More Hash Function Tests
In the previous post, I wrote about non-crypto hash functions, and did some performance tests. Turns out, it’s great to write about stuff! People at the comments/twitter/internets pointed out more things I should test. So here’s a follow-up post.
What is not the focus
This is about algorithms for “hashing some amount of bytes”, for use either in hashtables or for checksum / uniqueness detection. Depending on your situation, there’s a whole family of algorithms for that, and I am focusing on only one: non-cryptographic fast hash functions.
- This post is not about cryptographic hashes. Do not read below if you need to hash passwords, sensitive data going through untrusted medium and so on. Use SHA-1, SHA-2, BLAKE2 and friends.
- Also, I’m not focusing on algorithms that are designed to prevent possible hashtable Denial-of-Service attacks. If something comes from the other side of the internet and ends up inserted into your hashtable, then to prevent possible worst-case O(N) hashtable behavior you’re probably off by using a hash function that does not have known “hash flooding” attacks. SipHash seems to be popular now.
- If you are hashing very small amounts of data of known size (e.g. single integers or two floats or whatever), you should probably use specialized hashing algorithms for those. Here are some integer hash functions, or 2D hashing with Weyl, or perhaps you could take some other algorithm and just specialize it’s code for your known input size (e.g. xxHash for a single integer).
- I am testing 32 and 64 bit hash functions here. If you need larger hashes, quite likely some of these functions might be suitable (e.g. SpookyV2 always produces 128 bit hash).
When testing hash functions, I have not gone to great lengths to get them compiling properly or setting up all the magic flags on all my platforms. If some hash function works wonderfully when compiled on Linux Itanium box with an Intel compiler, that’s great for you, but if it performs poorly on the compilers I happen to use, I will not sing praises for it. Being in the games industry, I care about things like “what happens in Visual Studio”, and “what happens on iOS”, and “what happens on PS4”.
More hash function tests!
I’ve updated my hash testbed on github (use revision 9b59c91cf) to include more algorithms, changed tests a little, etc etc.
I checked both “hashing data that is aligned” (16-byte aligned address of data to hash), and unaligned data. Everywhere I tested, there wasn’t a notable performance difference that I could find (but then, I have not tested old ARM CPUs or PowerPC based ones). The only visible effect is that MurmurHash and SpookyHash don’t properly work in asm.js / Emscripten compilation targets, due to their usage of unaligned reads. I’d assume they probably don’t work on some ARM/PowerPC platforms too.
Hash functions tested below:
xxHash32andxxHash64- xxHash.City32andCity64- CityHash.Mum- mum-hash.Farm32andFarm64- FarmHash.SpookyV2-64- SpookyHash V2.Murmur2A,Murmur3-32,Murmur3-X64-64- MurmurHash family.
These are the main functions that are interesting. Because people kept on asking, and because “why not”, I’ve included a bunch of others too:
SipRef- SipHash-2-4 reference implementation. Like mentioned before, this one is supposedly good for avoiding hash flooding attacks.MD5-32,SHA1-32,CRC32- simple implementations of well-known hash functions (from SMHasher test suite). Again, these mostly not in the category I’m interested in, but included to illustrate the performance differences.FNV-1a,FNV-1amod- FNV hash and modified version.djb2,SDBM- both from this site.
Performance Results
Windows / Mac
macOS results, compiled with Xcode 7.3 (clang-based) in Release 64 bit build. Late 2013 MacBookPro:

Windows results, compiled with Visual Studio 2015 in Release 64 bit build. Core i7-5820K:
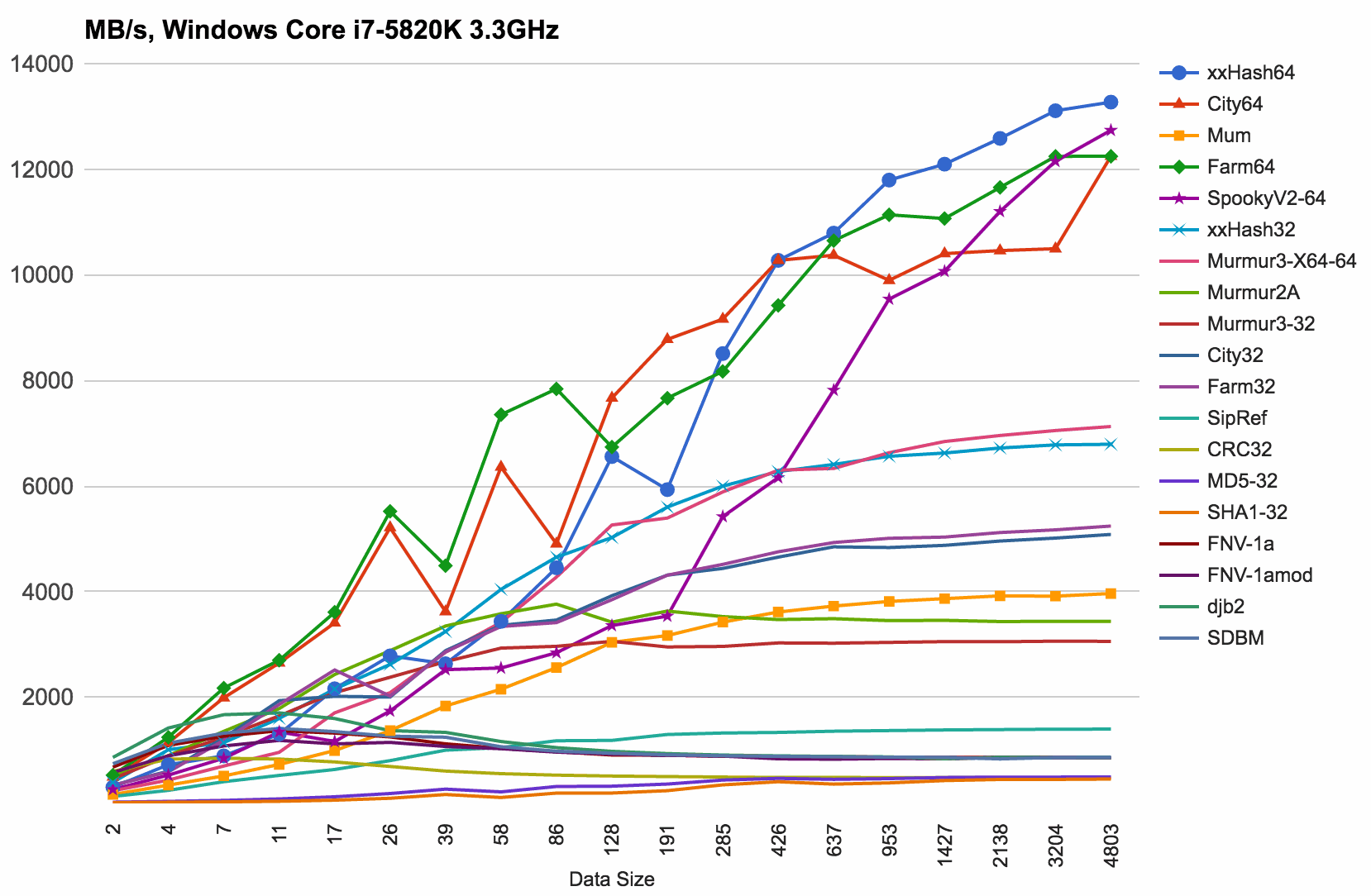
Notes:
- Performance profiles of these are very similar.
