EXR: Zstandard compression
In the previous blog post I looked at OpenEXR Zip compression level settings.
Now, Zip compression algorithm (DEFLATE) has one good thing going for it: it’s everywhere. However, it is also from the year 1993, and both the compression algorithm world and the hardware has moved on quite a bit since then :) These days, if one were to look for a good, general purpose, freely available lossless compression algorithm, the answer seems to be either Zstandard or LZ4, both by Yann Collet.
Let’s look into Zstandard then!
Initial (bad) attempt
Some quick hacky plumbing of Zstd (version 1.5.0) into OpenEXR, here’s what we get:
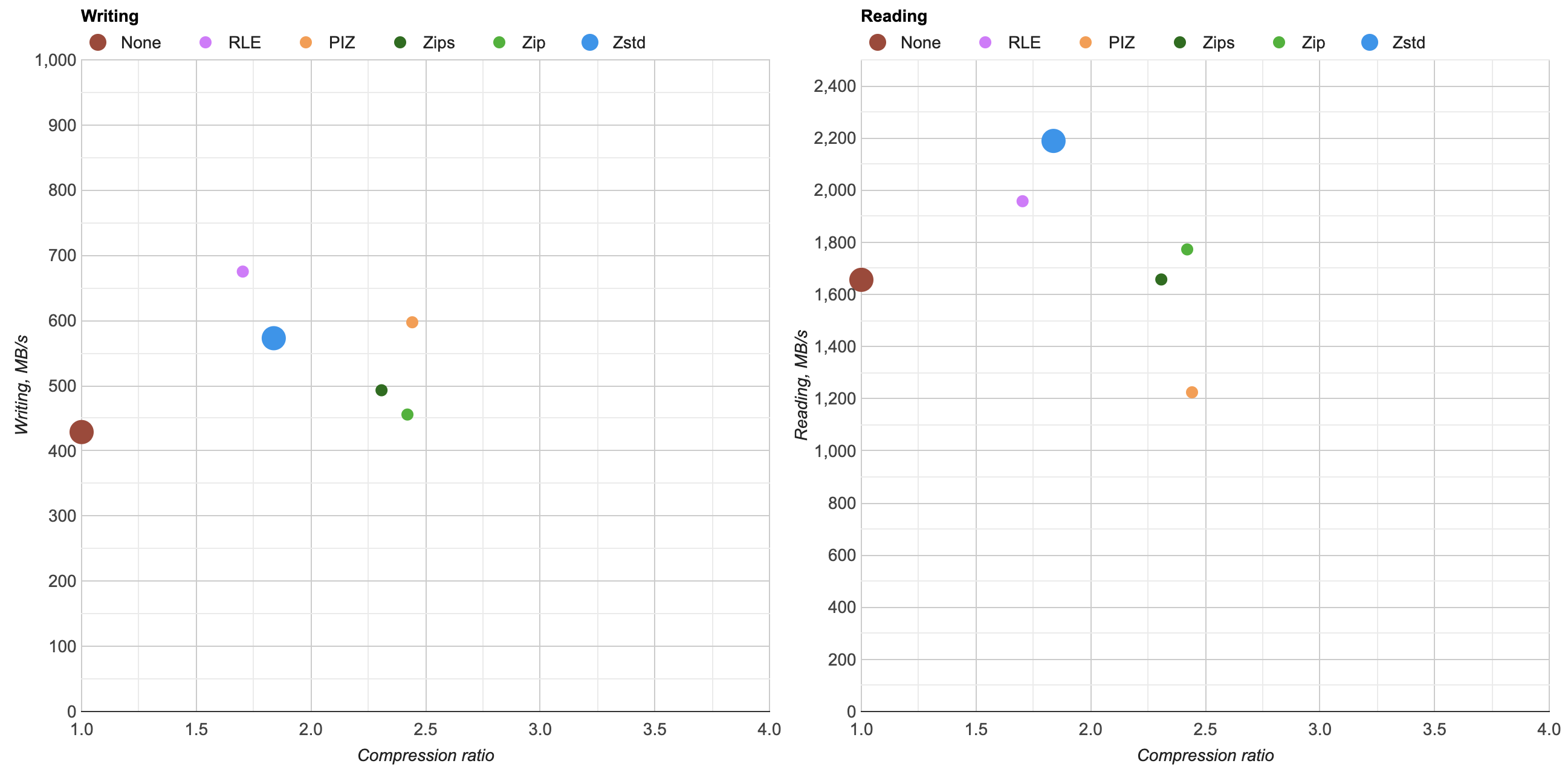
Zip/Zips has been bumped from previous compression level 6 to level 4 (see previous post), the new Zstandard is the large blue data point. Ok that’s not terrible, but also quite curious:
- Both compression and decompression performance is better than Zip, which is expected.
