Sergey from Blender asked me to look into why trying to manually sprinkle some SIMD into Cycles renderer Voronoi
node code actually made things slower, and I started to look, and what I did in the end had nothing to do with SIMD
whatsoever!
Blender has a Voronoi node
that can be used in any node based scenario (materials, compositor, geometry nodes). More precisely, it is
actually a Worley noise procedural noise function. It can be used
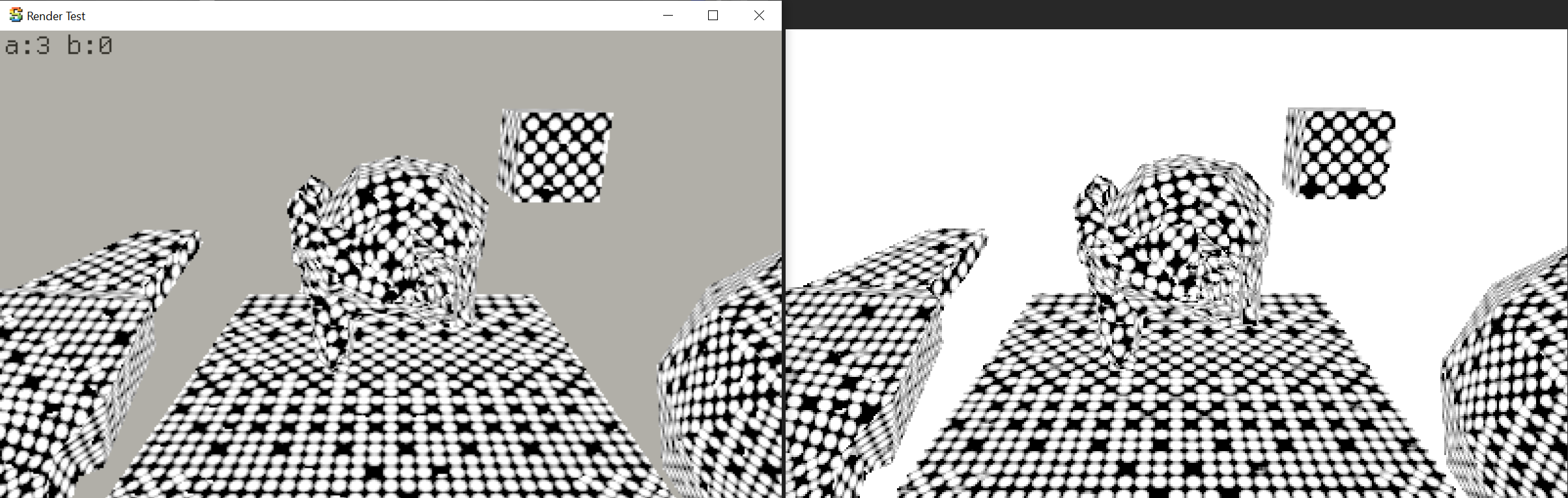
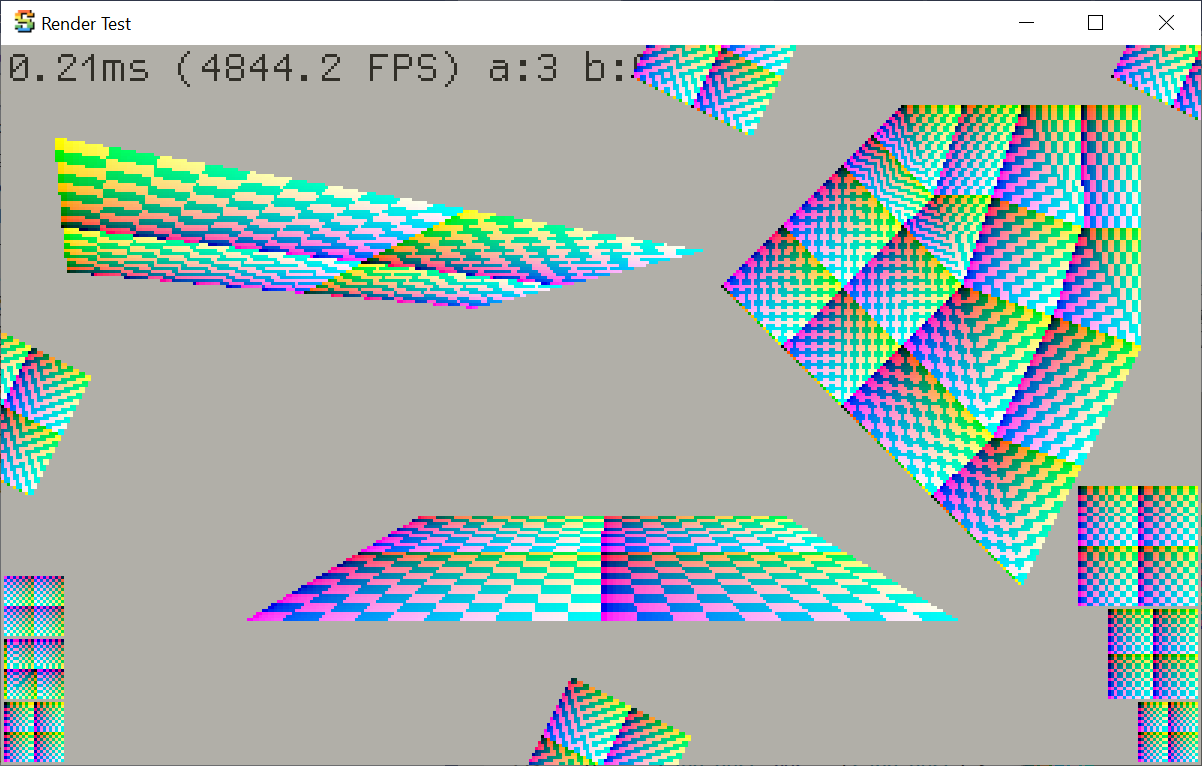
to produce various interesting patterns:
A typical implementation of Voronoi uses a hash function to randomly offset each grid cell. For something
like a 3D noise case, it has to calculate said hash on 27 neighboring cells (3x3x3), for each item
being evaluated. That is a lot of hashing!
Current implementation of e.g. “calculate random 0..1 3D offset for a 3D cell coordinate” looked like this in Blender:
// Jenkins Lookup3 Hash Function
// https://burtleburtle.net/bob/c/lookup3.c
#define rot(x, k) (((x) << (k)) | ((x) >> (32 - (k))))
#define mix(a, b, c) { \
a -= c; a ^= rot(c, 4); c += b; \
b -= a; b ^= rot(a, 6); a += c; \
c -= b; c ^= rot(b, 8); b += a; \
a -= c; a ^= rot(c, 16); c += b; \
b -= a; b ^= rot(a, 19); a += c; \
c -= b; c ^= rot(b, 4); b += a; \
}
#define final(a, b, c) { \
c ^= b; c -= rot(b, 14); \
a ^= c; a -= rot(c, 11); \
b ^= a; b -= rot(a, 25); \
c ^= b; c -= rot(b, 16); \
a ^= c; a -= rot(c, 4); \
b ^= a; b -= rot(a, 14); \
c ^= b; c -= rot(b, 24); \
}
uint hash_uint3(uint kx, uint ky, uint kz)
{
uint a;
uint b;
uint c;
a = b = c = 0xdeadbeef + (3 << 2) + 13;
c += kz;
b += ky;
a += kx;
final(a, b, c);
return c;
}
uint hash_uint4(uint kx, uint ky, uint kz, uint kw)
{
uint a;
uint b;
uint c;
a = b = c = 0xdeadbeef + (4 << 2) + 13;
a += kx;
b += ky;
c += kz;
mix(a, b, c);
a += kw;
final(a, b, c);
return c;
}
float uint_to_float_incl(uint n)
{
return (float)n * (1.0f / (float)0xFFFFFFFFu);
}
float hash_uint3_to_float(uint kx, uint ky, uint kz)
{
return uint_to_float_incl(hash_uint3(kx, ky, kz));
}
float hash_uint4_to_float(uint kx, uint ky, uint kz, uint kw)
{
return uint_to_float_incl(hash_uint4(kx, ky, kz, kw));
}
float hash_float3_to_float(float3 k)
{
return hash_uint3_to_float(as_uint(k.x), as_uint(k.y), as_uint(k.z));
}
float hash_float4_to_float(float4 k)
{
return hash_uint4_to_float(as_uint(k.x), as_uint(k.y), as_uint(k.z), as_uint(k.w));
}
float3 hash_float3_to_float3(float3 k)
{
return float3(hash_float3_to_float(k),
hash_float4_to_float(float4(k.x, k.y, k.z, 1.0)),
hash_float4_to_float(float4(k.x, k.y, k.z, 2.0)));
}
i.e. it is based on Bob Jenkins’ “lookup3” hash function,
and does that “kind of three times”, pretending to hash float3(x,y,z), float4(x,y,z,1) and float4(x,y,z,2).
This is to calculate one offset of the grid cell. Repeat that to 27 grid cells for 3D Voronoi case.
I know! Let’s switch to PCG3D hash!
