Texture Compression on Apple M1
In the previous post I did a survey of various GPU format compression libraries. I just got an Apple M1 MacMini to help port some of these compression libraries to it, and of course decided to see some performance numbers. As everyone already noticed, M1 CPU is quite impressive. I’m comparing three setups here:
- MacBookPro (2019 16", 8 cores / 16 threads). This is basically the “top” MacBook Pro you can get in 2020, with 9th generation Coffee Lake Core i9 9980HK CPU. It starts at $3000 for this CPU.
- MacMini (M1, 4 perf + 4 efficiency cores). It starts at $700 for this CPU (but realistically you’d want maybe a $1300 model for more decent RAM/SSD sizes).
- The same MacMini, but testing Intel/x64 builds of the compressors under Rosetta 2 translator.
Multi-threaded compression
Here we’re compressing a bunch of textures into various GPU formats, using various compression libraries, and various quality settings of those. See previous post for details. The tests are done by using all the CPU cores, and results are in millions of pixels per second (higher = better).
Desktop BC7 format, using ISPCTextureCompressor and
bc7e libraries:
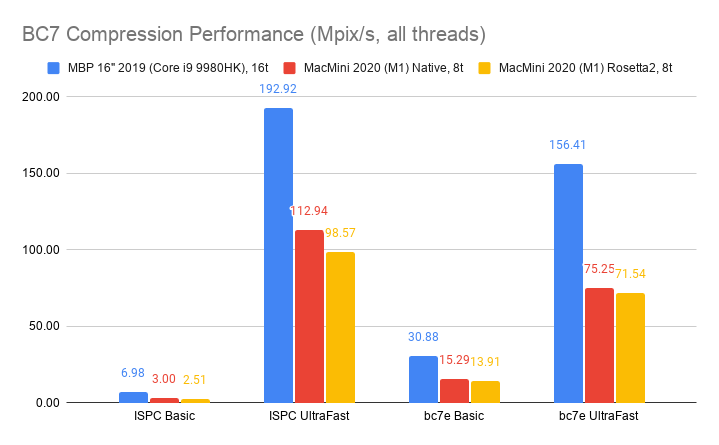
Desktop BC1/BC3 (aka DXT1/DXT5) format, using ISPCTextureCompressor
and stb_dxt libraries:
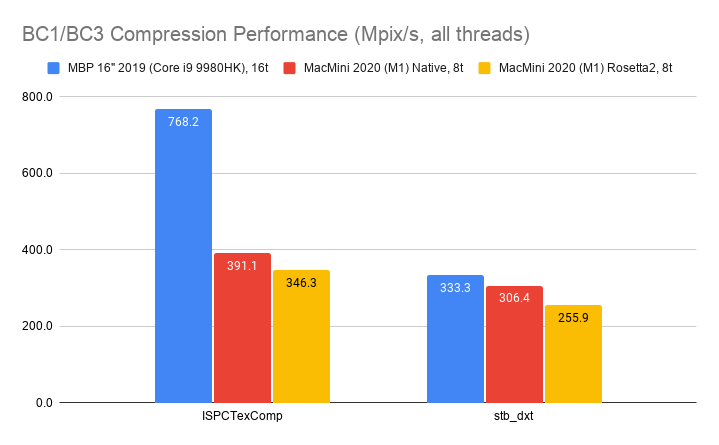
Mobile ASTC 4x4 format, using ISPCTextureCompressor and astcenc (2.3-ish) libraries:
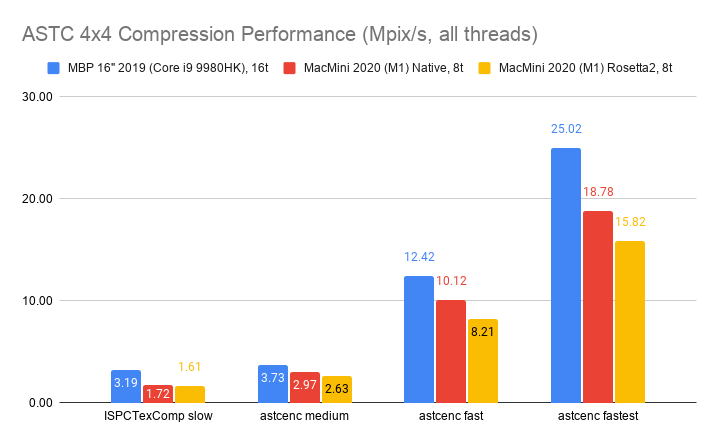
Mobile ETC2 format, using Etc2Comp and etcpak
libraries:
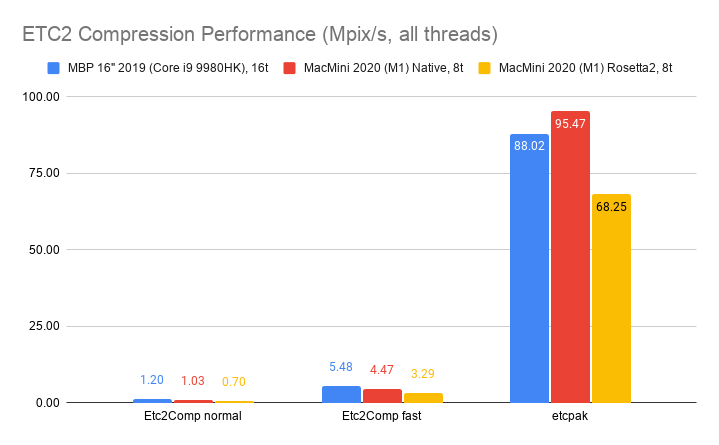
Overall the 2019 MacBookPro is from “a bit faster” to “about twice as fast” as the M1, when compression is fully multi-threaded. This makes sense due to two things:
- 2019 MBP uses 16 threads, whereas M1 uses 8 threads. In both cases these are not “100% the same” threads, since the former only has 8 “real” cores, with two SMT threads per core; and the latter has 4 “high performance” cores and 4 “low power” cores. But with some squinting we should probably expect MBP to be almost 2x faster overall, just due to higher CPU thread count.