- However, that compression ratio? Not great at all. Zip and PIZ are both at ~2.4x compression, whereas Zstd only reaches 1.8x. Hmpft!
Turns out, OpenEXR does not simply just “zip the pixel data”. Quite similar to how e.g. PNG does it, it first filters the data, and then compresses it. When decompressing, it first decompresses and then does the reverse filtering process.
In OpenEXR, here’s what looks to be happening:
- First the incoming data is split into two parts;
first all the odd-indexed bytes, then all the even-indexed bytes. My guess
is that this is based on assumption that 16-bit float is going to
be the dominant input data type, and splitting it into “first all the lower bytes, then all the higher bytes” does improve compression
when a general purpose compressor is used.
- That got me thinking: EXR also supports 32-bit float and 32-bit integer pixel data types. However here for compression, they are still split into two parts, as if data is 16-bit sized. This does not cause any correctness issues, but I’m wondering whether it might be slightly suboptimal for compression ratio.
- Then the resulting byte stream is delta encoded;
e.g. this turns a byte sequence like
{ 1, 2, 3, 4, 5, 6, 4, 2, 0 }(not very compressible) into{ 1, 129, 129, 129, 129, 129, 126, 126, 126 }which is much tastier for a compressor.
Let’s try doing exactly the same data filtering for Zstandard too:
Zstd with filtering
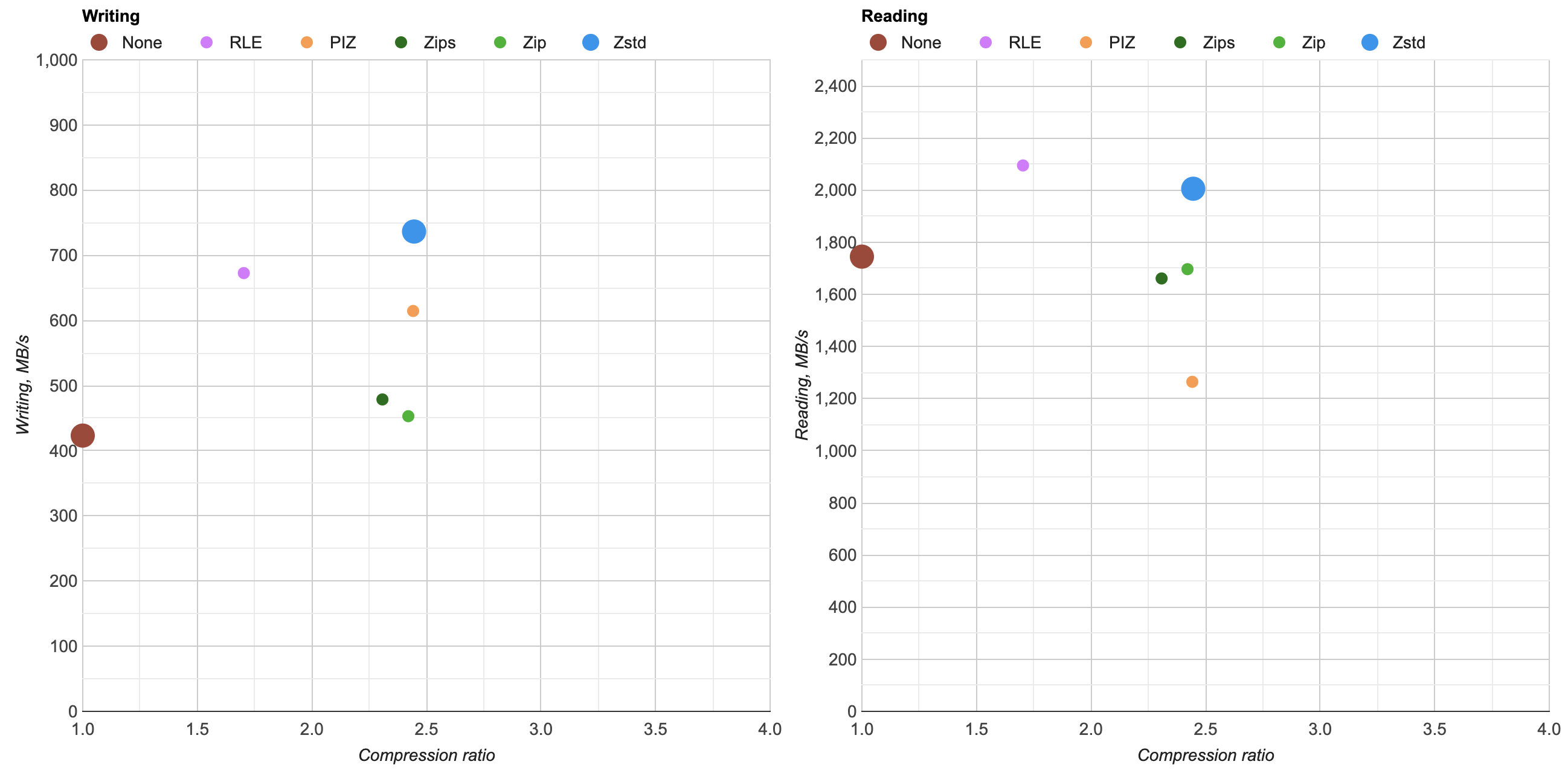