If you are aware of “Hash Functions for GPU Rendering” (Jarzynski, Olano, 2020) paper, you can
say “hey, maybe instead of using hash function from 1997, let’s use a dedicated 3D->3D hash function from several decades later”.
And you would be absolutely right:
uint3 hash_pcg3d(uint3 v)
{
v = v * 1664525u + 1013904223u;
v.x += v.y * v.z;
v.y += v.z * v.x;
v.z += v.x * v.y;
v = v ^ (v >> 16);
v.x += v.y * v.z;
v.y += v.z * v.x;
v.z += v.x * v.y;
return v;
}
float3 hash_float3_to_float3(float3 k)
{
uint3 uk = as_uint3(k);
uint3 h = hash_pcg3d(uk);
float3 f = float3(h);
return f * (1.0f / (float)0xFFFFFFFFu);
}
Which is way cheaper (the hash function itself is like 4x faster on modern CPUs). Good! We are done!
If you are using hash functions from the 1990s, try some of the more modern ones!
They might be both simpler and the same or better quality.
Hash functions from several decades ago were built on assumption
that multiplication is very expensive, which is very much not
the case anymore.
So you do this for various Voronoi cases of 2D->2D, 3D->3D, 4D->4D. First in the Cycles C++ code
(which compiles itself to both CPU execution, and to GPU via CUDA/Metal/HIP/oneAPI), then
in EEVEE GPU shader code (GLSL), then in regular Blender C++ code (which is used in geometry nodes
and CPU compositor).
And you think you are done until you realize…
Cycles with Open Shading Language (OSL)
The test suite reminds you that Blender Cycles can use OSL
as the shading backend. Open Shading Language, similar to
GLSL, HLSL or RSL, is a C-like language to write shaders in. Unlike some other languages, a “shader” does not output color;
instead it outputs a “radiance closure” so that the result can be importance-sampled by the renderer, etc.
So I thought, okay, instead of updating the Voronoi code in three places (Cycles CPU, EEVEE GPU, Blender CPU), it will have to
be four places. Let’s find out where and how does Cycles implements the shader nodes for OSL, update that place, and we’re good.
Except… turns out, OSL does not have unsigned integers (see data types).
Also, it does not have bitcast from float to int.
I certainly did not expect an “Advanced shading language for production GI renderers” to not have a concept of unsigned integers,
in year 2025 LOL :) I knew nothing about OSL just a day before, and now I was there wondering about the language data type system.
Luckily enough, specifically for Voronoi case, all of that can be worked around by:
Noticing that everywhere within Voronoi code, we need to calculate a pseudorandom “cell offset” out of integer cell
coordinates only. That is, we do not need hash_float3_to_float3, we need hash_int3_to_float3. This works around the lack
of bit casts in OSL.
We can work around lack of unsigned integers with a slight modification to PCG hash, that just operates on signed integers instead.
OSL can do multiplications, XORs and bit shifts, just only on signed integers. Fine with us!
int3 hash_pcg3d_i(int3 v)
{
v = v * 1664525 + 1013904223;
v.x += v.y * v.z;
v.y += v.z * v.x;
v.z += v.x * v.y;
v = v ^ (v >> 16);
v.x += v.y * v.z;
v.y += v.z * v.x;
v.z += v.x * v.y;
return v & 0x7FFFFFFF;
}
float3 hash_int3_to_float3(int3 k)
{
int3 h = hash_pcg3d_i(k);
float3 f = float3((float)h.x, (float)h.y, (float)h.z);
return f * (1.0f / (float)0x7FFFFFFFu);
}
So that works, just instead of only having to change hash_float3_to_float3 and friends, this now required updating
all the Voronoi code itself as well, to make it hash integer cell coordinates as inputs.
“Wait, but how did Voronoi OSL code work in Blender previously?!”
Good question! It was using the OSL built-in hashnoise() functions
that take float as input, and produce a float output. And… yup, they just happened to use exactly the same Jenkins Lookup3 hash function underneath.
Happy coincidence? One implementation copying what the other was doing? I don’t know.
It would be nice if OSL got unsigned integers and bitcasts though. Since today, if you need to hash float->float, you can only use the built-in OSL
hash function, which is not particularly fast. For Voronoi case that can be worked around, but I bet there are other cases where workign around it is much harder.
So that’s it!
The pull request that makes Blender Voronoi node 2x-3x faster has been merged for Blender 5.0.
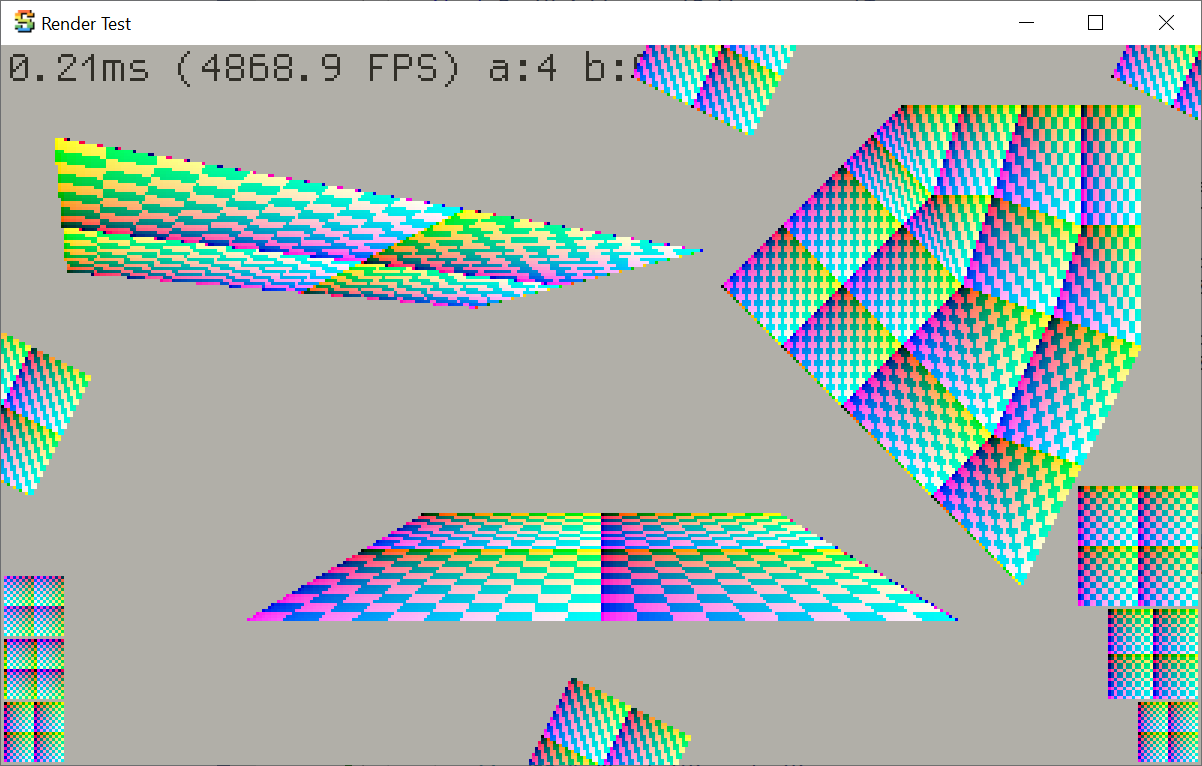
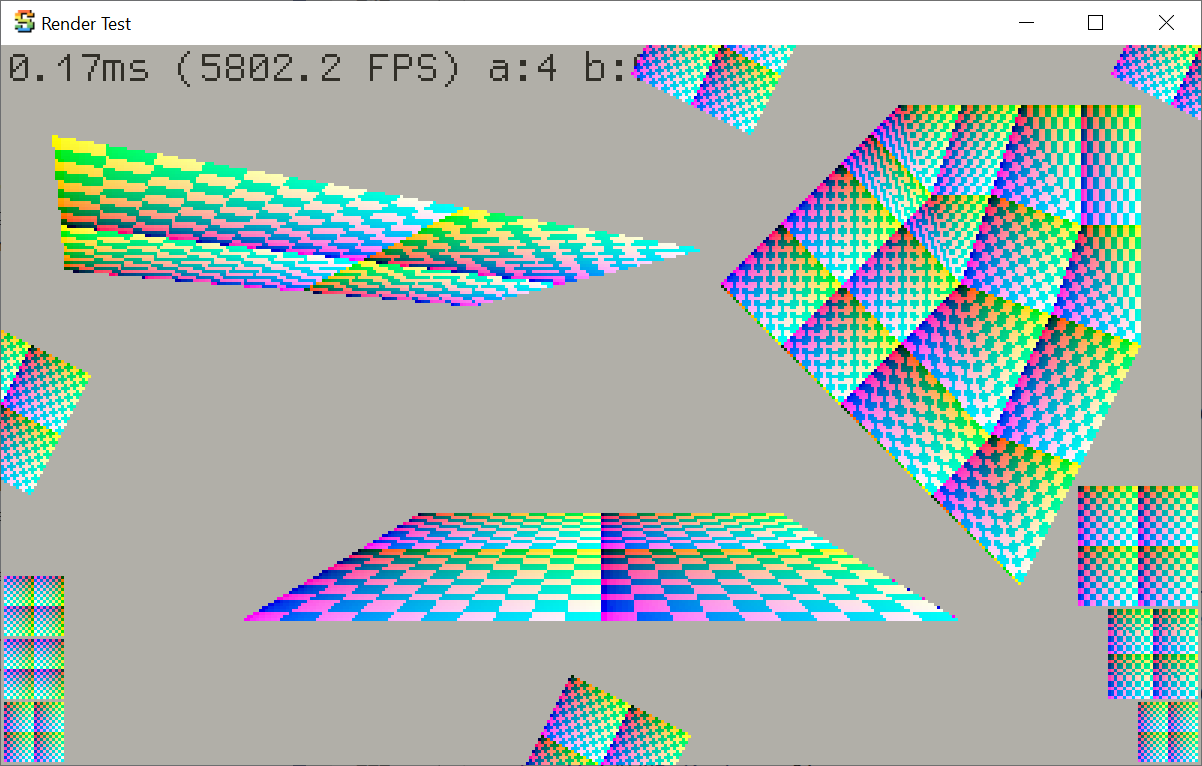
It does change the actual resulting Voronoi pattern, e.g. before and after:
So while it “behaves” the same, the literal pattern has changed. And that is why a 5.0 release sounds like good timing to do it.
