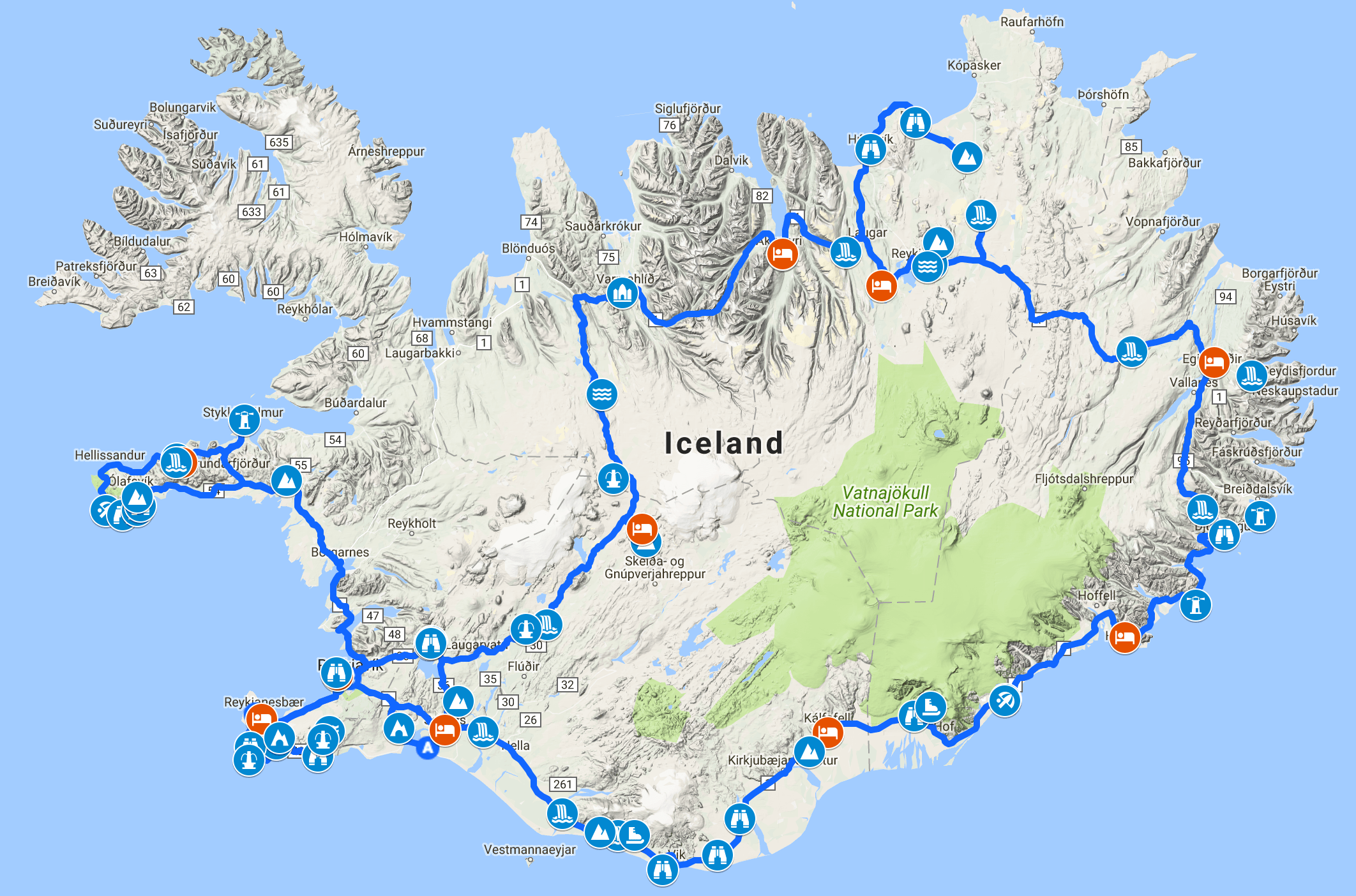
The map on the right shows all the places we did end up stopping at. I had a dozen more marked up, but we skipped
some.
I booked everything well in advance (4 months), either via Booking.com or Airbnb.
Since we were a party of six, in some more remote places there was not that many choices actually. Having a camper
or tents might be much cheaper and allow more freedom, at expense of comfort.
Cost wise, some things (like housing) has visibly increased since 2013 when we were last there. Makes sense, since the amount of tourists
has increased as well; capitalism gonna capital. Total cost breakdown for us was:
33% housing, 23% flights, 20% car rent, 24% everything else (food, eating out,
gas, guided trips, …).
Late June is basically “early summer” in Iceland. Most/all of the highland roads are already open. There can be quite a lot of rain; I was looking at the forecasts
and it did not look very good. Luckily enough, we only got serious rain for like 3 days; most other days there was relatively little
rain. Temperature was mostly in +8..+15°C range, often with a really cold wind. There were moments when I wished I’d taken gloves :)
Photo Impressions
Most of the photos are taken by my wife.
Equipment: Canon EOS 70D with Canon 24-70mm f/2.8 L II and Sigma 8-16mm f/4.5-5.6. Some taken with iPhone SE.
Day 1, South (Selfoss to Kirkjubæjarklaustur)
The southern part is quite crowded with tourists; going up to Dyrhólaey/Vik is plenty of sights and a good trip for
a day. We also started the first day with “ok there’s a million things to see today!”.
First up, mostly waterfalls. Urriðafoss,
Seljalandsfoss, a view into the infamous
Eyjafjallajökull, and
Skógafoss.
Fun fact! Unity codebase has a text = "Eyjafjallajökull-Pranckevičius"; line
in one of the tests, that checks whether some thing deals with non-English characters. I think
@lucasmeijer added that.