- xxHash64 wins at larger (0.5KB+) data sizes, followed closely by 64 bit FarmHash and CityHash.
- At smaller data sizes (10-500 bytes), FarmHash and CityHash look very good!
- mum-hash is much slower on Visual Studio. At first I thought it’s
_MUM_UNALIGNED_ACCESSmacro that was not handling VS-specific defines (_M_AMD64and_M_IX86) properly (see PR). Turns out it’s not; the speed difference comes from_MUM_USE_INT128which only kicks in on GCC-based compilers. mum-hash would be pretty competetive otherwise.
Windows 32 bit results, compiled with Visual Studio 2015 in Release 32 bit build. Core i7-5820K:
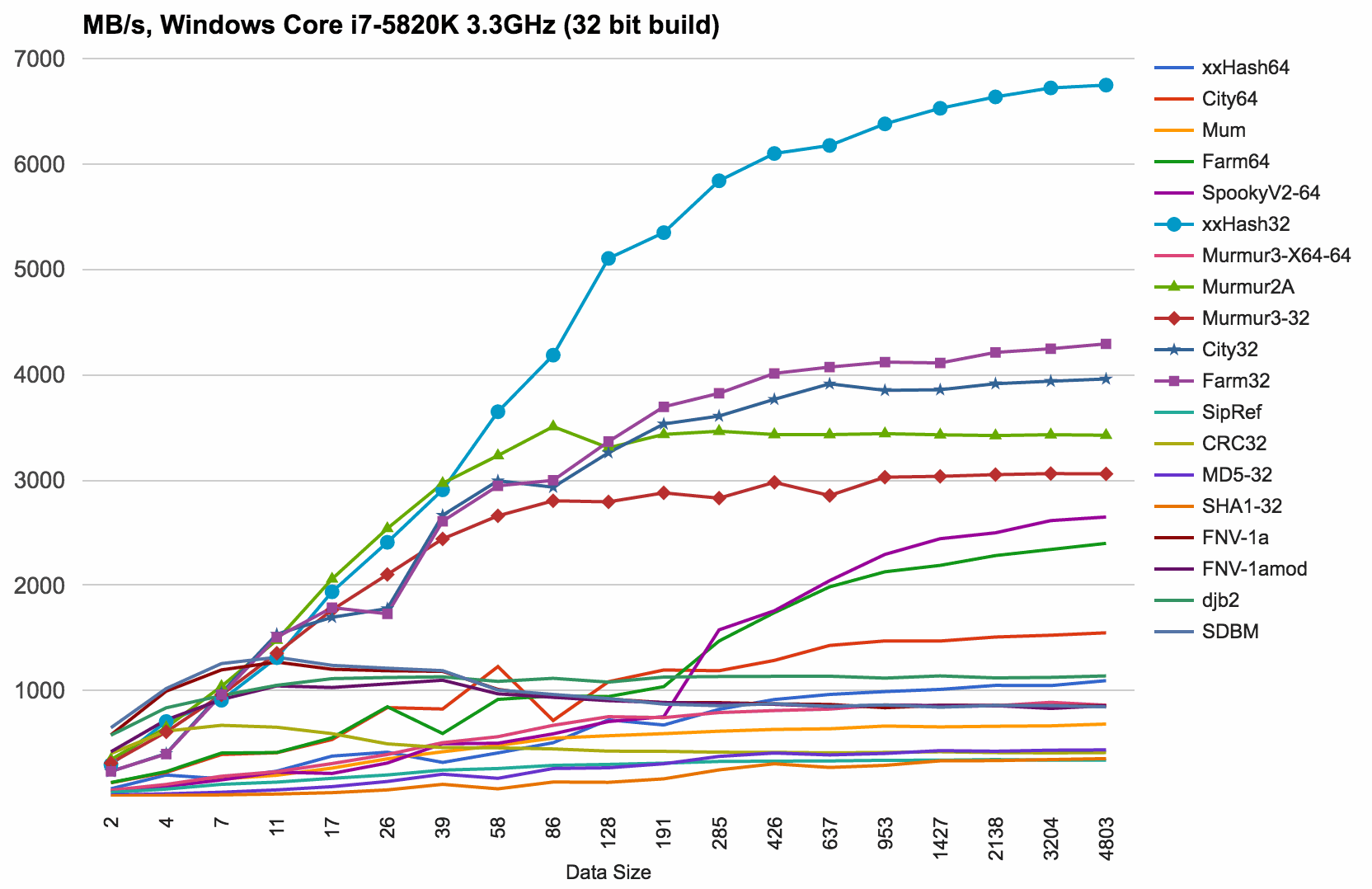
On a 32 bit platform / compilation target, things change quite a bit!