What did I learn?
Actually learned about how Voronoi/Worley noise code works, instead of only casually hearing about it.
Learned that various nodes within Blender have four separate implementations, that all have to match in behavior.
Learned that there is a shading language, in 2025, that does not have unsigned integers :)
There can be (and is) code out there that is using hash functions from the previous millenium, which might be not optimal today.
I should still look at the SIMD aspect of this whole thing.
Three years ago I found myself speeding up Blender OBJ importer,
and this time I am rewriting Blender FBX importer. Or, letting
someone else take care of the actually complex parts of it.
FBX, a 3D and animation interchange format owned by
KaydaraAliasAutodesk, is a proprietary format that is still quite popular in some spaces.
The file format itself is quite good actually; the largest
downsides of it are: 1) it is closed and with no public spec, and 2) due to it being very flexible, various
software represent their data in funny and sometimes incompatible ways. The future of the format
seems to be “dead” at this point; after a decade of continued improvements to the FBX format and the SDK,
Autodesk seems to have stopped around year 2020. However, the two big game engines (Unity and Unreal) still
both treat FBX as the primary format in how 3D data gets into the engine. But going forward, perhaps one should
use USD,
glTF or Alembic.
Blender, by design / out of principle only uses open source libraries for everything that ships inside of it.
Which means it can not use the official (closed source, binary only) Autodesk FBX SDK,
and instead had to reverse engineer the format and write their own code to do import/export. And so they did!
They added FBX export in 2.44 (year 2007), and import in 2.69 (year 2013), and have a short reverse engineered
FBX format description on the developer blog.
The FBX import/export functionality, as was common within Blender at the time, was written in pure Python. Which
is great for the expressiveness and makes for very compact code, but is not that great for many other reasons. However,
it has been expanded, fixed and optimized over the years – recent versions use NumPy for many heavy number
crunching parts, the exporter does some multi-threaded Deflate compression, and so on. The whole
implementation is about 12 thousand lines of Python code, which is very compact, given that it does import, export
and all the Blender parts too (that comes at a cost though… in some places it feels too compact, when someone
else wants to understand what the code is doing :)).
So far so good! However, ufbx open source library was born sometime in 2019.
ufbx, and other FBX parsers
ufbx (github, website) by Samuli Raivio is a single source file
C library for loading FBX files.
And holy potatoes, it is an excellent library. Seriously: ufbx is one of the best written libraries I’ve ever seen.
Compiles out of the box with no configuration needed. You can configure it very extensively, if you want to:
Disable parts of library you don’t need (e.g. subdivision surface evaluation, animation layer blending evaluation, etc.).
Pass your own memory allocation functions, your own job scheduler, even your own C runtime functions.
Disable data validation, disable loading of certain kinds of data, and so on.
The API and the data structures exposed by it just make sense. This is highly subjective, but I found it very
easy to use and find my way around.
It is very extensively tested at multiple levels.
And also, it is very fast. I actually wanted to compare ufbx with the official FBX SDK, and several other open source
FBX parsing libraries I managed to find (AssImp, OpenFBX).
Here’s time it takes (in seconds, on Ryzen 5950X / Windows / VS2022) to read 9 FBX files (total size 2GB), and extract very
basic information about the scene (how many vertices in total, etc.). There is sequential time (read files one by one),
and parallel time (read files in parallel, independently), as well size of the executable that does all that.
Parser
Time sequential, s
Time parallel, s
Executable size, KB
ufbx
9.8
2.7
457
ufbx w/ internal threads
4.4
2.6
462
FBX SDK
869.9
crash!
4508
AssImp
33.9
26.7
1060
OpenFBX
26.7
15.8
312
Or, in more visual form:
Does performance of the official FBX SDK look very bad here? Yes indeed it does. This seems to be due to two reasons:
It can not parse several FBX files in parallel. It just can’t due to shared global data of some sorts.
On some files (mostly the ones that have lots of animation curves, or lots of instancing), it is very slow. Not to parse
them! But to clean up after you are done with parsing. Looks like even if you want to tell it “yeet everything”, it proceeds
to do that one entity at a time, doing a lot of work making sure that after removing each individual little shit, it is properly
de-registered from any other things that were referencing it. Probably effectively a quadratic complexity amount of work.
Anyway, if you need to load/parse FBX files, just use ufbx!
Blender 4.5: new FBX importer
So, I made a new FBX importer for Blender 4.5 (pull request). So far it is
marked “experimental”, and for a while both the new one and the Python-based one will co-exist. Until the new one is sufficiently
tested and the old one can be removed.
The new importer comes with several advantages, like:
It supports ASCII FBX files, as well as binary FBX files that are older than FBX 7.1.
Better handling of “geometric transform” (common in 3dsmax), support for more types of Material shading models, imported animations
are better organized into Actions/Slots.
So far I have found about 20 existing open bug reports, where current FBX importer was importing something wrong, and the new one
does the correct thing.
Right now there is one bug report about the new importer doing incorrect thing… looking into it! :)
Oh, and it is quite a bit faster too. While the Python based importer was quite fast (for Python, that is), the new one is often 5x-20x
faster, while using less memory too. Here are some tests, import times in seconds (Ryzen 5950X):
Test case
Notes
Time Python
Time new
Blender 3.0 Splash
30k instances
83.4
4.7
Rain Restaurant
300k animation curves
86.8
4.4
Zero Day
6M triangles, 8K objects
22.1
1.7
Caldera
21M triangles, 6K objects
44.2
4.4
Even if it is ufbx that takes care of all the actually complex parts of the work, I still managed to wastespend quite a lot of time on this.
However, most of the time I spent procrastinating, in the style of “oh no, now I will have to do materials, this is going to be complex”
– proceed to find excuses to not do it just yet – eventually do it, and turns out it was not as scary. Besides stalling this way, most of the other
time sink has been just learning innards of Blender (the whole area of Armatures, Bones, EditBones, bPoseChannels is quite something).
The amount of code for just the Blender importer side (i.e. not counting ufbx itself) still ended up at 3000 lines, which is not compact at all.
Anyway, now what remains is to fix the open issues (so far… just one!), do a bunch of improvements I have in mind, and ship this to the world in
Blender 4.5. You can try out daily builds yourself!
We just spent a week-and-a-bit in southern part of United States, so here’s a bunch
of photos and some random thoughts!
Aistė went for a work related conference in New Orleans, and we (myself and our two
kids) joined her after that. A bit in New Orleans, then driving across the
Gulf of Mexico coast towards Orlando.
I wanted to see New Orleans mostly due to its historical importance for music,
and we wanted to end the trip in Kennedy Space Center due to, well, “space! rockets!”
New Orleans
The conference Aistė attended was great, but she was struck by anxiety experienced
by her American colleagues regarding all the current shitshow in the country.
Decades of achievements in diversity, inclusion, healthcare access, scientific
advancements are wiped away by some idiot manbabies. We still remember the not-too-distant
times when the “head of the state” was above all reason, rules and logic, and that is not
a great setup :(
Anyway. New Orleans definitely looks different than most other US cities I’ve been to.
However, I somehow expected something more, but not sure what exactly. Maybe more
spontaneous / magic music moments? They are probably happening somewhere, we just did not
stumble into them. Several times we saw homeless people playing music in their own bands
out in the parks, and while that is cool, it is also sad.
New Orleans National WWII Museum
I did not have high expectations going into WWII museum;
I expected something bombastic, proudly proclaiming how US victoriously
planted their flag and saved the world (no reason to think like this,
I just have stereotypes). The museum is nothing like that; I think it conveys
wery well how a war is really a shit situation, and everything is terrible there.
Both the Pacific Theater and the European Theater exhibits are full of stories
of failed operations, strategic miscalculations, and so on.