End of June is blooming time of Nootka Lupin;
there are vast fields full of them. People go to take wedding photos and whatnot in there.


Next up, we can go to the tongue of Sólheimajökull glacier
(this is a bit redundant; “jökull” already means “glacier”). I’ve never seen a glacier before, and
the photos of course don’t do it justice. This is a tiny piece at the end of the glacier. Very impressive.



Dyrhólaey peninsula:


Dverghamrar basalt column formations, with Foss á Síðu waterfall in the distance (redundancy again, “foss”
already means “waterfall”):


Day 2, South/East (Kirkjubæjarklaustur to Höfn)
Driving up to another glacier, Svínafellsjökull. Again, the scale is hard to comprehend; many glaciers in Iceland
are 500 meters high, some going up to a kilometer. A kilometer of ice!


A short (but very bumpy) road to the side, and we are close to it:



Next up, Jökulsárlón glacial lake. Was
a setting for a bunch of movies! The lake is just over a hundred years old, and is growing very fast,
largely due to melting glaciers.




Right next to it there is so called “Diamond Beach”, where icebergs, after being flushed out into the sea
and eroded by salt, come ashore as tiny pieces of ice. The sand is black of course, since it was originally
pumice and volcanic ash.


Day 3, East (Höfn to Egilsstaðir)
Eastern side of Iceland is where there’s no tourist crowds, and no big-name attractions either. Even the main
highway road becomes gravel for a dozen kilometers in one place :) Most of the Route 1 goes along the coastline
that is full of fjords, which makes for a fairly long drive. There is a shortcut
(route 939 aka Öxi) that lets you cut some 80km, but it’s
gravel and very steep (here’s random youtube video showing it).
I thought “let’s do the coastline instead, we’ll watch plenty of sea and cliffs”. Not so fast!
Turns out, coastline can mean that there’s a literal cloud right on the road, and you basically don’t see
anything. Oh well :)




There were some lighthouses (barely visible due to mist/fog/clouds), a nice waterfall (Sveinsstekksfoss),
and also here’s a photo of our typical lunch:



We stayed in a lovely horse ranch, and also found an old car dump nearby.





Day 5, North/East (Egilsstaðir to Mývatn)
Most of the day was driving on Route 1 through Norður-Múlasýsla region. First you see towns and villages disappear,
then farms disappear, and then even sheep disappear (whereas normally sheep are everywhere in Iceland).
What’s left is a volcanic desert with basically a single road cutting through it.


There was a waterfall (Rjúkandi) near start of that trip, and lava fields towards the end, close to Dettifoss.


Here’s Dettifoss, which is 100m wide, 44m deep and other
measurements as well (ref).


Nearby, the Krafla area with the Víti crater, Krafla power station
and Hverir geothermal area with fumaroles and mudpots.





Lake Mývatn nearby has a flying mountain (not really, just low fog) and a lot of birds.


Day 5, North (Mývatn to Akureyri)
Mývatn to Akureyri is a very short drive, so we did a detour through Husavik towards
Ásbyrgi canyon.
Last time we were in Iceland, Husavik was lovely and Ásbyrgi
was quite impressive. However this time, pretty much the whole day was heavy rain. Not much visibility, and
not too pleasant to hike around and enjoy the sights. Oh well! Here’s Ásbyrgi and
Goðafoss:



Akureyri has an excellent botanical garden; more photos from it at
my wife’s blog.



Day 6, Highlands (Akureyri to Kerlingarfjöll)
This was where we took off the main highway and into the F35/Kjalvegur
gravel road. I heard from a bunch of people the suggestion along the lines of “OMG you have to go along one of the
highland roads”, and so that’s why we did it. F35 is the easiest of those; legally it requires a 4x4/AWD car
but I think technically any car should be able to do it. Most other highland roads actually have river crossings; whereas
F35 only has one or two small streams to cross. Most of the road is actually in very good condition (at least at start
of July), with only a couple dozen kilometers that have enough stones and pits to make you go at 20-30km/h.