- All 64 bit hash functions are slow. For example, xxHash64 frops from 13GB/s to 1GB/s. Use a 32 bit hash function when on a 32 bit target!
- xxHash32 wins by a good amount.
Note on FarmHash – whole idea behind it is that it uses CPU-specific optimizations (that also change the computed hash value). The graphs above are using default compilation settings on both macOS and Windows. However, on macOS enabling SSE4.2 instructions in Xcode settings makes it much faster at larger data sizes:
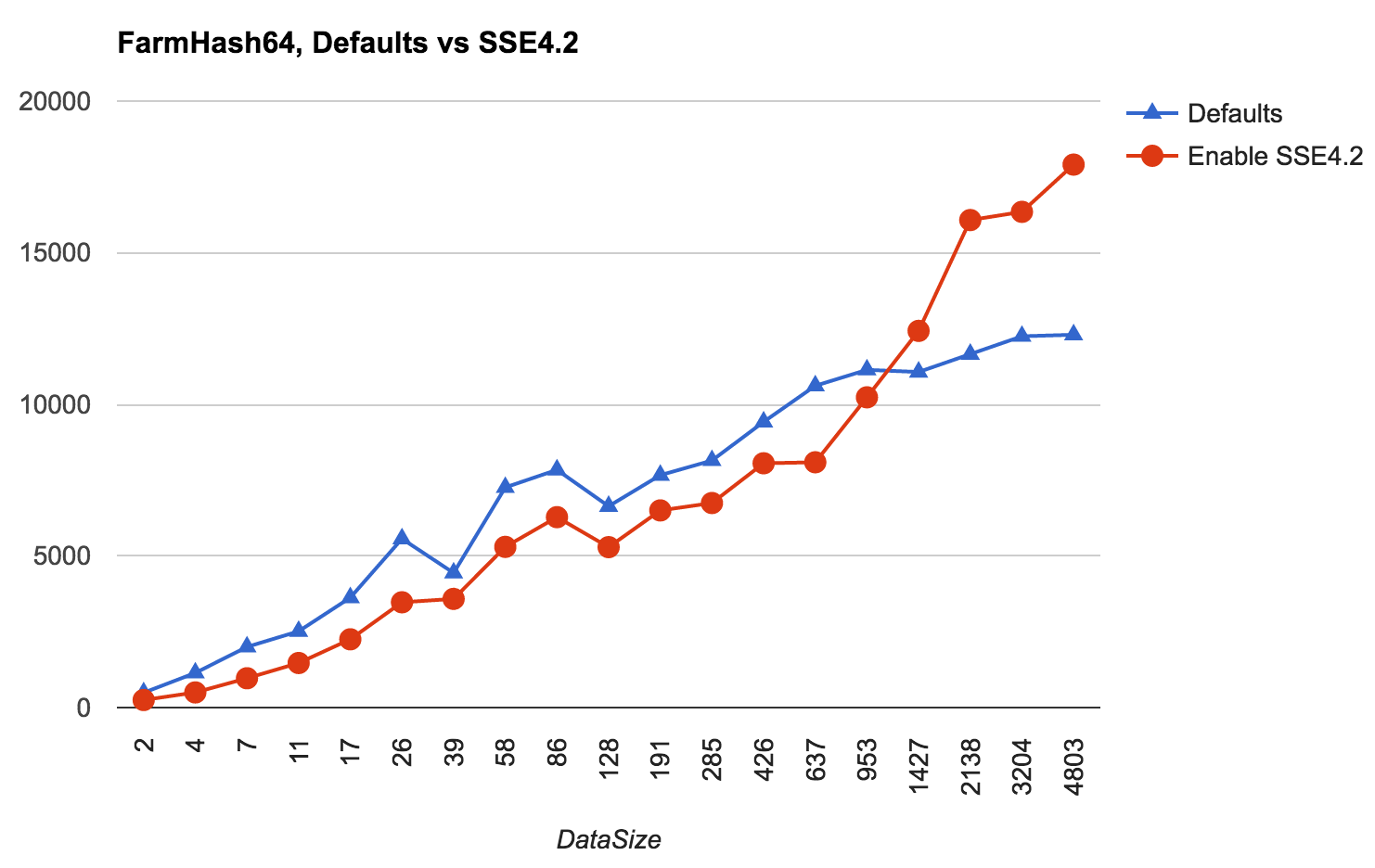
With SSE4.2 enabled, FarmHash64 handily wins against xxHash64 (17.9GB/s vs 12.8GB/s) for data that is larger than 1KB.
However, that requires compiling with SSE4.2, at my work I can’t afford that. Enabling the same options on XboxOne
makes it slower :( Enabling just FARMHASH_ASSUME_AESNI makes the 32 bit FarmHash faster on XboxOne, but does
not affect performance of the 64 bit hash. FarmHash also does not have any specific optimizations for ARM CPUs,
so my verdict with it all is “not worth bothering” – afterall the impressive SSE4.2 speedup is only for large data sizes.