That last photo above however… how quaint! <gestures at, well, everything around>
I had not realized that many plantations continued to operate well into the 20th
century, often with the same people working at them that used to be slaves.
“You are free now! Except you have no property, money, or education. Good luck out there!”
Driving towards Orlando, we stopped at the
Battleship Memorial Park in Mobile, Alabama.
USS Alabama is
very impressive from engineering standpoint. Heck, it is over 80 years old by now!
Now of course, it would be ideal if such engineering was not needed at all… but here we are.
Pensacola Beach
We only caught an evening glimpse of Pensacola Beach
while driving onwards. The whole color scheme is impressively blue in the evening!
Maclay State Gardens
Alfred B. Maclay State Gardens
park near Tallahassee was a somewhat random choice for a stop, and it turned out
to be very impressive. Magnolias, azaleas and camellias are in beautiful bloom,
and the tillandsias look like magic.
Gator / Bird watching
Airboat tour at Tohopekaliga lake near Orlando, FL. It was a shame
that this tour guide focused only on the gators, more or less. There was so many
other things around!
Kennedy Space Center
Visitor complex at the Kennedy Space Center
is very impressive. The only problem is – way too many people! :)
At least when we visited, it was packed with primary and middle school
kids, who, it turns out, create an impressive amount of noise and chaos.
But seeing the actual Shace Shuttle
and Saturn V is a sight to behold.
The photos do not convey the scale.
That’s it!
So that was our trip! Short and sweet, and we only hit a minor snag on the way
back due to a flight delay, which made us miss the next flight, so the total
journey back became some 30 hours. The luggage arrived as well, eventually :)
On the plane back I watched
Soundtrack to a Coup d’Etat,
a 2024 documentary about 1961, with newly independent Congo, UN, large powers of the world
(US and USSR) dividing their spheres of influence, music as a soft power,
and various plots for eventual control of natural resource deposits. Political backroom
deals over natural resource deposits? Proclaiming support and then backstabbing someone?
Ugh the 60s, how antiquated, surely something like that would not happen in 21st century. Right?!
Rune Skovbo Johansen has a really sweet Surface-Stable Fractal Dithering
technique, where the dither dots “stick” to 3D surfaces, yet the dot density adapts to the view distance and zoom
level.
Some people have asked whether this would be a good technique for Playdate, given that the screen
is one-bit color. And so I had to try it out! Here’s a video:
Playdate hardware is like a PC from 1995 - no GPU at all, one fairly simple CPU
core. As such, it can do fairly simple 3D rendering (well, you need to write the whole rasterizer on the CPU),
but can barely do more than a handful of math operations per rasterized pixel. Rasterizing with screen-space fixed
Bayer or Blue Noise dither patterns is the way to go due to their simplicity.
You can barely do textured triangles, whereas cost of Fractal Dithering is, with some simplifications, at
least twice that (you still need to interpolate the texture coordinates, do some additional math on them, do a
3D texture lookup, and additional math on that).
But, while doing this, I’ve learned a thing or two about software rasterizers. Of course, everyone else has learned that
in 1997, but I’ve never written a perspective-correct textured triangle rasterizer… As
the old saying goes, “the best time to write a triangle rasterizer was thirty years ago. The second best time is today.”
So what follows is various notes I have made during the process.
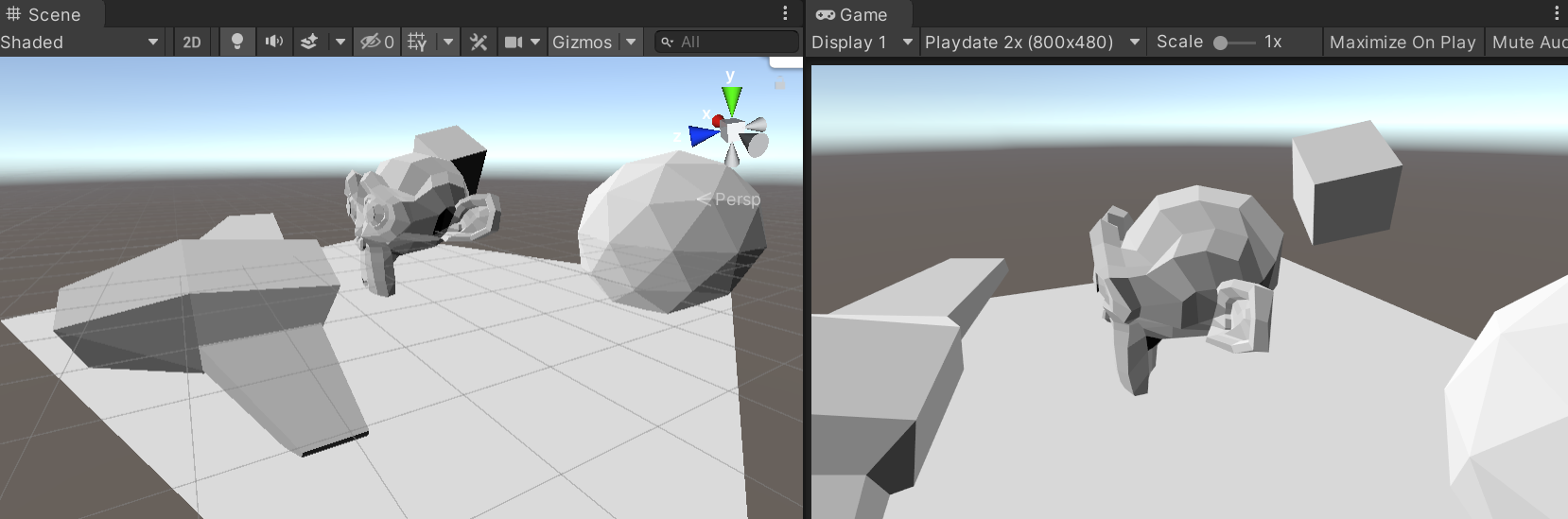
Here’s an outline of the steps. We have some scene where the input for dithering is “brightness”:
And the Surface-Stable Fractal Dithering (with a 4x4 dither pattern) turns it into this:
Now, the dots above are still nicely anti-aliased; whereas Playdate is strictly 1-bit screen. Giving it only
two colors, and making them similar to how the device screen looks like, the result would be like this (note that
resolution here is 2x larger than Playdate, i.e. 800x480):
In addition to brightness, the dithering process needs geometry texture coordinates (“UVs”) as well. The dithering
pattern “sticks” to the surfaces by placing them in UV space.
It also needs the derivatives of UVs in screen space, to know “how fast” they change across the screen projection. That
will be used to make sure the dither pattern is roughly constant size on screen. On the GPU, the derivatives
fall out naturally out of 2x2 pixel execution pattern, and in HLSL are provided by ddx and ddy built-in functions.
Here they are, visualized as abs(ddx(uv))*100 and abs(ddy(uv))*100 respectively:
Now, given these four derivative values, the technique uses singular value decomposition to find the minimum and
maximum rate of change (these might not be aligned to screen axes). The maximum and minimum frequencies (scaled up 30x)
look like:
The minimum frequency, together with user/material-specified dot spacing factor, gets turned into base
dither dot spacing value:
Then it is further adjusted by input brightness (if “size variability” material parameter is zero), so that
the actual dots stay roughly the same size, but in darker areas their spacing spreads further out.
This spacing is then used to calculate two factors used to sample a 3D lookup texture: 1) by which power
of two to adjust the mesh UVs so that the dither dots pattern is placed onto surface properly, and 2) which
actual dither pattern “slice” to use, so that the pattern more or less seamlessly blends between powers-of-two
levels.
The mesh UVs, adjusted for 3D texture sampling, look like this, as well as indication which Z slice of the texture to use:
Result of sampling the 3D lookup texture (that was prepared ahead of time) is:
The 3D texture itself for the 4x4 dither pattern (64x64x16, with 3D texture slices side by side) looks like this:
We’re almost there! Next up, the algorithm calculates contrast factor, which is based on material settings,
dot spacing, and the ratio of minimum and maximum UV rate of change. From that, the base brightness value
that the contrast is scaled around is calculated (normally it would be 0.5, but where the pattern would be very blurry
that would look bad, so there it is scaled away). And finally, the threshold value to compare the radial gradient from
3D texture is calculated based on input brightness. The contrast, base value and threshold respectively look like:
And finally we get our result:
So all of that was… <takes a quick look> something like one 3D texture sample, 4 divisions, 2 raises to a
power, 3 square roots, 3 exp2s, 1 log2, and several dozen regular multiplies or additions for every pixel.
Provided you have UVs and their derivatives already, that is.
That should, like, totally fly on a Playdate, right? 🥹
Anyway, let’s do this! But first…
Perspective correct texturing
Triangles have texture coordinates defined at their vertices, and while rasterizing the triangle, you interpolate
the texture coordinates, and at each pixel, read the texture value corresponding to the interpolated coordinate.
