At work we switched to Mercurial almost two months ago. Like Richard says, it was time to stop using Subversion. Here are my impressions so far.
_Preemptive warning: I’ve only ever used CVS, SourceSafe, Subversion, git and Mercurial as source contro systems (never used Perforce). I never really used a code review tool before Kiln. Everything below might be non-issues in other tools/systems, or not suitable for different setups/workflows!
_
The Story
At Unity we used Subversion for source code versioning as long as I remember. svn revision 1 – an import from CVS – happened in 2005. We don’t talk about CVS. Nor about SourceSafe. Subversion was fine while the number of developers was small; we had a saying that CVS scales up to 5 people, and experimentally found out that svn scales up to about 50.
Since merging branches in subversion does not really work well, everyone was mostly working on one trunk, carefully. We would do an occasional branch for “this will surely break everything” features; and would branch off trunk sometime before each Unity release, but that’s about it. Having something like 50 people and 10 platforms on a single branch in version control does get a bit uneasy.
So we looked at various options, like git, Mercurial, Perforce and so on. I don’t know why exactly we ended up with Mercurial (someone made a decision I guess…). It felt like distributed versioning systems are teh future and unlike most game developers we don’t need to version hundreds of gigabytes of binary assets (hence no big need for Perforce).
So while some people were at GDC, we did a big switch to several things at once: 1) replace Subversion with Mercurial, 2) replace “everyone works on the same trunk” workflow with “teams work on their own topic branches”, 3) introduce a bit more formal code reviews via Kiln.
In hindsight, maybe switching three things at once wasn’t the brightest idea; there’s only so much change a person can absorb per unit of time. On the other hand, everyone experienced a large initial shock but now that the debris is setting down they just continue working with no big shocks predicted in the near future.
Our Setup
We use Fogcreek’s Kiln and host it on our own servers. This is mostly for legal reasons I think (in our source code we have 3rd party bits which are under strict NDAs). Advantage of hosting ourselves is that we’re under complete control. Disadvantage is that we have to do some work; and we only get Kiln updates each couple of months (so for example everyone who lets Fogcreek host Kiln is on Kiln 2.4.x right now, while we’re still on 2.3.x).
Our source tree is about 12000 files amounting to about 600MB. Mercurial’s history (60000 revisions imported from svn) adds another 200MB. Additionally, we pull almost 1GB of binary files (see below for binary file versioning) into the source tree.
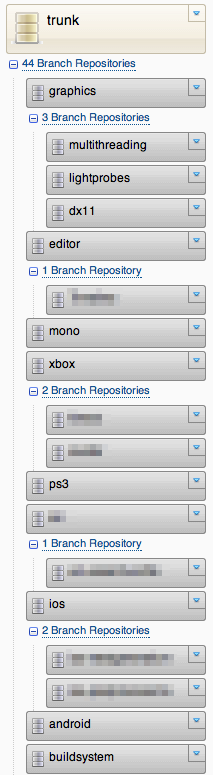
 Each “team” (core, editor, graphics, ios, android, …) has it’s own “branch” (actually, a separate repository clone) of the codebase, and merge back and forth between “trunk” repository. The trunk is supposed to be stable and shippable at almost any time (in theory… :)); unfinished, unreviewed code or code that has any failing tests can’t be pushed into trunk. Additionally, long-lasting features get their own “feature branches” (again, actually full clones of the repository). So right now we have more than 40 of those team+feature branches.
Each “team” (core, editor, graphics, ios, android, …) has it’s own “branch” (actually, a separate repository clone) of the codebase, and merge back and forth between “trunk” repository. The trunk is supposed to be stable and shippable at almost any time (in theory… :)); unfinished, unreviewed code or code that has any failing tests can’t be pushed into trunk. Additionally, long-lasting features get their own “feature branches” (again, actually full clones of the repository). So right now we have more than 40 of those team+feature branches.
We have almost 50 developers committing to the source tree. Additionally, there is a build farm of 30 machines building most of those branches and running automated test suites. All this does put some pressure on the Kiln server ;) Everything below describes usage of Kiln 2.3.x with Mercurial 1.7.x; with more recent versions anything might have changed.
Mercurial, or: I Have Two Heads!
Probably the hardest thing to grok is the whole centralized-to-distributed versioning transition. Not everyone has github as their start page yet, and DVCS is actually more complex than a simple centralized model that Subversion has.