- Some of the texture compressors (
ISPCTexComp,bc7e) use AVX2 code paths for “almost ideal” speedup, meaning the full compression algorithm is fully SIMD, using AVX2 8-wide execution when available. These compressors are written in ISPC language. M1 on the other hand, only has 4-wide SIMD execution (via NEON). If a program can take really good advantage of wider SIMD, then Intel CPU has an advantage there.
Summary: on all-cores texture compression, 2019 MBP is about 2x faster than M1, for compressors written with ISPC (ISPCTexComp, bc7e)
that take really good advantage of AVX2. In other compressors, 2019 MBP is “a bit” faster. ETC2 etcpak compressor has M1 faster
than 2019 MBP.
Rosetta 2 translator for x64/SSE works impressively well, reaching ~70-90% performance of natively compiled Arm+NEON code.
Single-threaded compression
Ok, what if we limited compression to a single CPU thread? For texture compression itself that does not make a whole lot of sense, but it’s interesting to see how 2019 MBP and M1 compare without the “MBP has more threads” advantage. You could maybe extrapolate how M1 CPU would behave if it had more cores.
Same formats and compressors as above, just single threaded everywhere:
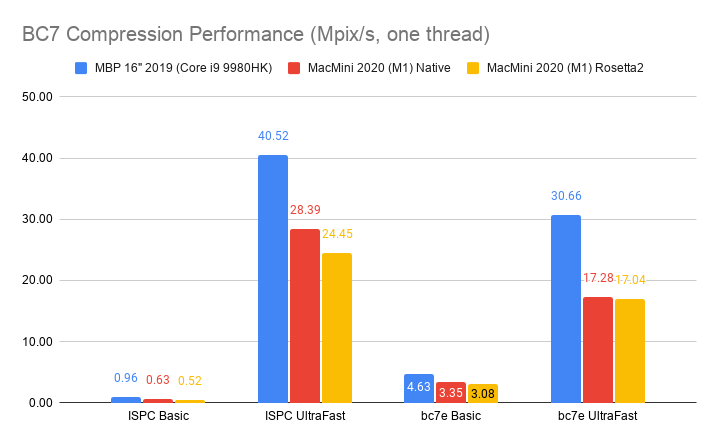
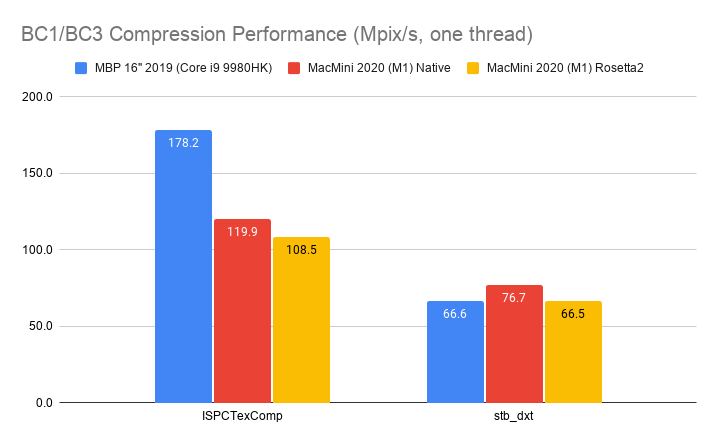
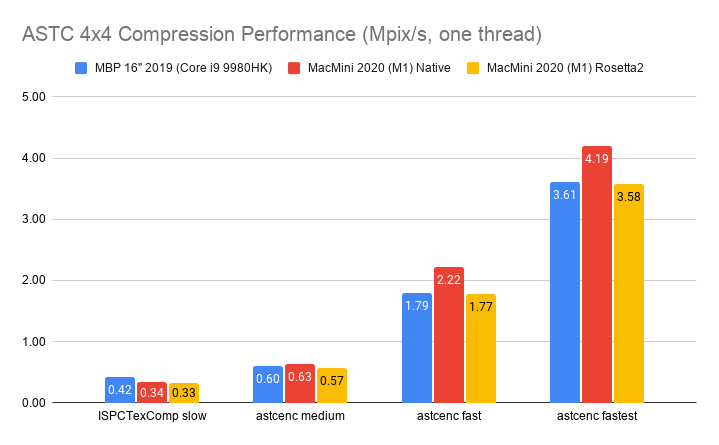
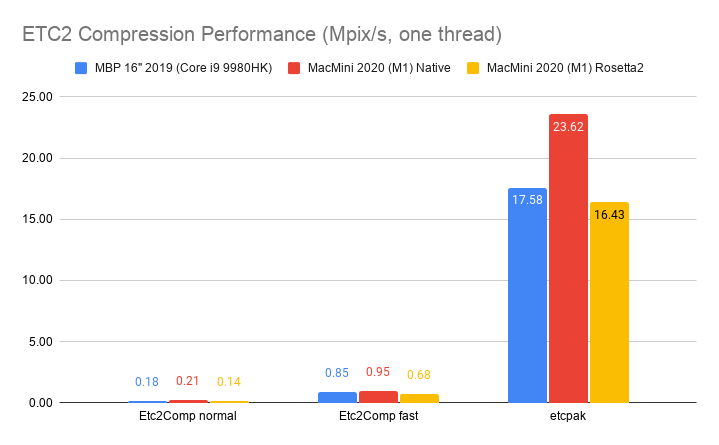
Here it’s basically: if a compressor is fully SIMD with AVX2 (ISPCTexComp, bc7e), then 2019 MBP is 1.5x faster than M1.