Mobile
iPhone SE (A9 CPU) results, compiled with Xcode 7.3 (clang-based) in Release 64 bit build:
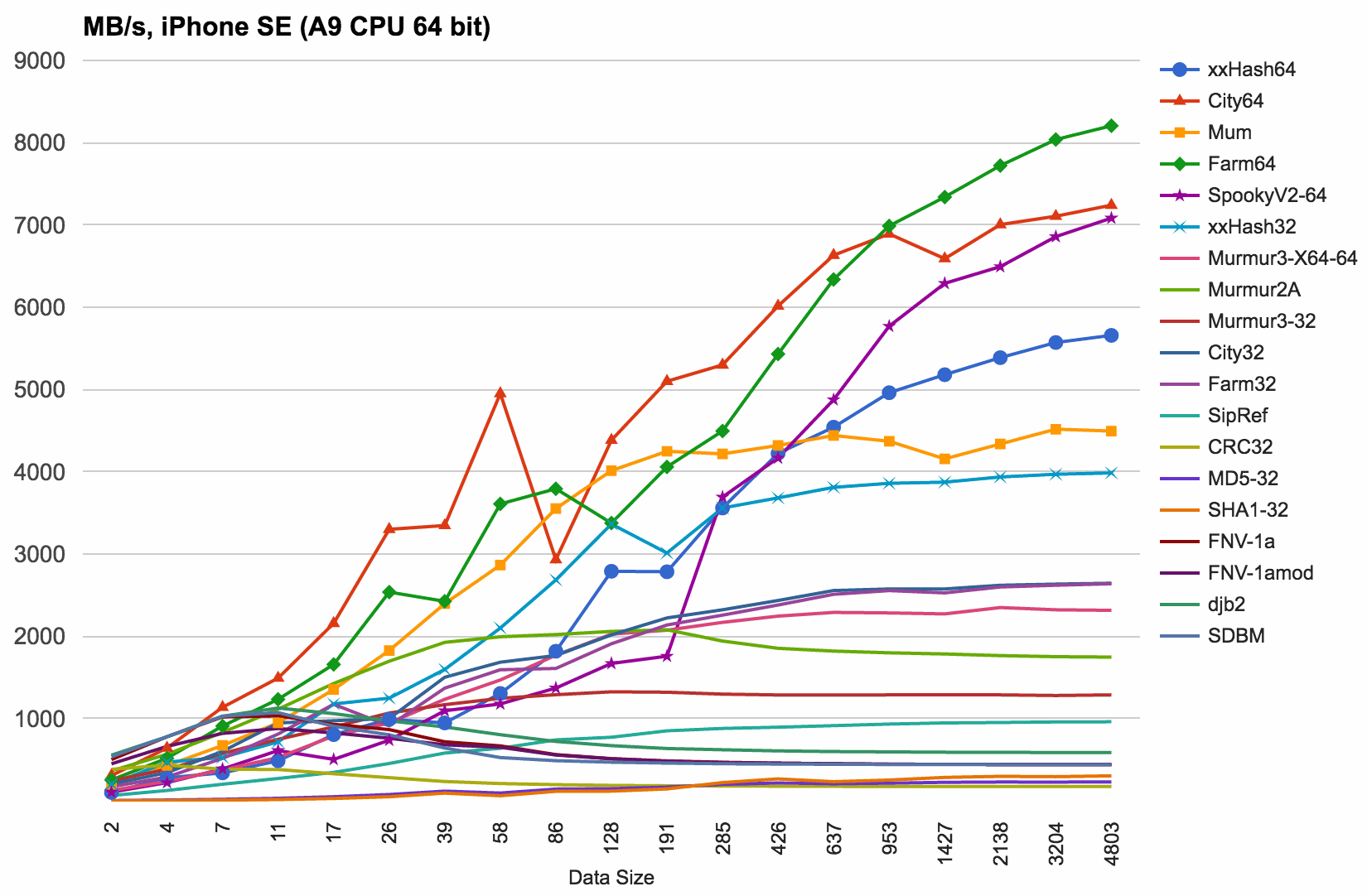
- xxHash never wins here; CityHash and FarmHash are fastest across the whole range.
iPhone SE 32 bit results:
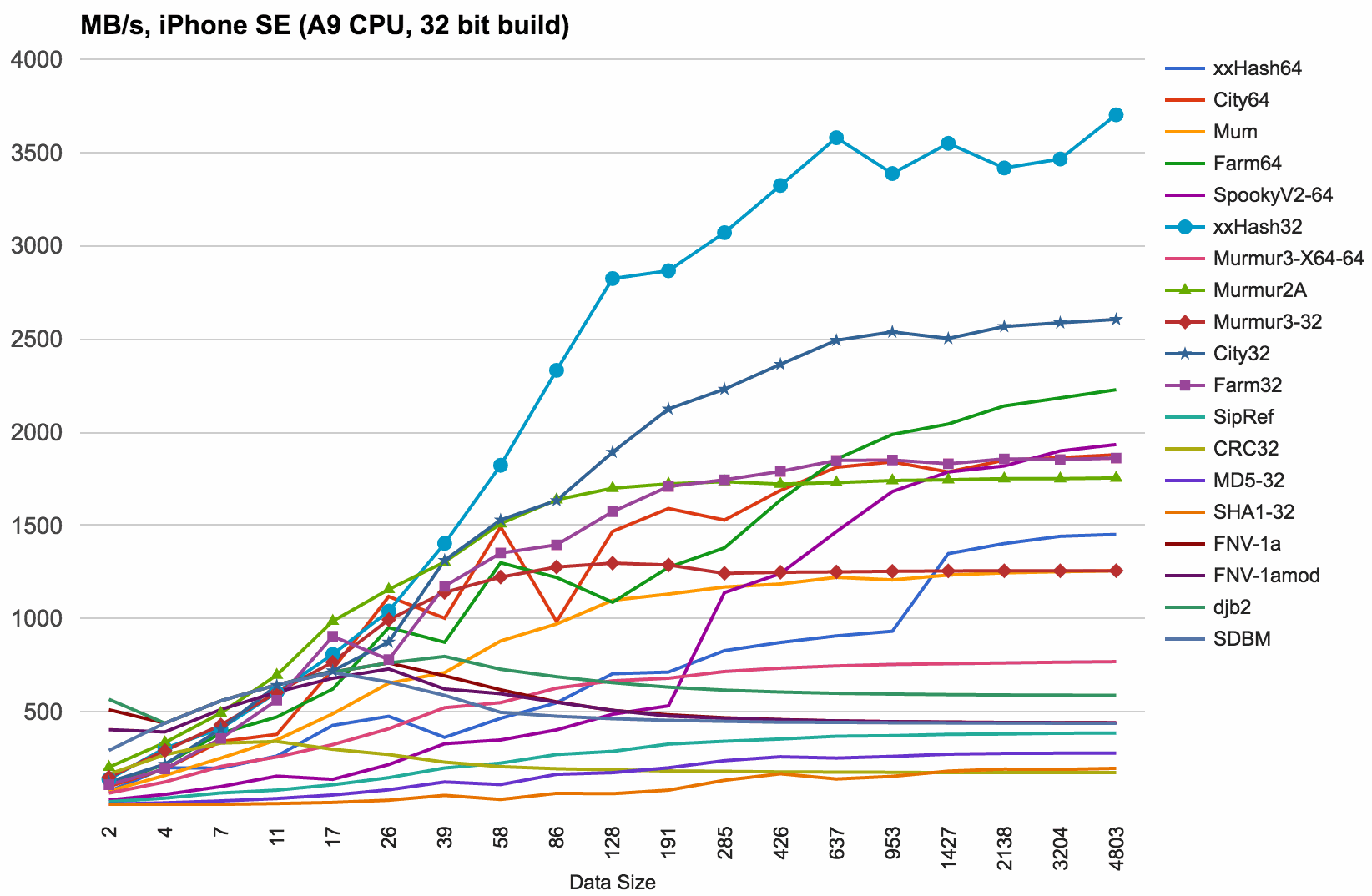
This is similar to Windows 32 bit: 64 bit hash functions are slow, xxHash32 wins by a good amount.