Things like this:
OMG it says I have two heads now, what do I do?!
just do not happen in centralized systems. It’s not easy for a developer to accept he has two heads now, either. Or where this extra head came from…
And the benefits of distributed source control system are not immediately obvious to someone who’s never used one. The initial reaction is that suddenly everything got more complex for no good reason. Compare operations that you would use daily:
-
Subversion: update, commit.
- Since merges don’t really work: branch, switch & merge are rarely used by mere mortals.
-
Mercurial: pull, update or merge, commit, push.
-
And you might find you have two heads now!
-
You should also see their faces when you go “well, let me tell you about rebase…”. You might just as well explain everything with easy to understand spatial analogies ;)
Thankfully, there’s this thing called the intertubes, which often has helpful tutorials.
Myself, I think maybe switching to git would have been a smaller overall shock. Mercurial is easier to get into, but it kind of pretends to work like ye olde versioning system, while underneath it is very different. Git, on the other hand, does not even try to look similar; it says “I’ll fuck with your brain” immediately after initial “hi how are you”. So it’s a larger initial shock, but maybe that forces people to get into this different mindset faster.
Versioning large binary files
Even if we mostly version only the code, there are occasional binaries. In our case it’s mostly 3rd party SDKs that are linked into Unity. For example, PhysX, Mono, FMOD, D3DX, Cg etc. We do have the source code for most of them, but we don’t need each developer to have 30000 files of Mono’s source code for example. So we build them separately, and version the prebuilt headers/libraries/DLLs in the regular source tree. Some of those prebuilt things can get quite large though (think couple hundred megabytes).
Most distributed version control systems (including git and mercurial) have trouble with this. Every version of every file is stored in your own local checkoutclone. Try having 50 versions of whole Mono build in there and you’ll wonder where the precious SSD space on your laptop did go!
Luckily, Kiln has a solution for this: kbfiles extension. For each file marked as “large binary file”, only it’s “stand in” SHA1 hash is versioned, and the file itself is fetched from a central server into your local machine on demand. Think of it as a centralized versioning model for those special binary files. kbfiles itself is based on bfiles extension, with a tighter integration into Mercurial.