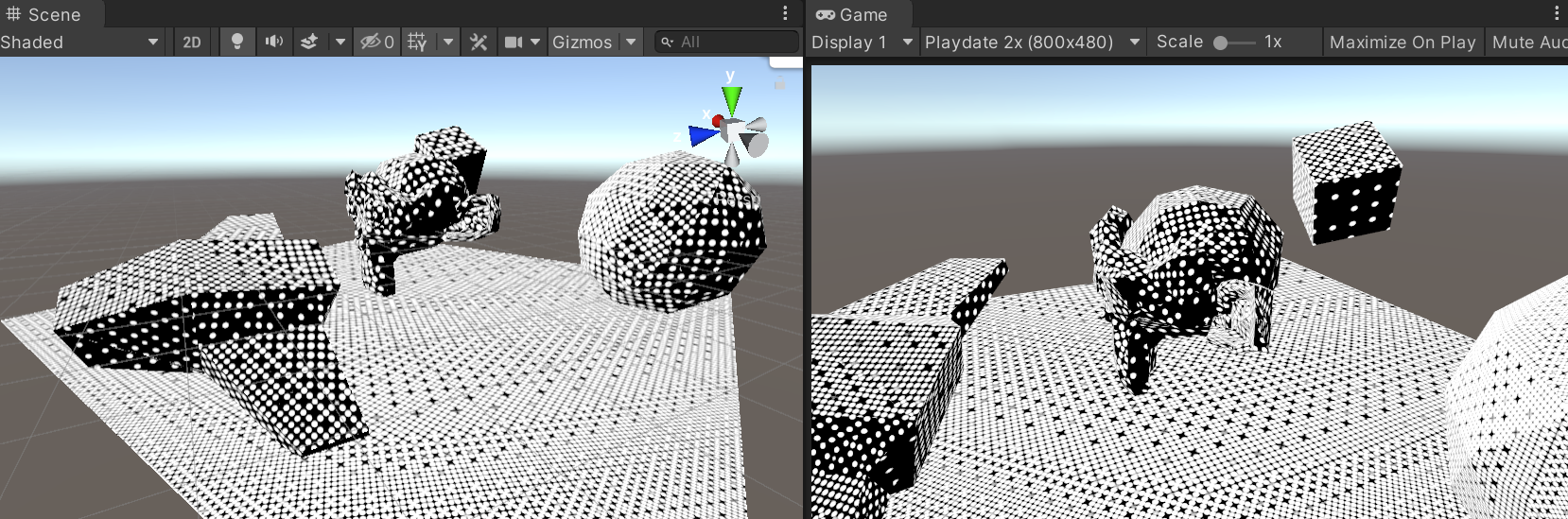
Here’s a simple checkerboard texture using interpolated UVs (ignore the noisy dithering; it is unrelated):
However, if we look at the same mesh at an angle, it looks really weird:
That is because under perspective projection, you need to use
perspective correct texture mapping,
and not just simply interpolate UVs in screen space. With perspective correction things look good, however that
means now we have to do a division per-pixel. And, divisions are slow. Anyway, this is the least of our problems
(for now…).
Displaying brightness on a Playdate
Playdate hardware has 1-bit “memory LCD” display: each pixel
can only be “on” or “off”. So typically to display “brightness”, some sort of dithering is used. The example
simple 3D rasterizer included in the Playdate SDK (“mini3d”) contains code
that rasterizes triangles using different patterns based on brightness:
Welp, this does not look correct at all. Time to debug where exactly it goes wrong!
For development convenience, I have the whole “playdate application”
setup as both a Playdate build target, and an application that can build for PC.
There’s a super tiny “platform abstraction” that provides pointer to “screen”, as well as input
controls handling, and on a Playdate that goes directly into the SDK, whereas on a PC that is all handled
through Sokol. Is nice!
For the “PC” build target, in addition to the regular 1-bit “screen” buffer, I also have a full-color
“RGBA per pixel” debug overlay buffer. That way I can have the correct shader with some debug visualizations
running in Unity, and my own “shader port” running in a software rasterizer, side by side, with
a full color debug overlay. Check it out – left side my code (displaying obviously incorrect result),
right side Unity:
The mesh UVs are correct and interpolated correctly (multiplied by 5 to see their interpolation better):
Derivatives in my code, turns out, were not entirely wrong, but not correct either:
At that point my rasterizer was doing 1 pixel at a time, so in order to calculate the derivatives
I tried to calculate them with some math, and got the math wrong, obviously. With the full
proper calculation, they were correct:
Turns out I also had the 3D texture Z layers order wrong, and with that fixed, everything else
was correct too. Dither UVs, 3D texture radial pattern, render result, render result with 2 colors
only, and finally render result with non-constant input lighting:
So, yay! It works!
It runs at… 830 milliseconds per frame though (1.2FPS). 🐌
Optimizing Fractal Dithering
Trivially move some math from per-pixel to be done once per triangle: 604ms.
Replace division and exp2f call by directly working on floating point bits. If we are in “regular floats”
range (no NaNs/infinities/denormals), x / exp2f((float)i) can be replaced by something like:
// equivalent to `x / exp2f((float)i)`, provided we are not in
// infinities / subnormals territory.
static inline float adjust_float_exp(float x, int i)
{
union {
float f;
uint32_t u;
} fu;
fu.f = x;
fu.u -= (uint32_t)i << 23;
return fu.f;
}
In the dither shader, this was used to transform mesh UVs to the fractal pattern UVs. That gets us down to
316ms, yay! (by the way, such an optimization for today’s GPUs is barely – if at all – worth doing)
Likewise, in the 3D texture fractal level and fraction calculation that uses log2f and a floorf
can also be replaced with direct float bit manipulation:
//float spacingLog = log2f(spacing);
//const float patternScaleLevel = floorf(spacingLog); // Fractal level.
//const int patternScaleLevel_i = (int)patternScaleLevel;
//float f = spacingLog - patternScaleLevel; // Fractional part.
//
// instead of above, work on float bits directly:
union {
float f;
uint32_t u;
} fu;
fu.f = spacing;
// patternScaleLevel is just float exponent:
const int patternScaleLevel_i = (int)((fu.u >> 23) & 0xFF) - 127;
// fractional part is:
// - take the mantissa bits of spacing,
// - set exponent to 127, i.e. range [0,1)
// - use that as a float and subtract 1.0
fu.u = (fu.u & 0x7FFFFF) | 0x3F800000;
float f = fu.f - 1.0f;
And now we are at 245ms.
And now, switch the rasterizer to operate in 2x2 pixel blocks (hey, just like a GPU does!). This does
make the code much longer (commit),
but things like derivatives come “for free”, plus it allows doing a bunch
of calculations (all the dither dot spacing, 3D texture level etc.) once per 2x2 pixel block. 149ms.
Somemore simple math operation moves
and we’re at 123ms.
At this point I was out of easy ideas, so I decided that running “full” effect on a Playdate
is not going to work, so it is time to simplify / approximate it.
The effect spends quite some effort in determining nice “contrast” value, but it comes with a cost:
doing singular value decomposition on the four derivatives, a division, and a bunch of other maths.
Let’s remove all that, and instead determine dither pattern spacing by a simple average of dU/dX,
dV/dX, dU/dY, dV/dY. Then there’s no longer additional contrast tweak based on “blurriness”
(ratio of min/max UV change). However, it runs at 107ms now, but looks different:
The 3D lookup texture for dithering, at 64x64x16 resolution, is 64 kilobytes in size. The CPU
cache is only 8KB, and the memory bandwidth is not great. Maybe we could reduce the texture horizontal
resolution (to 32x32x16), for a 16KB texture, and it would not reduce quality all that much? Looks
a bit different, but hey, 83ms now:
Instead of doing perspective correct UV interpolation for every pixel, do it for every
2nd pixel only, i.e. for the first column of each 2x2 pixel block. For the other column,
do regular interpolation between this and next block’s UV values
(commit). 75ms:
Simplify the final math that does sampled 3D texture result comparison, now it is just a simple
“compare value with threshold”. 65ms:
At this point I was out of easy ideas how to speed it up further (harder ideas: do perspective correct
interpolation at even lower frequency). However, anecdotally, the whole current approach
of using halfspace/barycentric rasterizer is probably not a good fit for the Playdate CPU (it does
not have SIMD instructions that would be useful for this task, afterall). So maybe I should
try out the classic “scanline” rasterizer approach?
Scanline Rasterizers
The Playdate SDK sample code (“mini3d”) contains a simple scanline triangle rasterizer,
however it can only cover whole triangle in a screen-space aligned pattern, and has no support for
texture coordinates or any other sort of interpolation. However, people have taken that and expanded
on it, e.g. there’s Mini3D+ that adds near plane clipping,
texturing, alpha-testing, fog, etc. Nice!
