TL;DR: if you want to use -ftime-report Clang flag to help you figure out where or why your code is slow to compile…
it’s not very helpful for that. But! In the next post
we’ll try to do something about it :)
Depending on how your large your codebase is, and how it is structured, C++ compilation times may or might not be an issue for you.
It certainly is for us at Unity, and my understanding of build times of other large projects (like Chrome, LLVM or UE4), they aren’t
exactly “fast” either. There are various underlying reasons for why C++ codebases might be slow to compile (preprocessor, complexity
of the language, template instantiations, optimizations done by the compiler, linking times etc.).
It would make sense to have some tools that a programmer could use to help them understand where or why their code is slow to compile.
You might think that, given how big of an issue compile times are in C++, there would be readily-available tools to do that. E.g. some
flags in the popular compilers, or something?
The reality, at least right now, is “ehhh, not really”. There really are no good tools in C++ compilers to help you with investigating build
times.
I’ll do example with a super small C++ snippet that just includes some STL headers and does something with them. See the snippet
and the output from three major compilers (Visual Studio, Gcc, Clang) in Compiler Explorer here.
The actual code does not do anything useful, I just needed something to throw at the compiler.
#include <vector>
#include <string>
#include <unordered_map>
#include <regex>
int main()
{
std::vector<int> v(10);
v.push_back(7);
std::unordered_map<std::string, double> m;
m.insert(std::make_pair("foo", 1.0));
std::regex re("^asd.*$");
return 0;
}
I’m testing with Visual Studio 2017 v15.9, Gcc 8.2 and Clang 7.0.
Visual Studio
Visual Studio has /Bt
(see VC++ Team Blog post)
and /d2cgsummary (see my blog post) flags,
and while they don’t contain much information and the UX of them is “a bit lacking”, they are at least something.
/Bt prints how much time “frontend” (preprocessing, parsing - everything that is about the “C++ language”) and the “backend” (optimizations
and final machine code generation – much less specific to C++ language) takes.
time(C:\msvc\v19_16\bin\Hostx64\x64\c1xx.dll)=0.775s
time(C:\msvc\v19_16\bin\Hostx64\x64\c2.dll)=1.303s
Of course it would be way friendlier if instead of printing two paths to DLLs, it would actually print “Frontend” and “Backend”. That’s
what whatever\c1xx.dll and whatever\c2.dll actually are. Empathy towards the user is important!
Output of /d2cgsummary is even more cryptic, something like this (cut down for brevity):
Code Generation Summary
Total Function Count: 821
Elapsed Time: 1.210 sec
Total Compilation Time: 4.209 sec
Average time per function: 0.005 sec
Anomalistic Compile Times: 15
?_Add_equiv@?$_Builder@PEBDDV?$regex_traits@D@std@@@std@@QEAAXPEBD0_J@Z: 0.299 sec, 869 instrs
?_Add_rep@?$_Builder@PEBDDV?$regex_traits@D@std@@@std@@QEAAXHH_N@Z: 0.239 sec, 831 instrs
<...>
Serialized Initializer Count: 1
Serialized Initializer Time: 0.001 sec
RdrReadProc Caching Stats
Functions Cached: 5
Retrieved Count: 164
Abandoned Retrieval Count: 0
Abandoned Caching Count: 0
Wasted Caching Attempts: 0
Functions Retrieved at Least Once: 5
Functions Cached and Never Retrieved: 0
Most Hits:
?_Get_data@?$_Vector_alloc@U?$_Vec_base_types@IV?$allocator@I@std@@@std@@@std@@QEAAAEAV?$_Vector_val@U?$_Simple_types@I@std@@@2@XZ: 35
?_Get_second@?$_Compressed_pair@V?$allocator@I@std@@V?$_Vector_val@U?$_Simple_types@I@std@@@2@$00@std@@QEAAAEAV?$_Vector_val@U?$_Simple_types@I@std@@@2@XZ: 35
<...>
Least Hits:
?_Adopt@_Iterator_base0@std@@QEAAXPEBX@Z: 28
<...>
Most of that probably makes sense for someone who actually works on the Visual Studio compiler, but again - I’m just a user, I have
no idea what is “RdrReadProc”, what is “Serialized Initializer” or “Retrieved Count”, and most importantly,
whether any of this output can help me to answer the question
“how can I change my code to make it compile faster”? Also, why are the function names not demangled?