Look at that! Zstd sweeps all others away!
- Ratio: 2.446x for Zstd, 2.442x for PIZ, 2.421x for Zip. These are actually very close to each other.
- Writing: At 735MB/s, Zstd is fastest of all, by far. 1.7x faster than uncompressed or Zip, and handily winning against previous “fast to write, good ratio” PIZ. And it would be 3.6x faster than previous Zip at compression level 6.
- Reading: At 2005MB/s, Zstd almost reaches RLE reading performance, is a bit faster to read than uncompressed (1744MB/s) or Zip (1697MB/s), and quite a bit faster than PIZ (1264MB/s).
Zstd also has various compression levels; the above chart is using the default (3) level. Let’s look at those.
Zstd compression levels
We have much more compression levels to choose from compared to Zip – there are “regular levels” between 1 and 22, but also negative levels that drop quite a bit of compression ratio in hopes to increase performance (this makes Zstd almost reach into LZ4 territory). Here’s a chart (click for an interactive page) where I tried most of them:
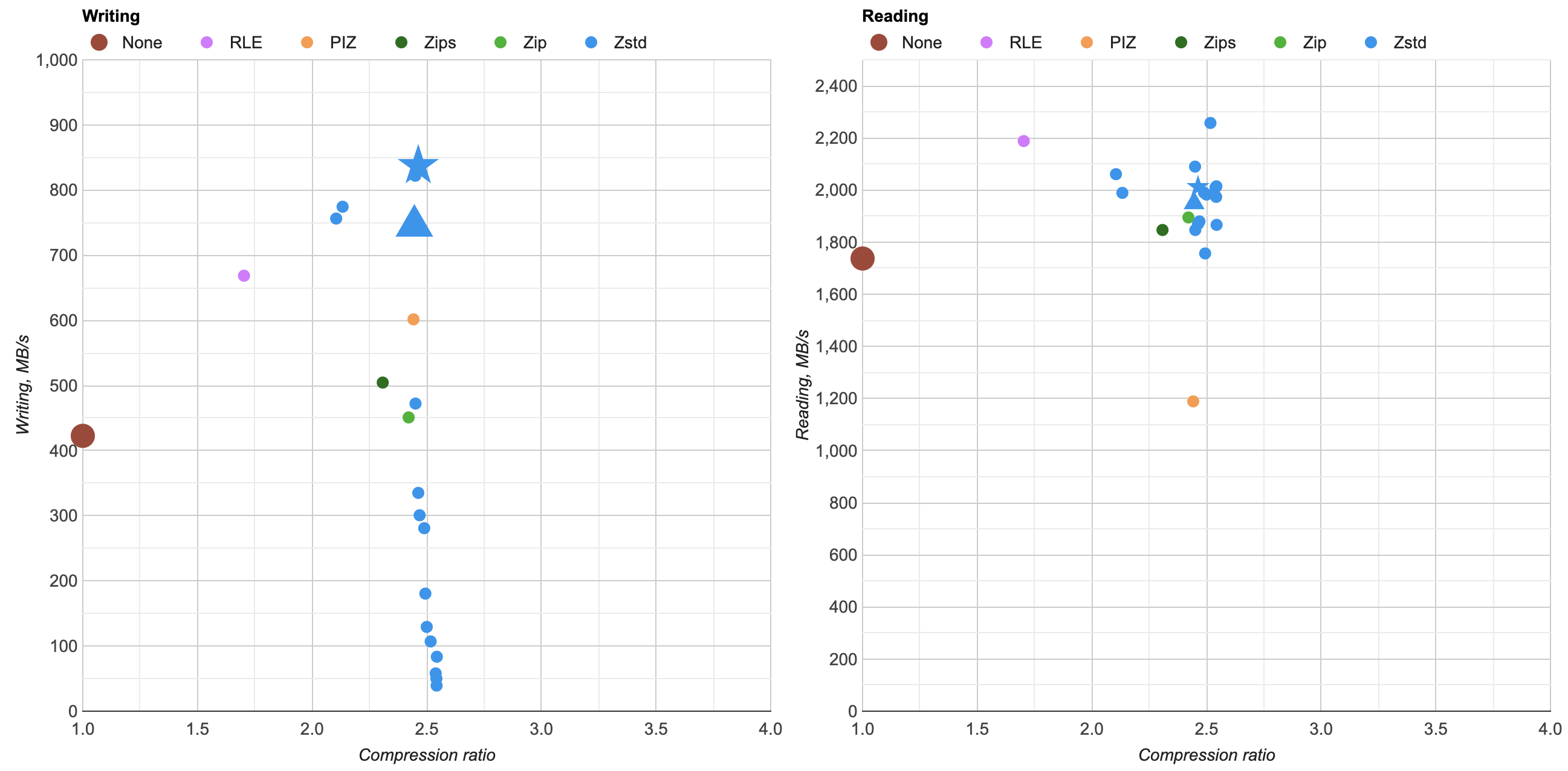
- Negative levels (-1 and -3 in the chart) don’t seem to be worth it: compression ratio drops significantly (from 2.4-2.5x down to 2.1x) and they don’t buy any additional performance. I guess the compression itself might be faster, but the increased file size makes it slower to write, so they cancel each other out.