Console
Xbox One (AMD Jaguar 1.75GHz CPU) results, compiled Visual Studio 2015 in Release mode:
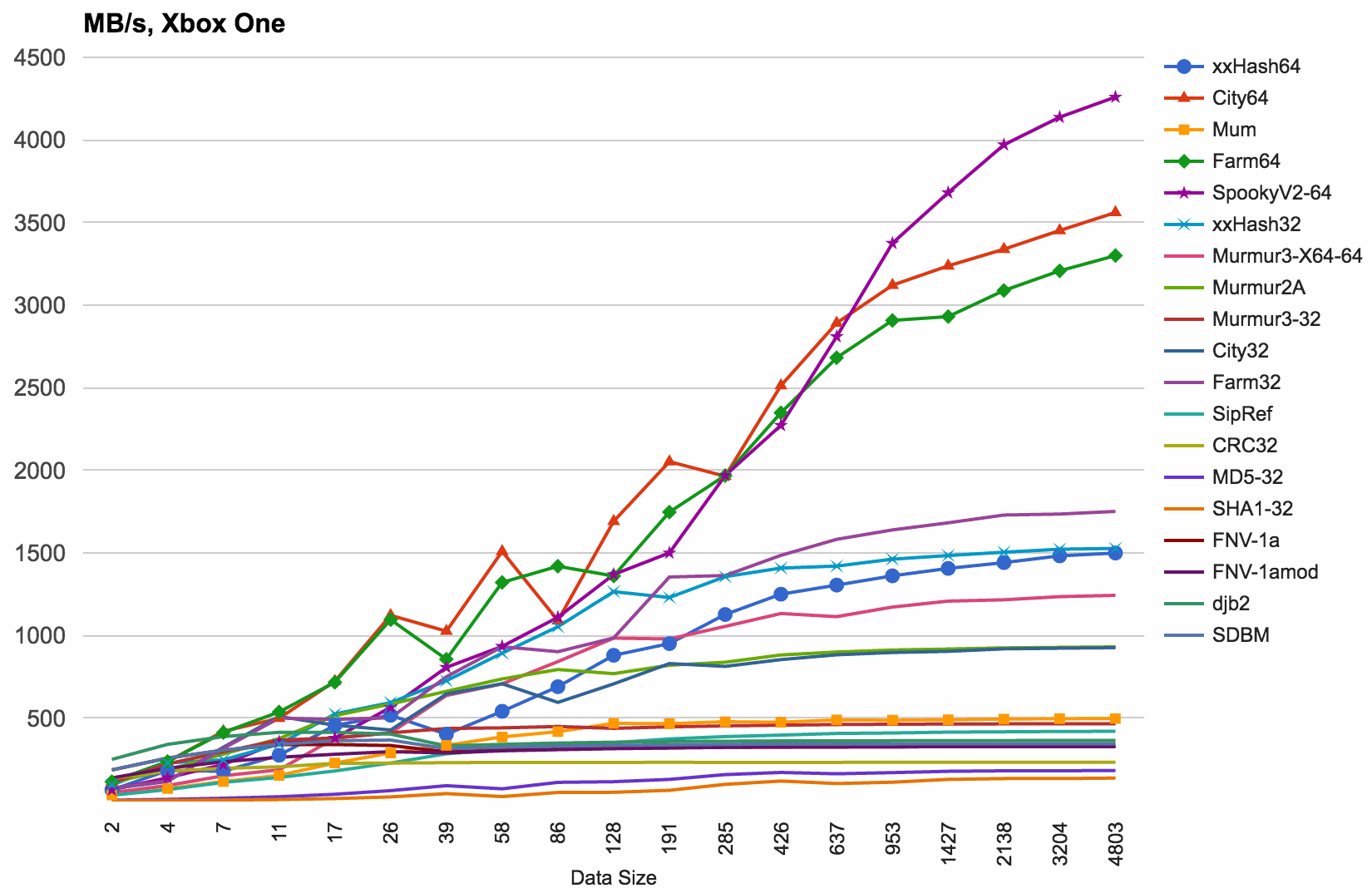
- Similar to iPhone results, xxHash is quite a bit slower than CityHash and FarmHash. xxHash uses 64 bit multiplications heavily, whereas others mostly do shifts and logic ops.