The “Anomalistic Compile Times” section can help to track down some patterns in code that end up being very slow for compiler to process
(like forced inlining on large functions), but that’s about it.
So while MSC does have something, I could think of many possible improvements in what kind of timing/profiling information it could output.
Gcc
I’m not using Gcc much, and at least in my industry (game development), it’s not very popular.
Out of all platforms that I happen to use at work, they are all on either Visual Studio or some variant of Clang. Gcc is only used on Linux, and
even there, there’s an option to use Clang.
Anyway, gcc has -ftime-report argument that prints information about where time was spent during compilation. Brace yourself,
this will be over 100 lines of text:
Time variable usr sys wall GGC
phase setup : 0.00 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 1509 kB ( 1%)
phase parsing : 0.59 ( 16%) 0.60 ( 43%) 2.35 ( 38%) 91628 kB ( 33%)
phase lang. deferred : 0.32 ( 9%) 0.16 ( 12%) 0.47 ( 8%) 46797 kB ( 17%)
phase opt and generate : 2.60 ( 72%) 0.62 ( 45%) 3.22 ( 53%) 132237 kB ( 48%)
phase last asm : 0.08 ( 2%) 0.00 ( 0%) 0.09 ( 1%) 2921 kB ( 1%)
|name lookup : 0.18 ( 5%) 0.10 ( 7%) 0.27 ( 4%) 4820 kB ( 2%)
|overload resolution : 0.13 ( 4%) 0.12 ( 9%) 0.31 ( 5%) 26374 kB ( 10%)
dump files : 0.08 ( 2%) 0.01 ( 1%) 0.04 ( 1%) 0 kB ( 0%)
callgraph construction : 0.08 ( 2%) 0.02 ( 1%) 0.11 ( 2%) 12160 kB ( 4%)
callgraph optimization : 0.02 ( 1%) 0.02 ( 1%) 0.04 ( 1%) 87 kB ( 0%)
ipa function summary : 0.00 ( 0%) 0.01 ( 1%) 0.02 ( 0%) 808 kB ( 0%)
ipa cp : 0.01 ( 0%) 0.01 ( 1%) 0.01 ( 0%) 564 kB ( 0%)
ipa inlining heuristics : 0.01 ( 0%) 0.00 ( 0%) 0.02 ( 0%) 807 kB ( 0%)
ipa function splitting : 0.01 ( 0%) 0.00 ( 0%) 0.02 ( 0%) 233 kB ( 0%)
ipa pure const : 0.02 ( 1%) 0.00 ( 0%) 0.01 ( 0%) 22 kB ( 0%)
ipa icf : 0.01 ( 0%) 0.00 ( 0%) 0.02 ( 0%) 0 kB ( 0%)
ipa SRA : 0.07 ( 2%) 0.02 ( 1%) 0.10 ( 2%) 6231 kB ( 2%)
ipa free inline summary : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 0 kB ( 0%)
cfg construction : 0.01 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 179 kB ( 0%)
cfg cleanup : 0.04 ( 1%) 0.00 ( 0%) 0.03 ( 0%) 200 kB ( 0%)
trivially dead code : 0.00 ( 0%) 0.00 ( 0%) 0.03 ( 0%) 1 kB ( 0%)
df scan insns : 0.02 ( 1%) 0.01 ( 1%) 0.01 ( 0%) 7 kB ( 0%)
df multiple defs : 0.00 ( 0%) 0.00 ( 0%) 0.02 ( 0%) 0 kB ( 0%)
df reaching defs : 0.01 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 0 kB ( 0%)
df live regs : 0.05 ( 1%) 0.01 ( 1%) 0.02 ( 0%) 26 kB ( 0%)
df live&initialized regs : 0.00 ( 0%) 0.01 ( 1%) 0.01 ( 0%) 0 kB ( 0%)
df use-def / def-use chains : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 0 kB ( 0%)
df reg dead/unused notes : 0.02 ( 1%) 0.00 ( 0%) 0.00 ( 0%) 510 kB ( 0%)
register information : 0.00 ( 0%) 0.00 ( 0%) 0.03 ( 0%) 0 kB ( 0%)
alias analysis : 0.02 ( 1%) 0.00 ( 0%) 0.04 ( 1%) 1258 kB ( 0%)
alias stmt walking : 0.05 ( 1%) 0.02 ( 1%) 0.06 ( 1%) 82 kB ( 0%)
preprocessing : 0.06 ( 2%) 0.15 ( 11%) 1.38 ( 23%) 2618 kB ( 1%)