- There isn’t much compression ratio changes between the levels – it varies between 2.446x (level 3) up to 2.544x (level 16). Slightly more variation than Zip, but not much. Levels beyond 10 get into “really slow” territory without buying much more ratio.
- Level 1 looks better than default Level 3 in all aspects: quite a bit faster to write (745 -> 837 MB/s), and curiously enough slightly
better compression ratio too (2.446x -> 2.463x)! Zstd with level 1 looks quite excellent (marked with a star shape point in the graph):
- Writing: 2.0x faster than uncompressed, 1.9x faster than Zip, 1.4x faster than PIZ.
- Reading: 1.16x faster than uncompressed, 1.06x faster than Zip, 1.7x faster than PIZ.
- Ratio: a tiny bit better than either Zip or PIZ, but all of them about 2.4x really.
Next up?
I’ll report these findings to “Investigate additional compression” OpenEXR github issue, and see if someone says that Zstd makes sense to add (maybe? TIFF added it in v4.0.10 back in year 2017…). If it does, then most of the work will be “ok how to properly do that with their CMake/Bazel/whatever build system”; C++ projects are always “fun” in that regard, aren’t they.
Maybe it would be worth looking at some different filter than the one used by Zip (particularly for 32-bit float/integer images) too?
I also want to look into more specialized compression schemes, besides just “let’s throw something better than zlib at the thing” :)
Update: next blog post turned out to be about libdeflate.