- SpookyHash wins at larger data sizes.
JavaScript
JavaScript (asm.js via Emscripten) results, running on late 2013 MacBookPro.
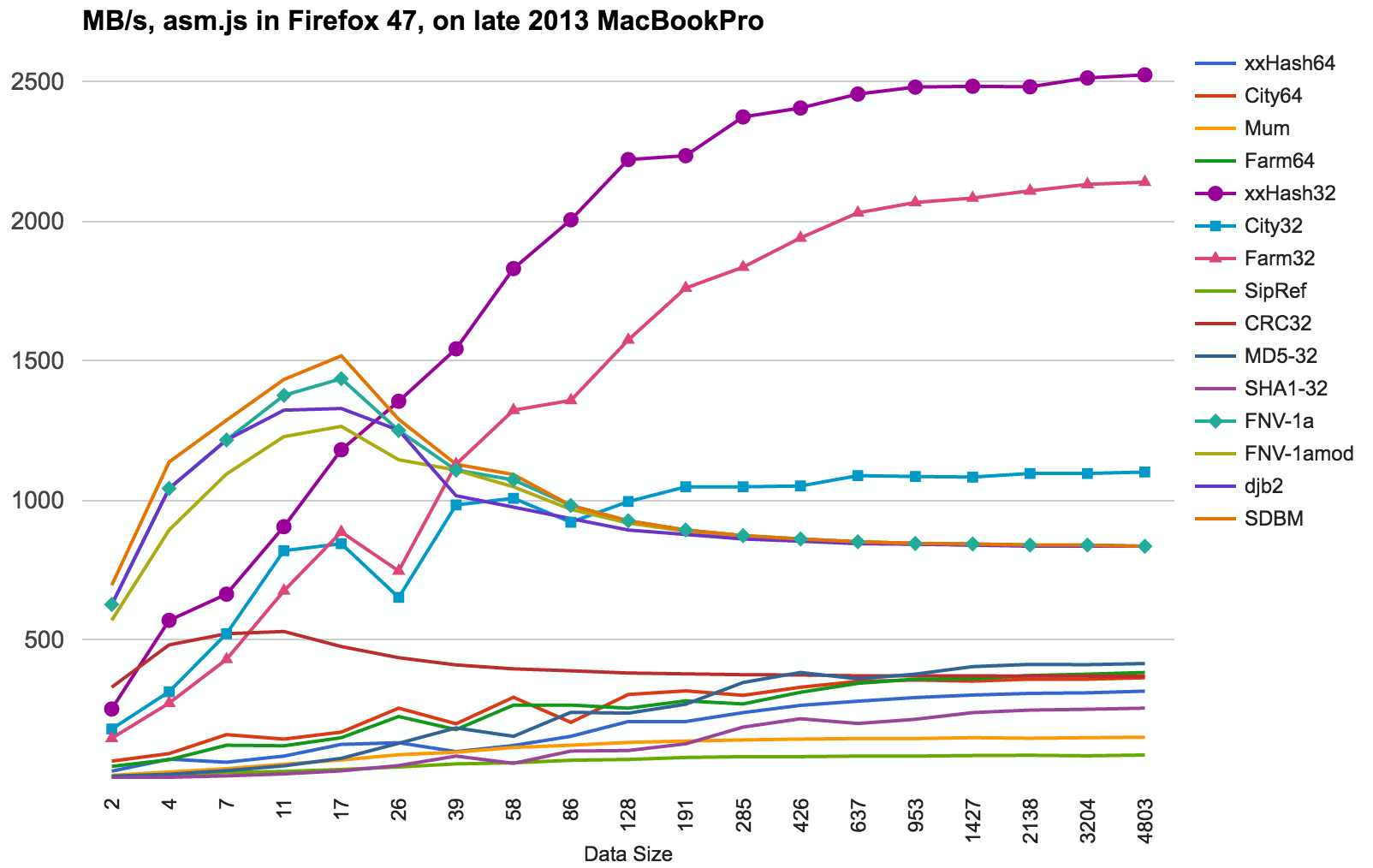
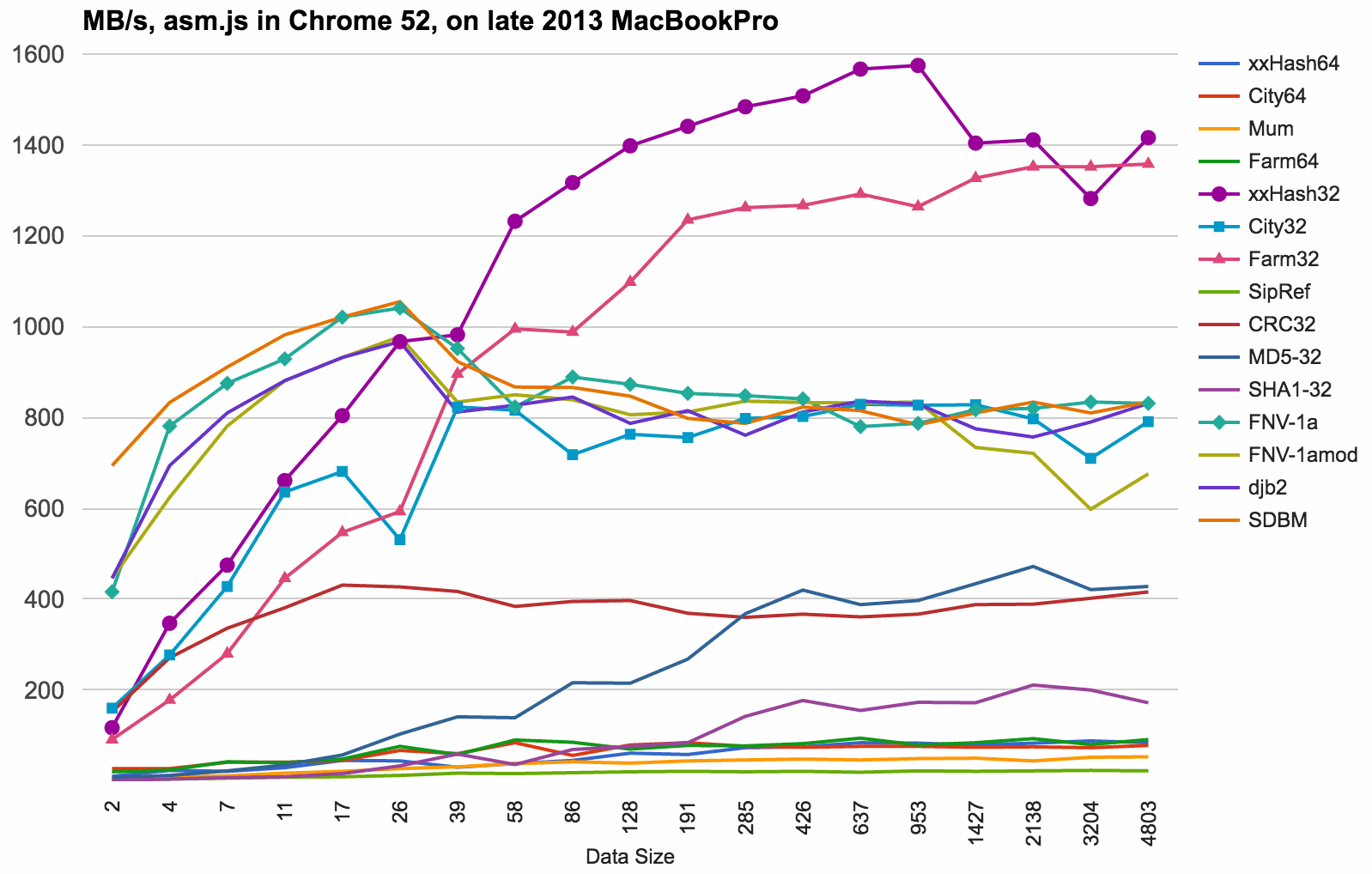
- asm.js is in all practical sense a 32 bit compilation target; 64 bit integer operations are slow.
- xxHash32 wins, followed by FarmHash32.
- At smaller (<25 bytes) data sizes, simple hashes like FNV-1a, SDBM or djb2 are useful.
Throughput tables
Performance at large data sizes (~4KB), in GB/s:
| Hash | 64 bit | 32 bit | ||||||
|---|---|---|---|---|---|---|---|---|
| Win | Mac | iPhoneSE | XboxOne | Win | iPhoneSE | asm.js Firefox | asm.js Chrome | |
| xxHash64 | 13.2 | 12.8 | 5.7 | 1.5 | 1.1 | 1.5 | 0.3 | 0.1 |
| City64 | 12.2 | 12.2 | 7.2 | 3.6 | 1.6 | 1.9 | 0.4 | 0.1 |
| Mum | 4.0 | 9.5 | 4.5 | 0.5 | 0.7 | 1.3 | 0.1 | 0.1 |
| Farm64 | 12.3 | 11.9 | 8.2 | 3.3 | 2.4 | 2.2 | 0.4 | 0.1 |
| SpookyV2-64 | 12.8 | 12.5 | 7.1 | 4.3 | 2.6 | 1.9 | -- | -- |
| xxHash32 | 6.8 | 6.6 | 4.0 | 1.5 | 6.7 | 3.7 | 2.5 | 1.4 |
| Murmur3-X64-64 | 7.1 | 5.8 | 2.3 | 1.2 | 0.9 | 0.8 | -- | -- |
| Murmur2A | 3.4 | 3.3 | 1.7 | 0.9 | 3.4 | 1.8 | -- | -- |
| Murmur3-32 | 3.1 | 2.7 | 1.3 | 0.5 | 3.1 | 1.3 | -- | -- |
| City32 | 5.1 | 4.9 | 2.6 | 0.9 | 4.0 | 2.6 | 1.1 | 0.8 |
| Farm32 | 5.2 | 4.3 | 2.6 | 1.8 | 4.3 | 1.9 | 2.1 | 1.4 |
| SipRef | 1.4 | 1.6 | 1.0 | 0.4 | 0.3 | 0.4 | 0.1 | 0.0 |
| CRC32 | 0.5 | 0.5 | 0.2 | 0.2 | 0.4 | 0.2 | 0.4 | 0.4 |
| MD5-32 | 0.5 | 0.3 | 0.2 | 0.2 | 0.4 | 0.3 | 0.4 | 0.4 |
| SHA1-32 | 0.5 | 0.5 | 0.3 | 0.1 | 0.4 | 0.2 | 0.3 | 0.2 |
| FNV-1a | 0.9 | 0.8 | 0.4 | 0.3 | 0.9 | 0.4 | 0.8 | 0.8 |
| FNV-1amod | 0.9 | 0.8 | 0.4 | 0.3 | 0.9 | 0.4 | 0.8 | 0.7 |
| djb2 | 0.9 | 0.8 | 0.6 | 0.4 | 1.1 | 0.6 | 0.8 | 0.8 |