parser (global) : 0.11 ( 3%) 0.19 ( 14%) 0.31 ( 5%) 27095 kB ( 10%)
parser struct body : 0.07 ( 2%) 0.03 ( 2%) 0.11 ( 2%) 14169 kB ( 5%)
parser enumerator list : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 94 kB ( 0%)
parser function body : 0.04 ( 1%) 0.06 ( 4%) 0.12 ( 2%) 4044 kB ( 1%)
parser inl. func. body : 0.03 ( 1%) 0.03 ( 2%) 0.02 ( 0%) 1952 kB ( 1%)
parser inl. meth. body : 0.09 ( 3%) 0.03 ( 2%) 0.11 ( 2%) 9238 kB ( 3%)
template instantiation : 0.47 ( 13%) 0.23 ( 17%) 0.71 ( 12%) 64835 kB ( 24%)
constant expression evaluation : 0.00 ( 0%) 0.02 ( 1%) 0.01 ( 0%) 225 kB ( 0%)
early inlining heuristics : 0.02 ( 1%) 0.01 ( 1%) 0.03 ( 0%) 1507 kB ( 1%)
inline parameters : 0.02 ( 1%) 0.00 ( 0%) 0.05 ( 1%) 4043 kB ( 1%)
integration : 0.25 ( 7%) 0.10 ( 7%) 0.23 ( 4%) 22167 kB ( 8%)
tree gimplify : 0.02 ( 1%) 0.02 ( 1%) 0.04 ( 1%) 6664 kB ( 2%)
tree eh : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 1039 kB ( 0%)
tree CFG construction : 0.01 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 2800 kB ( 1%)
tree CFG cleanup : 0.04 ( 1%) 0.02 ( 1%) 0.09 ( 1%) 62 kB ( 0%)
tree VRP : 0.08 ( 2%) 0.01 ( 1%) 0.03 ( 0%) 1672 kB ( 1%)
tree Early VRP : 0.02 ( 1%) 0.02 ( 1%) 0.02 ( 0%) 2084 kB ( 1%)
tree PTA : 0.07 ( 2%) 0.03 ( 2%) 0.08 ( 1%) 648 kB ( 0%)
tree SSA rewrite : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 2156 kB ( 1%)
tree SSA other : 0.01 ( 0%) 0.01 ( 1%) 0.03 ( 0%) 282 kB ( 0%)
tree SSA incremental : 0.02 ( 1%) 0.00 ( 0%) 0.02 ( 0%) 393 kB ( 0%)
tree operand scan : 0.07 ( 2%) 0.05 ( 4%) 0.12 ( 2%) 7305 kB ( 3%)
dominator optimization : 0.11 ( 3%) 0.00 ( 0%) 0.13 ( 2%) 1428 kB ( 1%)
backwards jump threading : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 248 kB ( 0%)
tree SRA : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 385 kB ( 0%)
tree CCP : 0.04 ( 1%) 0.01 ( 1%) 0.04 ( 1%) 413 kB ( 0%)
tree PRE : 0.00 ( 0%) 0.01 ( 1%) 0.06 ( 1%) 1057 kB ( 0%)
tree FRE : 0.06 ( 2%) 0.05 ( 4%) 0.05 ( 1%) 670 kB ( 0%)
tree forward propagate : 0.02 ( 1%) 0.00 ( 0%) 0.01 ( 0%) 454 kB ( 0%)
tree phiprop : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 7 kB ( 0%)
tree conservative DCE : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 45 kB ( 0%)
tree aggressive DCE : 0.03 ( 1%) 0.01 ( 1%) 0.04 ( 1%) 2337 kB ( 1%)
tree DSE : 0.01 ( 0%) 0.01 ( 1%) 0.02 ( 0%) 32 kB ( 0%)
tree loop invariant motion : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 1 kB ( 0%)
complete unrolling : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 417 kB ( 0%)
tree iv optimization : 0.01 ( 0%) 0.01 ( 1%) 0.02 ( 0%) 705 kB ( 0%)
tree switch conversion : 0.00 ( 0%) 0.01 ( 1%) 0.00 ( 0%) 0 kB ( 0%)
tree strlen optimization : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 2 kB ( 0%)
dominance computation : 0.02 ( 1%) 0.00 ( 0%) 0.06 ( 1%) 0 kB ( 0%)
out of ssa : 0.00 ( 0%) 0.01 ( 1%) 0.01 ( 0%) 15 kB ( 0%)
expand vars : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 351 kB ( 0%)
expand : 0.04 ( 1%) 0.01 ( 1%) 0.02 ( 0%) 8842 kB ( 3%)