There is Hveravellir geothermal area near Langjökull:




We stayed at a place near Kerlingarfjöll:


And decided to hike towards a nearby rhyolite mountain area (Hveradalir). Apparently I must have misread something somewhere,
since what I thought was 3km turned out to be 5km one way (mixup of miles vs kilometers in my head?),
the path was steep, with blobs of snow along the way, really strong wind and a descending cloud. At some point
we decided to declare ourselves losers and just turn back. Oh well :/





Turns out, you can just drive up to the same area via some mountain road. It’s steep and bumpy, and there was still
tons of snow on the side, but the views up there were amazing. The wind almost blew us away though; maybe it’s
good that we did not hike all the way.




Day 7, Part of Golden Circle (Kerlingarfjöll to Reykjavik)
“Golden Circle” is a marketing term for probably
the most touristy route in Iceland. But parts of it did happen to be on our way, so we went straight
from the highlands where there’s no one around, into “all the tourists in one spot” types of places
like Gullfoss.



Next up, Strokkur geyser, again with a ton of tourists:
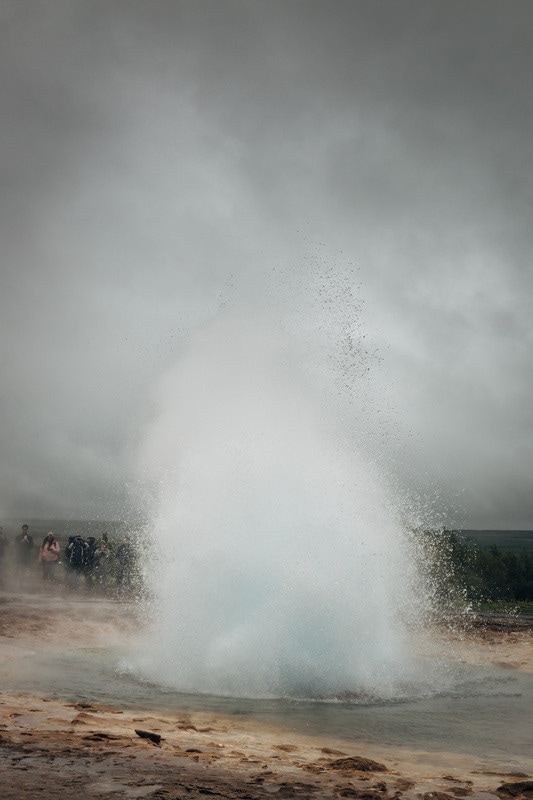

And we spent the evening just strolling around Reykjavik.





Day 8, Part of Golden Circle (around Reykjavik)
Þingvellir national park, most famous for being
a place where you can actually see the rift between Eurasian and North American tectonic plates, and also
for being a place of Alþingi, one of the oldest parliaments in
the world.




Next up, Kerið crater. Similar to Krafla’s Víti, except with more
tourists and you can get down to the lake itself.

Then we went to the Raufarhólshellir lava cave.
Things I learned: “skylight” is not just a computer graphics term (also means places where underground caves have openings
towards the ground); lava flow produces really intricate “bathtub ring” patterns; and complete darkness feels
eery.





Day 9, West (Reykjavik to Snæfellsnes)
Driving up to Snæfellsnes takes a good chunk of time,
with generally nothing to see along the way (in relative terms of course; in many other countries these
valleys and horizons would be amazing… but Iceland has too many more impressive sights). There are
Gerðuberg basalt columns midway:


…but apart from that, not much. I was starting to think “ohh maybe this will be a low point of the trip”, and
then! Rauðfeldsgjá gorge was very fun; you try to find
your way across a water stream in a very narrow gorge, with huge chunks of snow right above you.


Just a couple minutes from there, Arnarstapi village has really
nice cliffs at the water.





Five minutes from that, Hellnar village has even more impressive cliffs.
I mean look at them! That layout and flow of the rocks should not exist! :)






And then! Djúpalónssandur beach with black sand
and rock formations.




Near our sleeping place there’s Kirkjufell, which is featured
in a ton of photos showing off wide-angle lenses :)


Day 10, West/South (Snæfellsnes to Keflavík)
Stykkishólmur town and random sights on the way back.
Was an easy day without sensory overload :)






Day 11, Reykjanes Peninsula (around Keflavík)
Our flight back was in the evening, so we visited some places in Reykjanes near the airport. Gunnuhver
mud pool:


Krísuvíkurberg cliffs and Dollan lava caves:


Krýsuvík geothermal area:



Kleifarvatn lake:




And the famous Bláa Lónið (Blue Lagoon),
but we decided not to go inside (too many people, and didn’t feel the need either). There’s a power station
right next to it, and some tractors doing cleaning. Much romance, wow :)






Next time?
I have no doubt that we’ll go to Iceland again (seriously, it’s amazing). One obvious thing would be going in
the winter. So maybe that!