So the good news, with Kiln large binary files are handled easy and with no pain. You can globally set “large size” threshold, filename patterns etc. that are turned into “big files” automatically; or manually indicate “big file” when adding new files. And then continue using Mercurial as usual.
The bad news, however, is that kbfiles still has occasional bugs. Of course they will be fixed eventually, but for example right now rebasing with an incoming bigfiles commit will result in the wrong bigfile version in the end. Or, presence of kbfiles extension makes various Mercurial operations (like hg status) be much slower than usual.
Kiln as Web Interface
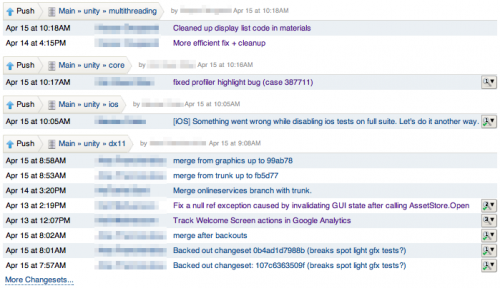
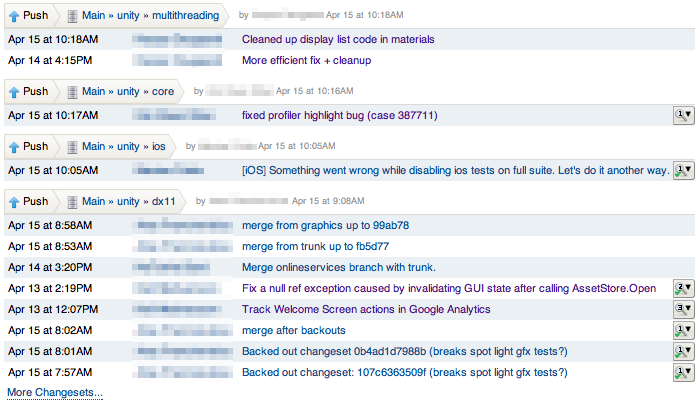
Kiln itself is the server hosting Mercurial repositories, a web interface to view/admin them, and a code review tool. It’s fairly nice and does all the standard stuff, like show overview of all activity happening in a group of repositories:
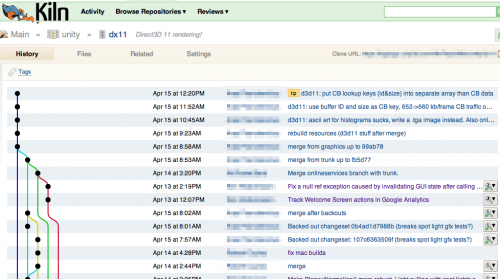
And shows the overview of any particular repository:
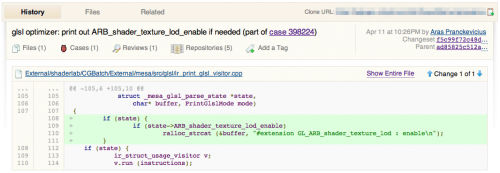
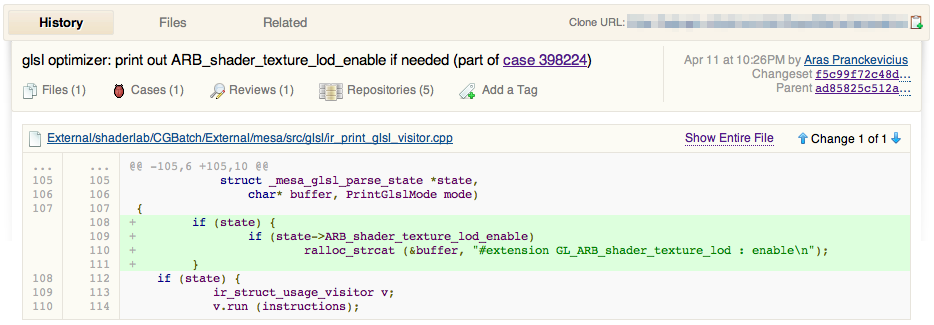
And of course diff view of any particular commit:
My largest complaints about Kiln’s web interface are: 1) speed and 2) merge spiderwebs.
Speed: like oh so many modern fancy-web systems, Kiln sometimes feels sluggish. Sometimes, in a time taken for Kiln to display a diff, Crysis 2 would have rendered New York fifty times. We did various things to boost up our server’s oomph, but it still does not feel fast enough. Maybe we don’t know how to setup our servers right; or maybe Kiln is actually quite slow; or maybe our repository size + branch count + number of people hitting it are exceeding whatever limits Kiln was designed for. That said, this is not unique of Kiln, lots of web systems are slow for sometimes no good reasons. If you are a web developer, however, keep this in mind: latency of any user operation is super important.
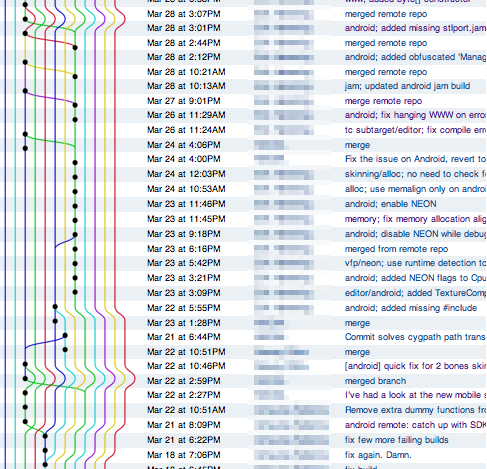
 Merge spiderwebs: distributed version control makes merges reliable and easy. However, merges happen all the time and can make it hard to see what was actually going on in the code. You can’t see the actual changes through the merge spiderwebs.
Merge spiderwebs: distributed version control makes merges reliable and easy. However, merges happen all the time and can make it hard to see what was actually going on in the code. You can’t see the actual changes through the merge spiderwebs.
The change history is littered with “merge”, “merge remote repo”, “merge again” commits. The branch graph goes crazy and starts taking half of the page width. Not good! Now of course, this is where rebasing would help, however right now we’re not very keen on using it because of Kiln’s bigfiles bug mentioned above.