Otherwise M1 is a bit faster.
Multi-thread speedup
Once we have multi-threaded and single-thread numbers, we can see what’s the effective speedup from using all the CPU cores. Ideally 2019 MBP would be 16x faster, and M1 would be 8x faster, since that’s the amount of threads we’re distributing the work to. In practice, as mentioned above, not all of these threads are fully independent or equal. And the computation could hit some other limits, e.g. RAM bandwidth and so on. Anyway, what’s the effective speedup for texture compression, when using all the CPU cores?
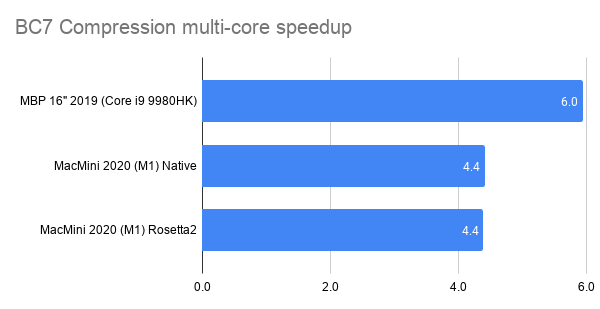
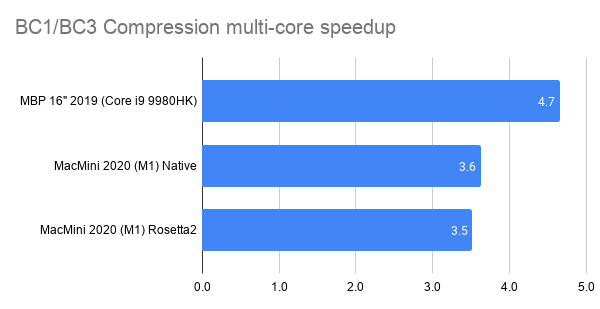
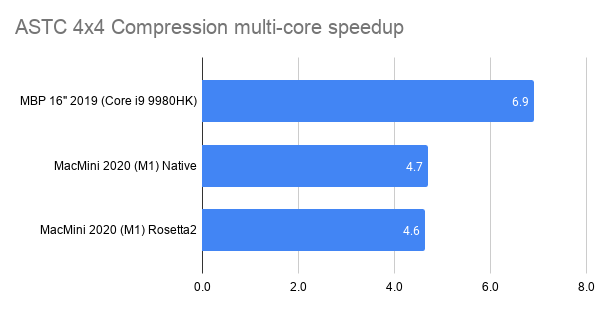
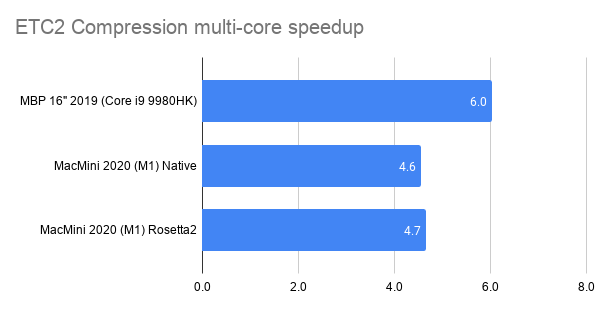
- 2019 MacBook Pro is ~6x faster from using all cores. This one’s curious, since it’s even below the “full 8 cores” scaling. Maybe loading all the SMT threads ends up doing more harm than good here, or we’re hitting some other bottleneck that prevents further scaling.
- M1 is ~4.5x faster from using all cores. This either means there’s a fairly large performance difference between “performance” and “efficiency” cores, or we’re hitting some other bottleneck.
Anyway, that’s it! Now I’m curious to see what the next iteration of Apple CPUs will look like. M1 is impressive!