post expand cleanups : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 285 kB ( 0%)
forward prop : 0.04 ( 1%) 0.00 ( 0%) 0.02 ( 0%) 375 kB ( 0%)
CSE : 0.02 ( 1%) 0.01 ( 1%) 0.11 ( 2%) 141 kB ( 0%)
dead code elimination : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 0 kB ( 0%)
dead store elim1 : 0.03 ( 1%) 0.00 ( 0%) 0.02 ( 0%) 415 kB ( 0%)
dead store elim2 : 0.02 ( 1%) 0.00 ( 0%) 0.04 ( 1%) 630 kB ( 0%)
loop init : 0.01 ( 0%) 0.01 ( 1%) 0.03 ( 0%) 2511 kB ( 1%)
loop fini : 0.02 ( 1%) 0.00 ( 0%) 0.00 ( 0%) 0 kB ( 0%)
CPROP : 0.04 ( 1%) 0.00 ( 0%) 0.06 ( 1%) 619 kB ( 0%)
PRE : 0.01 ( 0%) 0.00 ( 0%) 0.02 ( 0%) 103 kB ( 0%)
CSE 2 : 0.01 ( 0%) 0.01 ( 1%) 0.03 ( 0%) 83 kB ( 0%)
branch prediction : 0.01 ( 0%) 0.00 ( 0%) 0.02 ( 0%) 413 kB ( 0%)
combiner : 0.03 ( 1%) 0.00 ( 0%) 0.03 ( 0%) 1112 kB ( 0%)
if-conversion : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 64 kB ( 0%)
integrated RA : 0.09 ( 3%) 0.01 ( 1%) 0.05 ( 1%) 5912 kB ( 2%)
LRA non-specific : 0.06 ( 2%) 0.00 ( 0%) 0.03 ( 0%) 305 kB ( 0%)
LRA create live ranges : 0.02 ( 1%) 0.00 ( 0%) 0.02 ( 0%) 41 kB ( 0%)
LRA hard reg assignment : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 0 kB ( 0%)
reload : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 0 kB ( 0%)
reload CSE regs : 0.02 ( 1%) 0.00 ( 0%) 0.03 ( 0%) 571 kB ( 0%)
ree : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 8 kB ( 0%)
thread pro- & epilogue : 0.03 ( 1%) 0.00 ( 0%) 0.03 ( 0%) 460 kB ( 0%)
peephole 2 : 0.02 ( 1%) 0.00 ( 0%) 0.02 ( 0%) 41 kB ( 0%)
hard reg cprop : 0.00 ( 0%) 0.00 ( 0%) 0.02 ( 0%) 17 kB ( 0%)
scheduling 2 : 0.15 ( 4%) 0.01 ( 1%) 0.16 ( 3%) 335 kB ( 0%)
reorder blocks : 0.01 ( 0%) 0.00 ( 0%) 0.02 ( 0%) 294 kB ( 0%)
shorten branches : 0.01 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 0 kB ( 0%)
final : 0.04 ( 1%) 0.01 ( 1%) 0.04 ( 1%) 4707 kB ( 2%)
symout : 0.15 ( 4%) 0.02 ( 1%) 0.17 ( 3%) 26953 kB ( 10%)
variable tracking : 0.03 ( 1%) 0.00 ( 0%) 0.02 ( 0%) 2416 kB ( 1%)
var-tracking dataflow : 0.03 ( 1%) 0.00 ( 0%) 0.09 ( 1%) 74 kB ( 0%)
var-tracking emit : 0.05 ( 1%) 0.00 ( 0%) 0.08 ( 1%) 4059 kB ( 1%)
tree if-combine : 0.00 ( 0%) 0.00 ( 0%) 0.02 ( 0%) 10 kB ( 0%)
straight-line strength reduction : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 11 kB ( 0%)
store merging : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 61 kB ( 0%)
initialize rtl : 0.00 ( 0%) 0.00 ( 0%) 0.01 ( 0%) 12 kB ( 0%)
early local passes : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 0 kB ( 0%)
rest of compilation : 0.13 ( 4%) 0.02 ( 1%) 0.12 ( 2%) 731 kB ( 0%)
remove unused locals : 0.01 ( 0%) 0.00 ( 0%) 0.05 ( 1%) 3 kB ( 0%)
address taken : 0.01 ( 0%) 0.00 ( 0%) 0.00 ( 0%) 0 kB ( 0%)
repair loop structures : 0.02 ( 1%) 0.00 ( 0%) 0.00 ( 0%) 3 kB ( 0%)
TOTAL : 3.59 1.38 6.13 275104 kB
Ok, I guess that totally makes sense, if you are a compiler developer working on gcc itself. But I’m not! Most of
the above either does not mean anything to me, or I don’t really care about it.