| SDBM | 0.9 | 0.8 | 0.4 | 0.3 | 0.8 | 0.4 | 0.8 | 0.8 |
Performance at medium size (128 byte) data, in GB/s:
| Hash | 64 bit | 32 bit | ||||||
|---|---|---|---|---|---|---|---|---|
| Win | Mac | iPhoneSE | XboxOne | Win | iPhoneSE | asm.js Firefox | asm.js Chrome | |
| xxHash64 | 6.6 | 6.2 | 2.8 | 0.9 | 0.7 | 0.7 | 0.2 | 0.1 |
| City64 | 7.6 | 7.6 | 4.4 | 1.7 | 1.1 | 1.5 | 0.3 | 0.1 |
| Mum | 3.2 | 7.6 | 4.1 | 0.5 | 0.6 | 1.1 | 0.1 | 0.0 |
| Farm64 | 6.6 | 5.7 | 3.4 | 1.4 | 0.9 | 1.1 | 0.3 | 0.1 |
| SpookyV2-64 | 3.4 | 3.2 | 1.7 | 1.4 | 0.7 | 0.5 | -- | -- |
| xxHash32 | 5.1 | 5.3 | 3.4 | 1.3 | 5.1 | 2.8 | 2.2 | 1.4 |
| Murmur3-X64-64 | 5.3 | 4.3 | 2.1 | 1.0 | 0.8 | 0.7 | -- | -- |
| Murmur2A | 3.6 | 3.0 | 2.1 | 0.8 | 3.3 | 1.7 | -- | -- |
| Murmur3-32 | 3.1 | 2.3 | 1.3 | 0.4 | 2.8 | 1.3 | -- | -- |
| City32 | 4.0 | 3.6 | 2.0 | 0.7 | 3.3 | 1.9 | 1.0 | 0.8 |
| Farm32 | 3.9 | 3.2 | 1.9 | 1.0 | 3.4 | 1.6 | 1.6 | 1.1 |
| SipRef | 1.2 | 1.3 | 0.8 | 0.4 | 0.3 | 0.3 | 0.1 | 0.0 |
| CRC32 | 0.5 | 0.5 | 0.2 | 0.2 | 0.4 | 0.2 | 0.4 | 0.4 |
| MD5-32 | 0.3 | 0.2 | 0.2 | 0.1 | 0.3 | 0.2 | 0.2 | 0.2 |
| SHA1-32 | 0.2 | 0.2 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 |
| FNV-1a | 0.9 | 1.0 | 0.5 | 0.3 | 0.9 | 0.5 | 0.9 | 0.9 |
| FNV-1amod | 0.9 | 0.9 | 0.5 | 0.3 | 0.9 | 0.5 | 0.9 | 0.8 |
| djb2 | 1.0 | 0.9 | 0.7 | 0.4 | 1.1 | 0.7 | 0.9 | 0.8 |
| SDBM | 0.9 | 0.9 | 0.5 | 0.3 | 0.9 | 0.5 | 0.9 | 0.8 |
Performance at small size (17 byte) data, in GB/s:
| Hash | 64 bit | 32 bit | ||||||
|---|---|---|---|---|---|---|---|---|
| Win | Mac | iPhoneSE | XboxOne | Win | iPhoneSE | asm.js Firefox | asm.js Chrome | |
| xxHash64 | 2.1 | 1.8 | 0.5 | 0.5 | 0.4 | 0.4 | 0.1 | 0.0 |
| City64 | 3.4 | 3.0 | 1.5 | 0.7 | 0.5 | 0.7 | 0.2 | 0.0 |