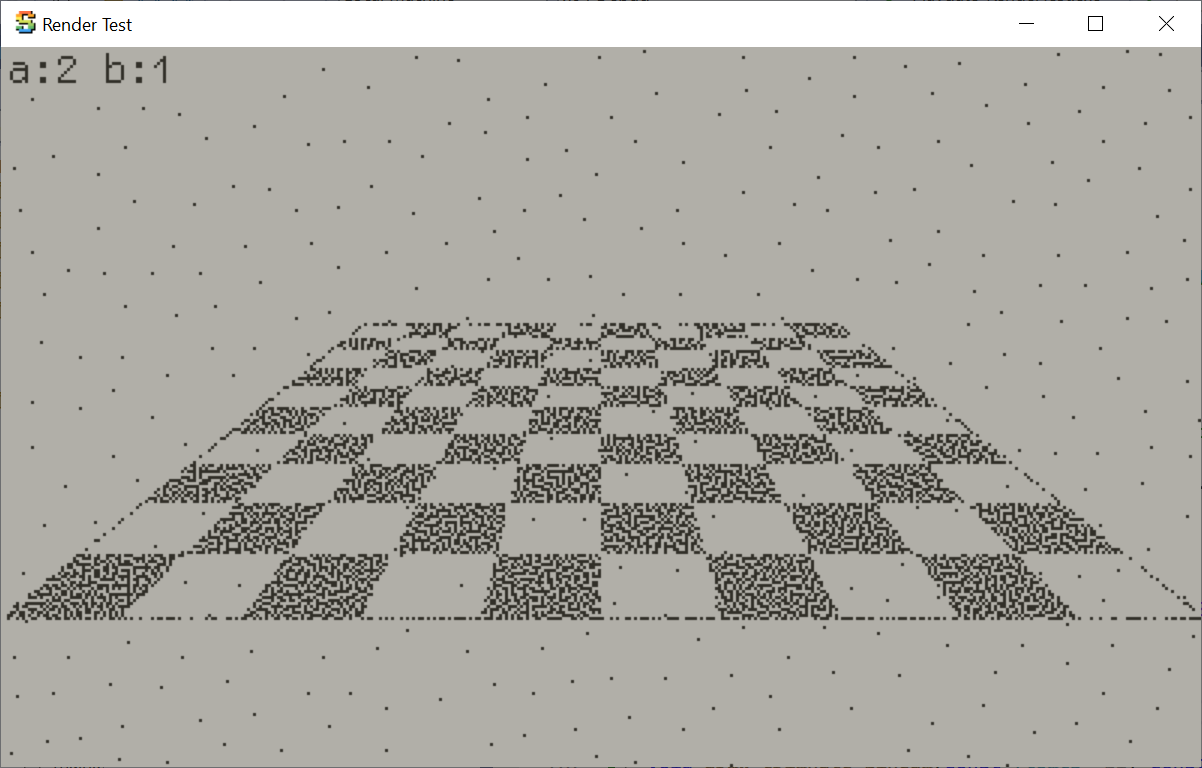
So let’s try it out. Here’s the same scene, with just a pure black/white checkerboard pattern based on mesh
UVs. My existing halfspace/barycentric rasterizer, and the one from Mini3D+ respectively:
Immediate notes:
Yes the scanline rasterizer (for UV based checkerboard at least) is faster using the scanline approach
(54ms halfspace, 33ms scanline),
However the scanline one has more “artifacts”: stray black pixels near edge of plane/cube, and in general
things are shifted by a pixel here and there for some reason. At this point I do not know which one
is “more correct” however, but the difference was bothering me :)
The checkerboard lines are “more wiggly” in the scanline one, most visible on the “floor” object.
I tried to “port” the dithering effect to this rasterizer, but got lost in trying to calculate the correct
UV derivatives (horizontal ones are easy, vertical ones are harder). And the subtle rendering differences
were bothering me, so I decided to actually read up about scanline rasterizers. The seminal series
on them are from 1995/1996, by Chris Hecker for Game Developer Magazine. Hecker has the archive
and the code drop at his website: Perspective Texture Mapping.
So! Taking the initial (fully floating point) rasterizer from Hecker’s code, the UV based checkerboard
renders like this:
This one runs slower than Mini3D+ one (42ms), but does not have stray “black pixels” artifacts around some
mesh edges, and the lines on the floor are no longer wiggly. However, it is slightly different compared
to the halfspace one! Why? This has nothing to do with task at hand, but the fact was bothering me, so…
Comparing Scanline Rasterizers to actual GPU
Again using my “colored debug overlay on PC build” feature, I made a synthetic “test scene” with various cases
of UV mapped geometry, with cases like:
Checkerboard should map exactly 1:1 to pixels, at regular orientation, and geometry being rotated
by exactly 90 degrees,
The same, but geometry coordinates being shifted by less than half a pixel; the result should look the same.
Some geometry that should be exactly one pixel away from screen edge,
Some geometry where each checkerboard square should map to 1.5 (will have aliasing patterns) or 2 (should be exact)
screen pixels.
Several cases of perspective projection,
Several cases of geometry being clipped by screen edges.
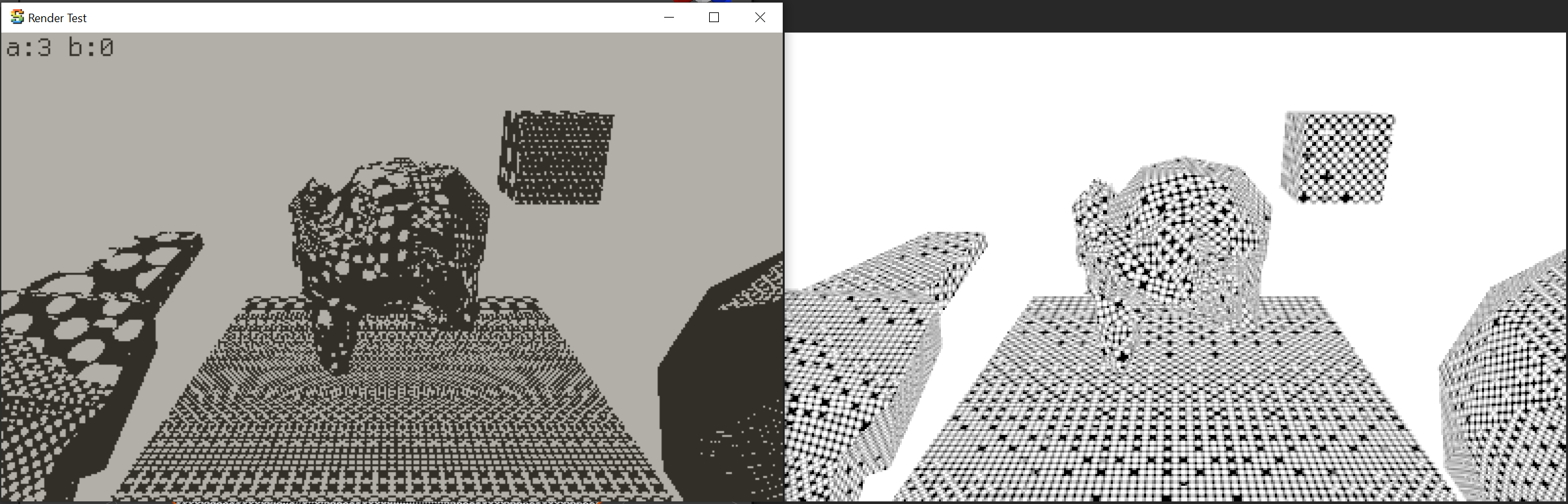
Here’s how it is rendered by the halfspace/barycentric rasterizer:
And then I made a simple Unity shader & C# script that renders exactly the same setup, using actual GPU. Here it is (pasted
into the same window frame as the test app):
Not exactly the same, but really close, I’ll claim this is acceptable (FWIW, GPUs use 8 bits subtexel precision,
whereas my code uses 4 bits).
The rasterizer from Mini3D+ however looks much more different: 1) some cases do not map checkerboard to pixels 1:1,
2) the artifacts between some faces is where the rasterizer is not “watertight” and neighboring faces both
write to the same pixels, 3) some cases where geometry should be exactly one pixel away from screen edge are actually not.
Hecker’s “fully floating point” rasterizer looks better, but still a lot more different from what the GPU does.
The fixed point, sub-dividing affine span rasterizer from Hecker’s code (i.e. the last iteration before the assembly-optimized
one) looks like this however. It fixes some artifacts from the previous one, but still covers slightly different pixels
compared to the GPU, and introduces UV wrapping artifacts at right sides of some planes.
My understanding of the difference is that maybe Hecker’s rasterizer follows pre-Direct3D 10 coordinate conventions,
i.e. where pixel integer coordinates are placed directly on pixel centers. From part 3 of the article series, there’s
this bit:
I chose the corresponding screen coordinates for the destination. I wanted the destination pixel centers to map
exactly to the source pixel centers.
And when talking about how one would map a texture directly to screen at 1:1 ratio, he talks about adding -0.5 offset
to the coordinates. This sounds very much like what people back in Direct3D 8/9 times had to always keep in mind,
or try to solve that automatically in all their shaders.
While this coordinate system intuitively makes sense (pixel centers are at integer coordinates, yay!),
eventually everyone realized it causes more problems down the line. The official
DirectX Specs website minces no words:
D3D9 and prior had a terrible Pixel Coordinate System where the origin was the center of the top left pixel on the RenderTarget
Armed with that guess, I changed
the Hecker’s rasterizer code to shift positions by half a pixel, and remove the complexicated dUdXModifier dance
it was doing. And it became way closer to what the GPU is doing:
The fixed point, subdividing affine Hecker’s rasterizer with the above fix was more correct than
the one from Mini3D+, and running a tiny bit faster by now. So I left only that code, and proceeded with it.