- I don’t care that much about “user” or “system” time; I care about how much time I had to wait for compilation
to finish (“wall time”). Why it is in the middle of each row?
- Is this output sorted by something? It’s not sorted from “most expensive” to “least expensive”. Not sorted
alphabetically either. I guess it’s sorted by some internal structure that is not obvious to me.
- I think the
phase parsing is “generally frontend”, and phase opt and generate is “generally backend”; these are good to know.
Then later on there’s a more detailed preprocessing to template instantiation which is frontend in more detail;
that’s useful too. The rest? Besides some names that mean some optimization passes, many are cryptic to me, and I’m
not sure why I should care about them. tree eh? Eh indeed.
- Memory usage numbers are interesting to compiler developers, and maybe are useful to users that are under memory-constrained
situations (like 32 bit systems etc.). Me? I don’t really care.
So, while the gcc -ftime-report prints something, and some of that is very useful (template instantiation time; preprocessing time;
time spent performing inlining etc.), it seems to be geared towards compiler developers, and less towards users.
Again - if I’m investigating compile times of my code, the question I have is what can I change in my code to make it compile faster?
Ideally some tool should be able to tell me both what takes time, and where in the code it does it.
Clang
Clang, being the most “fresh” of all these compilers, should be the most excellent, right? Right? :)
Just like gcc, it also has -ftime-report option. That produces 900 lines of output! Instead of pasting it in full here,
I’ll just link to it.
Several things to note:
- Almost half of it is just the same information, duplicated? “Register Allocation”, “Instruction Selection and Scheduling”,
“DWARF Emission” and “… Pass execution timing report …” sections are just emitted twice, but curiously enough, the
other sections are printed just once. This sounds like a bug to me, and testing out various Clang versions in Compiler Explorer
suggests that it started with Clang 7.0.0 and still exists on today’s 8.0.0-trunk. I’ve reported it.
- Within the “Pass Execution Timing Report” section, there’s a bunch of items that are repeated multiple times too, e.g.
“Combine redundant instructions” is listed 8 times; and “Function Alias Analysis Results” is listed 21 times.
I’ve no idea if that’s a bug or not; I think I don’t care about them anyway.
- It suffers from the same “oriented to clang compiler developers, and not clang users” that gcc time report does.
I really don’t care about all the LLVM optimization passes you ended up doing; and similarly I don’t care
about user vs system times or memory usage.
If it stopped printing all the info I don’t care about, did not duplicate half of it, and stopped printing LLVM passes after top 5 most
expensive ones, it would already be way more legible, e.g. like this:
===-------------------------------------------------------------------------===
Miscellaneous Ungrouped Timers
===-------------------------------------------------------------------------===
---Wall Time--- --- Name ---
4.1943 ( 93.7%) Code Generation Time
0.2808 ( 6.3%) LLVM IR Generation Time
4.4751 (100.0%) Total
===-------------------------------------------------------------------------===
Register Allocation
===-------------------------------------------------------------------------===
Total Execution Time: 0.0180 seconds (0.0181 wall clock)
===-------------------------------------------------------------------------===
Instruction Selection and Scheduling
===-------------------------------------------------------------------------===
Total Execution Time: 0.2894 seconds (0.2894 wall clock)
===-------------------------------------------------------------------------===
DWARF Emission
===-------------------------------------------------------------------------===
Total Execution Time: 0.3599 seconds (0.3450 wall clock)
===-------------------------------------------------------------------------===
... Pass execution timing report ...