Kiln as Code Review Tool
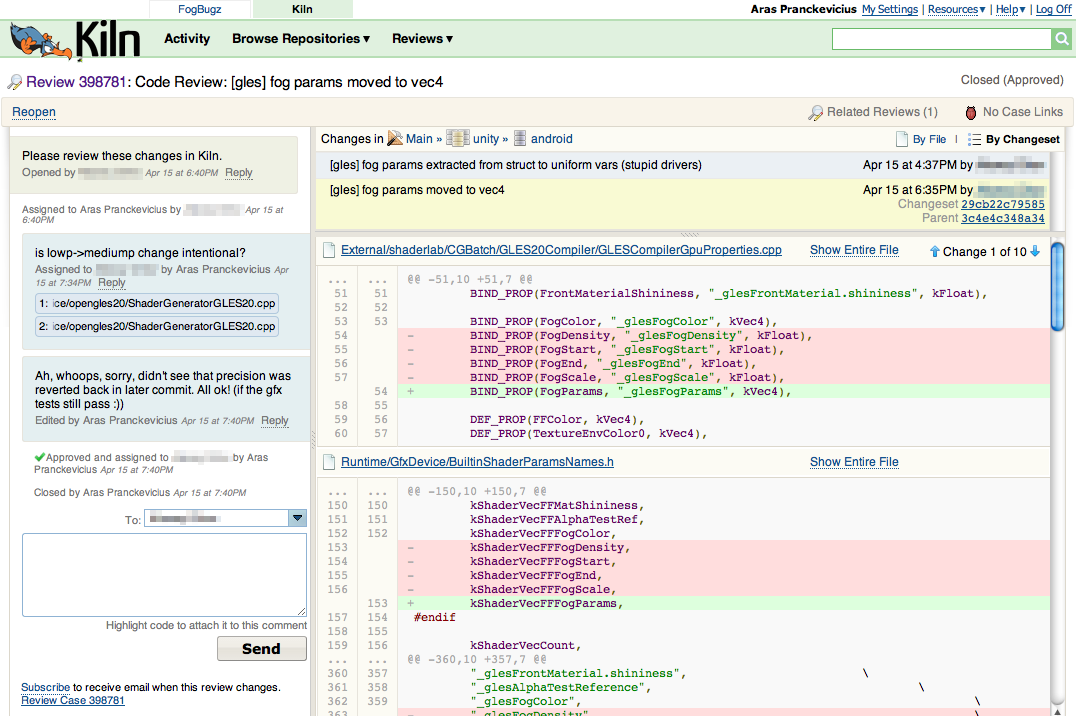
Reviewing code is fairly easy: there’s a Review button that shows up when hovering over any commit. Each commit also shows how many reviews it has pending or accepted. So you just click on something, and voilà, you can request a code review:
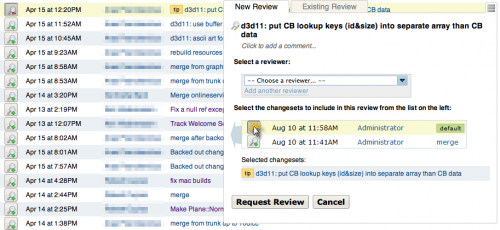
Within each review you see the diffs, send comments back and forth between people, and highlight code snippets to be attached with each comment:
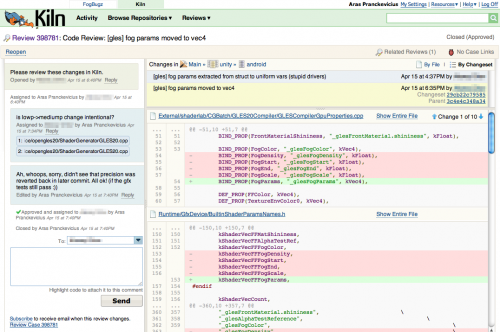
In Kiln 2.3.x (which is what we use at the moment) the reviews still have a sort of “unfinished” feeling. For example, if you want multiple people to review a change, Kiln actually creates multiple reviews that are only very loosely coupled. The good news is that in Kiln 2.4 they have improved this, and I’m quite sure more improvements will come in the future.
Another option that I’m missing right now: in the repository views, filter out all approved commits. As an occasional “merge master”, I need to see if my big merge had any unreviewed or pending-review commits – something that’s quite hard to see with a merge-heavy history.
Summary
I’m quite happy with how switch to Mercurial + Kiln turned out to be so far. With each team working on their own repository, it does feel like we’re much less stepping on each other’s toes. That said, we haven’t shipped any Unity release from Mercurial yet; doing that will be a future exercise.
Kiln is promising. It has some very good ideas (integrated code reviews & versioning of big files in Mercurial), but it still has quite a lot of rough edges. I’m not totally happy with the web side performance of it either. That said, Fogcreek’s support for us has been fantastic; we got some bugfixes in the matter of days and they’ve been really helpful with setup/workflow/optimization issues. So it seems like it has a good future. Fogcreek guys, if you’re reading this: keep up wrk!










{kind=link}