Back to scanline rasterizer
Initial “port” of the Fractal Dithering to the scanline rasterizer was at 102ms, i.e. slower than
halfspace one (63ms). But, I was calculating the UV derivatives for every pixel. Derivatives along
X axis are cheap (just difference to next pixel, which the inner scanline loop already does),
but the vertical ones I was doing in a “slow but correct” way.
The derivatives change fairly slowly across the triangle surface however, so what if I calculate
dU/dY and dV/dY only at the scanline endpoints, and just interpolate it across? This gets us
down to 71ms.
But hey! Maybe I do not need the per-pixel UV derivatives at all? The whole reason for derivatives
is to calculate the dither pattern spacing. But, at least in my scenes, the spacing varies very slowly
(if at all) across the triangle surface. Recall the previous visualization:
I can just calculate the derivatives at triangle vertices, do all the dither spacing
calculations there, and interpolate spacing value across the triangle. 56ms!
Then, do the 3D lookup math directly from fixed point UVs that are interpolated
by the rasterizer. The previous “replace division by exp2” trick by working on floating
point bits is even simpler in fixed point: just shift by the provided integer
amount, and take the fractional bits as needed. 50ms
And the final optimization step I did so far has nothing to do with dithering step itself:
the higher level code was transforming all mesh triangles, calculating their normals for lighting,
then sorting them by distance, and finally rasterizing them back-to-front. Here the triangles
that are back-facing, outside of the screen, or zero-area are culled. I moved the triangle culling
to happen before sorting (there’s no point in sorting invisible triangles anyway), and now
the scanline dither effect runs at 45ms (halfspace one at 60ms).
That’s it for now!
So, this scene runs at 45ms (20-22FPS) on the Playdate device right now, which is much better
than the initial 830ms (1.2FPS). Can it be made yet faster? Most likely.
Does it make it a practical effect on the Playdate? Dunno, it is quite heavy and at this low
resolution, does not look very good (it does not help that some approximations/simplifications
I did actually increase dither pattern aliasing).
But hey, this was fun! I learned a thing or three. And if you want either a scanline or
a halfspace rasterizer for Playdate that very closely matches what actual GPU would do
(i.e. it is a more correct rasterizer than mini3d from Playdate SDK or Mini3D+), you can find
them at github.com/aras-p/playdate-dither3d
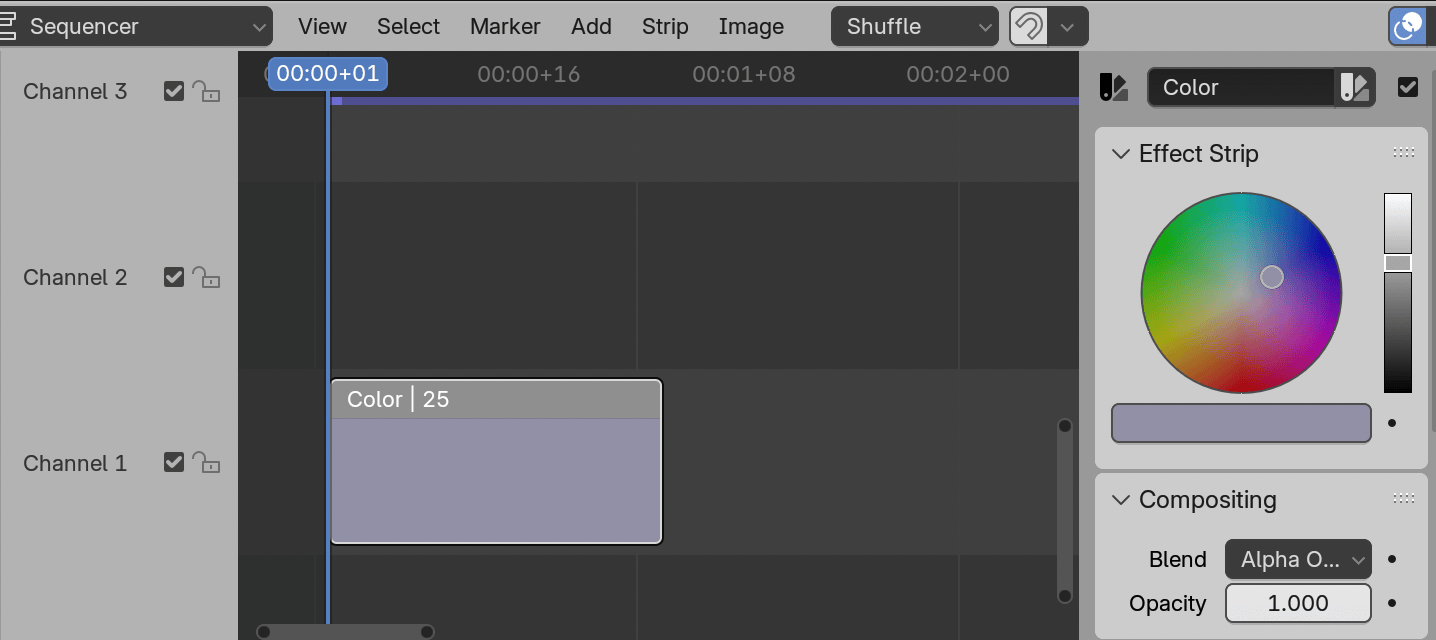
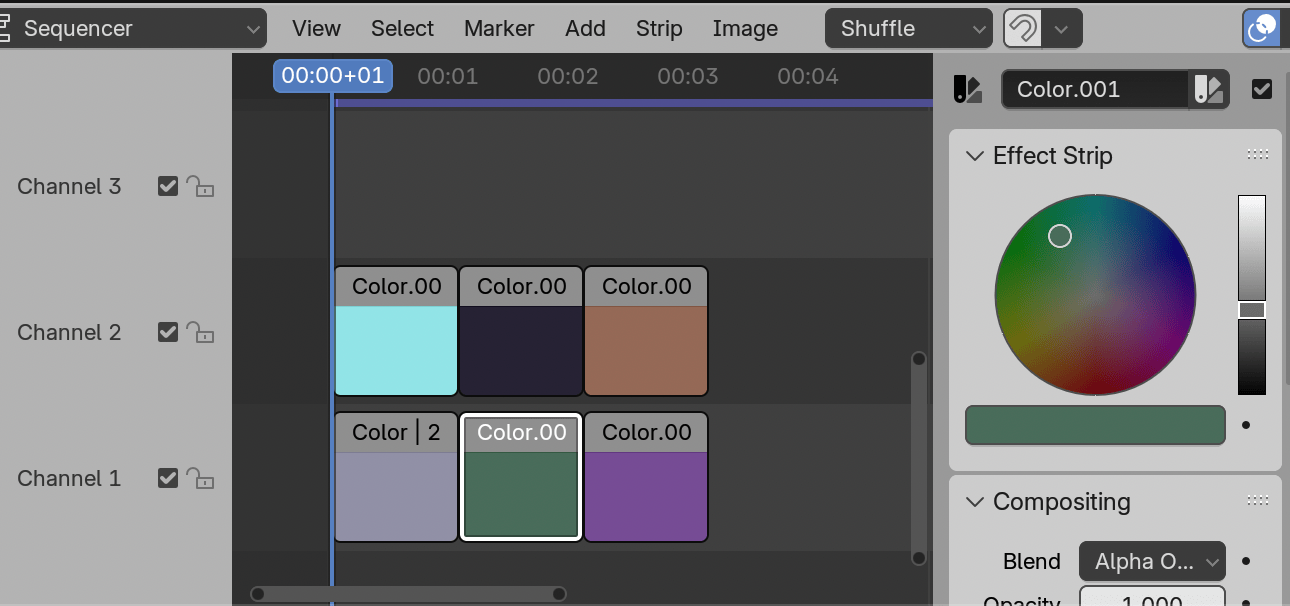
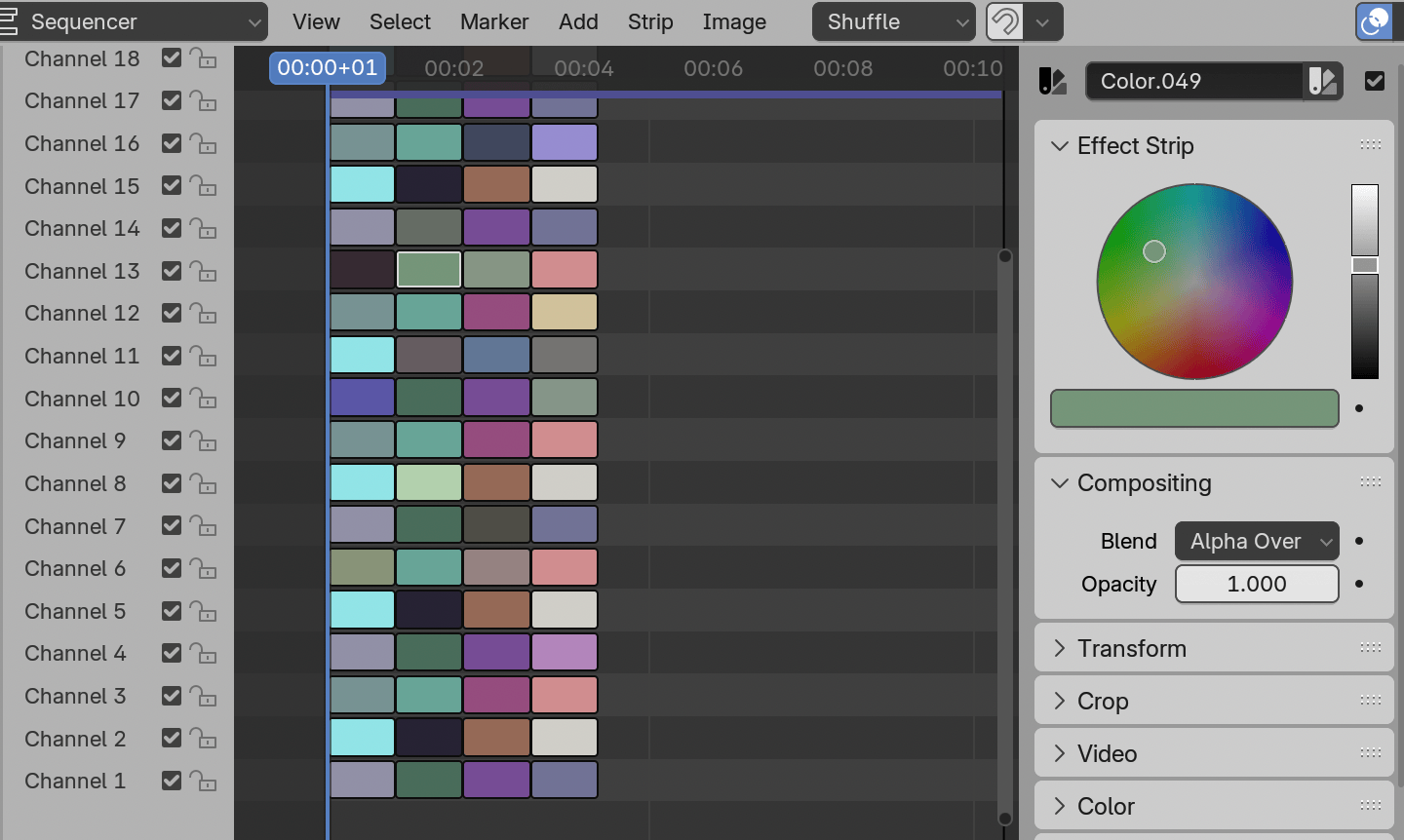
It is a modal blender operator that loads doom file, creates
VSE timeline full of color strips (80 columns, 60 rows), listens to