===-------------------------------------------------------------------------===
Total Execution Time: 3.5271 seconds (3.5085 wall clock)
---Wall Time--- --- Name ---
0.4859 ( 13.8%) X86 Assembly Printer
0.4388 ( 12.5%) X86 DAG->DAG Instruction Selection
0.2633 ( 7.5%) Function Integration/Inlining
0.1228 ( 3.5%) Global Value Numbering
0.0695 ( 2.0%) Combine redundant instructions
3.5085 (100.0%) Total
===-------------------------------------------------------------------------===
Clang front-end time report
===-------------------------------------------------------------------------===
Total Execution Time: 5.2175 seconds (6.3410 wall clock)
---Wall Time--- --- Name ---
6.3410 (100.0%) Clang front-end timer
6.3410 (100.0%) Total
(also, please, drop the “…” around “Pass execution timing report” name; why it is there?)
And then the various “Total” under the sections are quite a bit confusing. Let’s see:
- “Clang front-end time report” seems to be time for “everything”, not just the frontend (Clang frontend, LLVM backend, and whatever else it did).
- I think the “backend” (LLVM) total part is under “Misc Ungrouped Timers, Code Generation Time”. This is probably
what is “Pass execution timing” + “Register Allocation” + “Instruction Selection and Scheduling” etc.
- So probably the actual Clang “frontend” (preprocessor, parsing – i.e. doing the C++ bits of the compilation)
I could get by subtracting various LLVM related timer bits from the total time. Ugh. Could you just tell me that time please?
Another thing to note: in all the optimization passes, “X86 Assembly Printer” seems to be the heaviest one? That doesn’t sound
right. So I dug in a bit… turns out, once you pass -ftime-report flag, then the whole compilation time is heavily affected.
It grows from 1.06s to 1.42s in that super simple STL snippet above, and from 16s to 26s in a much heavier source file I had.
Normally for any sort of profiling tool I’d expect at max a couple percent overhead, but Clang’s time report seems to make
compilation take 1.5x longer! This sounds like a bug to me, so… reported!
From a quick look, it feels like this could primarily be caused by code in AsmPrinter.cpp that adds time sampling around
each and every assembly instruction that was generated
(AsmPrinter.cpp, line 1087);
this seems like it’s inside a loop that processes all the instructions. Taking that many timing samples probably does not end up
being very fast, and thus heavily slows down the “X86 Assembly Printer” pass, when -ftime-report flag is used.
And each time sample capture itself seems to end up doing:
But dear clang! I only care about single “elapsed time”; you could replace all that complexity with a single
*_clock::now call and be done with it.
Even if presence of -ftime-report did not distort the compile times so much, Clang’s current implementation leaves much to be desired.
It does not even tell me “how much time I spent parsing C++ code”, for example (without me manually doing the math), and does not tell
other important aspects like “how much time I spent instantiating templates”. And just like gcc time report, it never tells where in my code
the expensive parts actually are.
But surely someone would have solved this already?
I thought so too! But that doesn’t seem to be the case.
For Clang, various people have proposed changes or submitted patches to improve time report in some ways, for example:
- This patch by Eddie Elizondo adds template instantiation timers. Done in August 2017, everyone in discussion
agreed it’s a good idea. Now it’s January 2019…
- This patch by Brian Gesiak added preprocessor timer in August 2017 too. After some back and forth
discussion, eventually abandoned since someone else (Andrew Tischenko) said he’ll implement it in a better way. That was 2018 February.
Other people have built tools that are similar to clang, but are separate programs. For example, Templight
by Sven Mikael Persson – it works just like Clang, but invoked with additional arguments dumps detailed information
about all template instantiations into a separate file, that can then be converted into various other formats for visualization.
Templight does look promising, but a bit unwieldy to use, and only covers the template instantiation aspect. What if my compile
time issues are somewhere else?