keyboard input for player control, renders doom frame and updates the
VSE color strip colors to match the rendered result. Escape key finishes
the operator.
All the Doom-specific heavy lifting is in render.py, written by
Mark Dufour and is completely unrelated to Blender. It is just a tiny
pure Python Doom loader/renderer. I took it from
“Minimal DOOM WAD renderer”
and made two small edits to avoid division by zero exceptions that I was getting.
Performance
This runs pretty slow (~3fps) in current Blender (4.1 .. 4.4) 😢
I noticed that is was slow when I was “running it”, but when stopped, navigating the VSE
timeline with all the strips still there was buttery smooth. And so, being an idiot that I am,
I was “rah rah, Doom rendering is done in pure Python, of course it is slow!”
Yes, Python is slow, and yes, the minimal Doom renderer (in exactly 666 lines of code – nice!)
is not written in “performant Python”. But turns out… performance problems are not there.
Another case for “never guess, always look at what is going on”.
The pure-python Doom renderer part takes 7 milliseconds to render a 80x60 “frame”. Could it be
faster? Probably. But… it takes 300 milliseconds to update the colors of all the VSE strips.
Note that in Blender 4.0 or earlier it runs even slower, because redrawing the
VSE timeline with 4800 strips takes about 100 milliseconds; that is no longer slow
(1-2ms) in later versions due to what I did a year ago.
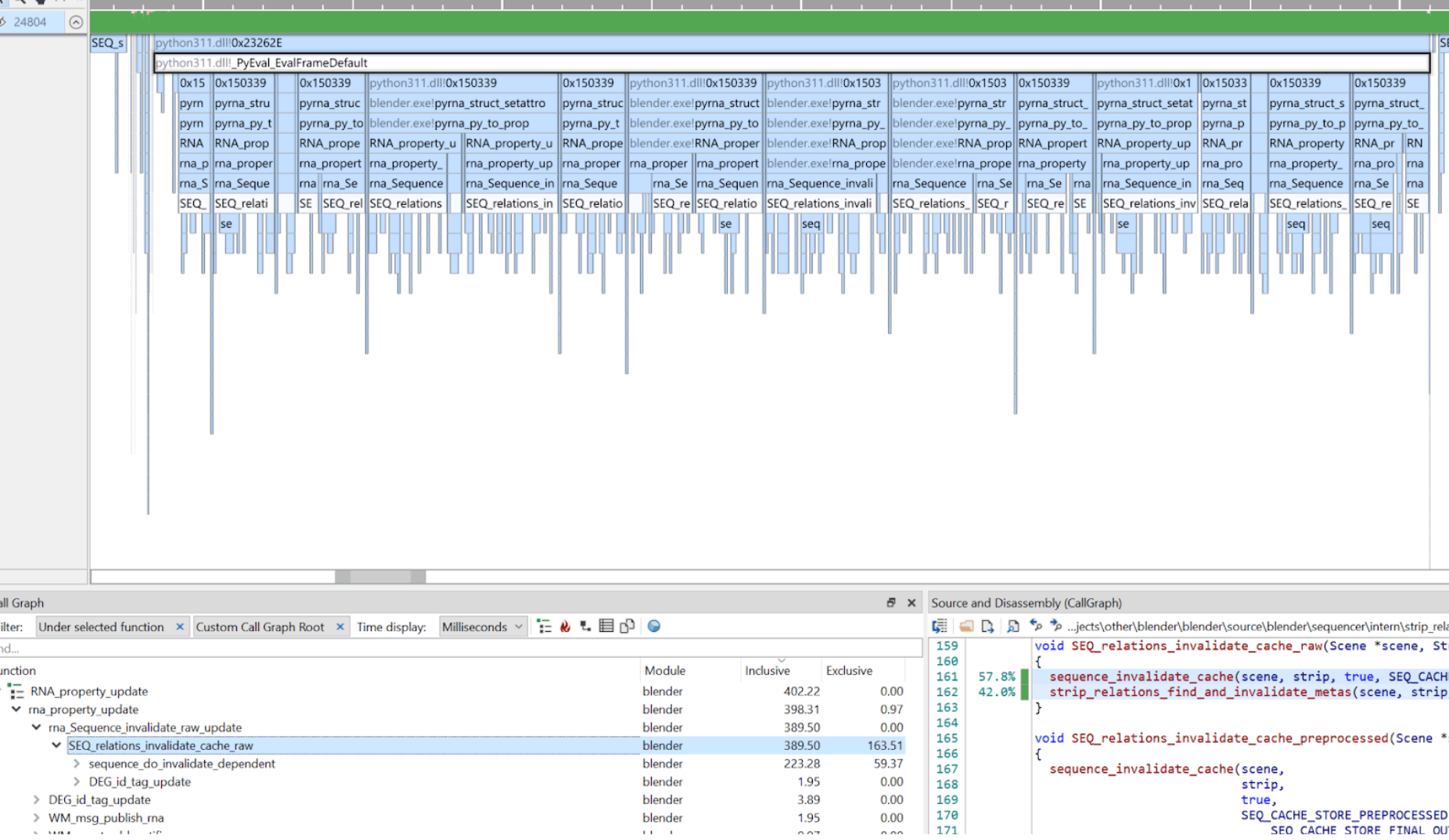
Why does it take 300 milliseconds to update the strip colors? For that of course
I brought up Superluminal and it tells me the problem is cache
invalidation:
Luckily, cache invalidation is one of the easiest things in computer science, right? 🧌
Anyway, this looks like another case of accidental quadratic complexity: for each strip that gets
a new color set on it, there’s code that 1) invalidates any cached results for that strip (ok), and
2) tries to find whether this strip belongs to any meta-strips to invalidate those
(which scans all the strips), and 3) tries to find which strips intersect the strip horizontal range
(i.e. are “composited above it”), and invalidate partial results of those – this again scans
all the strips.
Step 2 above can be easily addressed, I think, as the codebase already maintains data structures for
finding which strips are part of which meta-strips, without resorting to “look at everything”.
Step 3 is slightly harder in the current code. However, half a year ago during
VSE workshop we talked about how the
whole caching system within VSE is maybe too complexicated for no good reason.
Now that I think about it, I think most or all of that extra cost could be removed, if
Someone™️ would rewrite VSE cache to be along the lines of how we discussed at the workshop.
Hmm. Maybe I have some work to do. And then the VSE timeline could be properly doomed.