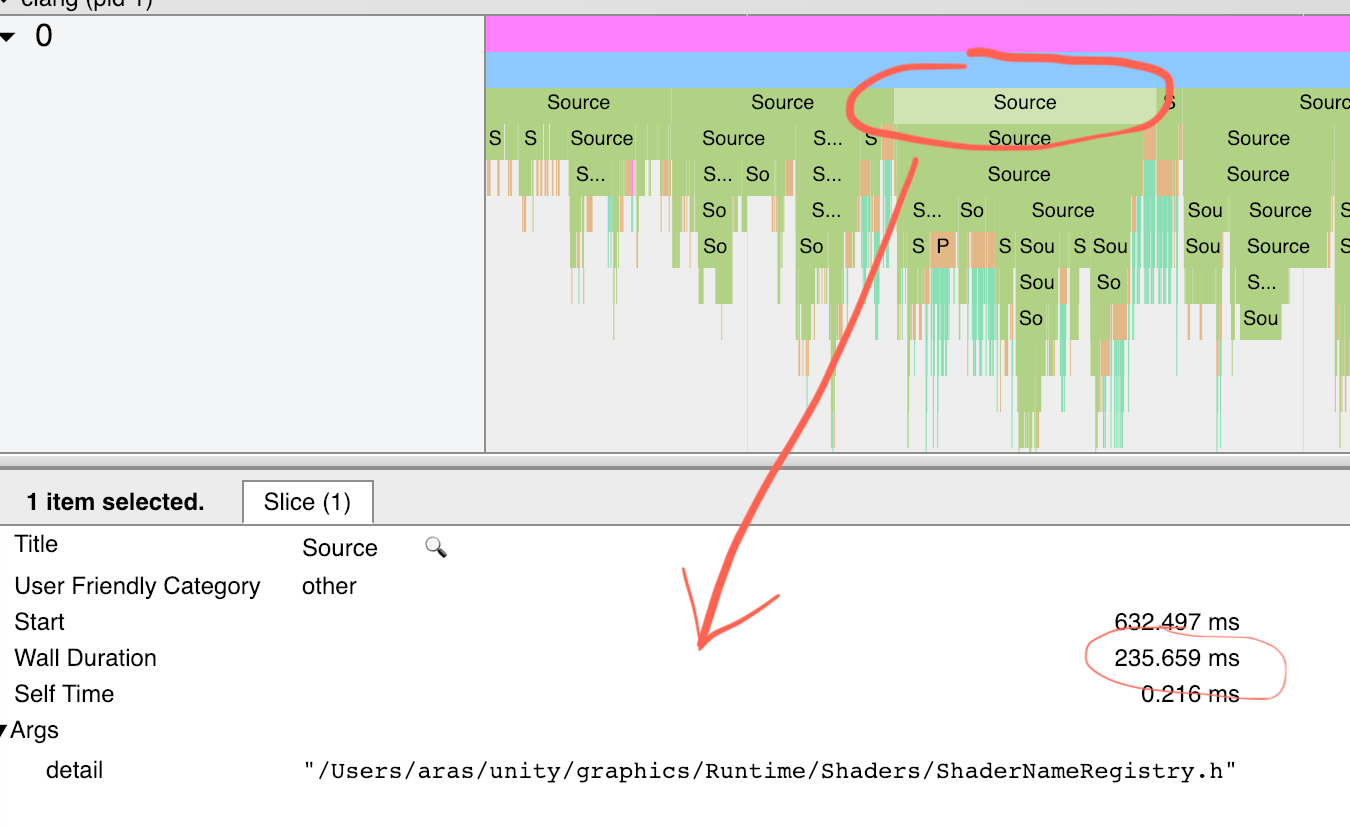
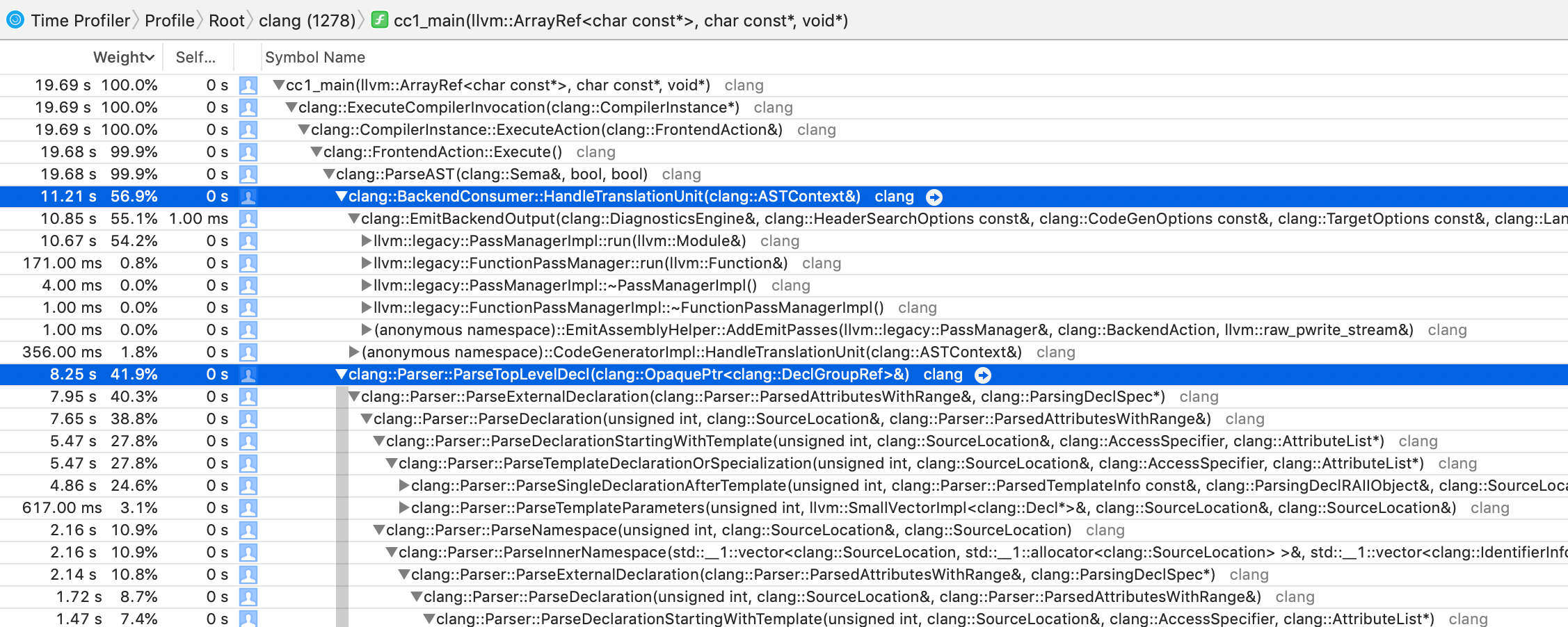
So I have spent a bit of time trying to make Clang do a “more useful for me” time report. It already pointed out one seemingly simple
header file that we had, that was causing Clang to take “ages” (5-8 seconds) just including it, due to some recursive macro usage
that Clang isn’t fast to plow through. Yay tools!
What I did and how it works will be in the next blog post!
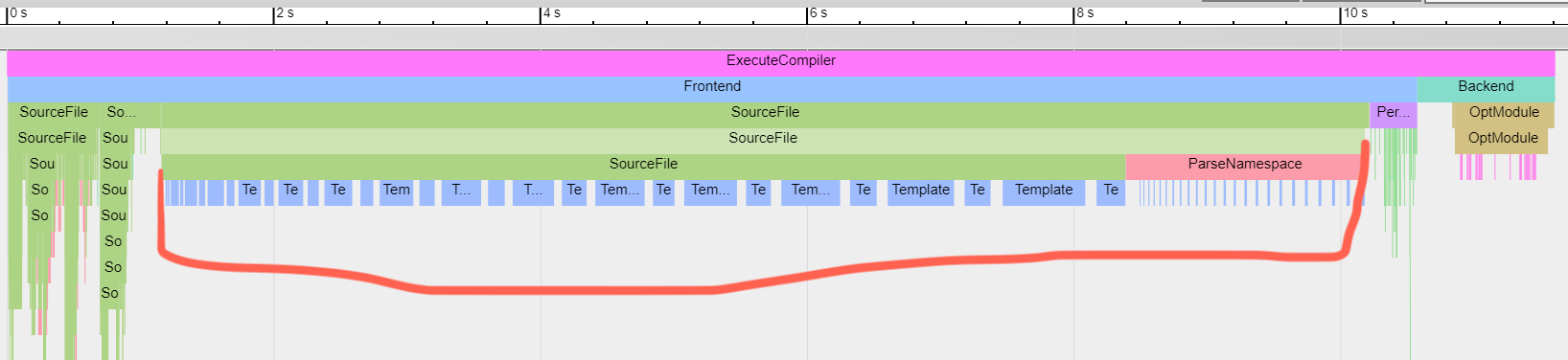
But maybe you can guess on what it might be from my past blog posts (here
or here), and from this teaser image:

Stay tuned! Update: next blog post is out.