| Mum | 1.2 | 2.6 | 0.9 | 0.2 | 0.3 | 0.5 | 0.1 | 0.0 |
| Farm64 | 3.6 | 2.6 | 1.2 | 0.7 | 0.6 | 0.6 | 0.1 | 0.0 |
| SpookyV2-64 | 1.2 | 1.0 | 0.6 | 0.4 | 0.2 | 0.1 | -- | -- |
| xxHash32 | 2.2 | 2.0 | 0.7 | 0.5 | 1.9 | 0.8 | 1.2 | 0.8 |
| Murmur3-X64-64 | 1.7 | 1.3 | 0.5 | 0.4 | 0.3 | 0.3 | -- | -- |
| Murmur2A | 2.4 | 1.8 | 1.1 | 0.5 | 2.1 | 1.0 | -- | -- |
| Murmur3-32 | 2.1 | 1.5 | 0.8 | 0.4 | 1.8 | 0.8 | -- | -- |
| City32 | 2.1 | 1.9 | 0.9 | 0.5 | 1.7 | 0.7 | 0.8 | 0.7 |
| Farm32 | 2.5 | 2.0 | 0.8 | 0.5 | 1.8 | 0.9 | 0.9 | 0.5 |
| SipRef | 0.6 | 0.6 | 0.3 | 0.2 | 0.2 | 0.1 | 0.0 | 0.0 |
| CRC32 | 0.8 | 0.7 | 0.4 | 0.2 | 0.6 | 0.3 | 0.5 | 0.4 |
| MD5-32 | 0.1 | 0.1 | 0.0 | 0.0 | 0.1 | 0.0 | 0.1 | 0.0 |
| SHA1-32 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| FNV-1a | 1.3 | 1.5 | 1.0 | 0.3 | 1.2 | 0.7 | 1.4 | 1.0 |
| FNV-1amod | 1.1 | 1.4 | 0.9 | 0.3 | 1.0 | 0.7 | 1.3 | 0.9 |
| djb2 | 1.6 | 1.6 | 1.1 | 0.4 | 1.1 | 0.7 | 1.3 | 0.9 |
| SDBM | 1.4 | 1.3 | 1.1 | 0.4 | 1.2 | 0.7 | 1.5 | 1.0 |
A note on hash quality
As far as I’m concerned, all the 64 bit hashes are excellent quality.
Most of the 32 bit hashes are pretty good too on the data sets I tested.
SDBM produces more collisions than others on binary-like data (various struct memory dumps, 5742 entries, average length 55 bytes – SDBM had 64 collisions, all the other hashes had zero). You could have a way worse hash function than SDBM of course, but then functions like FNV-1a are about as simple to implement, and seem to behave better on binary data.
A note on hash consistency
Some of the hash functions do not produce identical output on various platforms. Among the ones I tested, mum-hash and FarmHash produced different output depending on compiler and platform used.
It’s very likely that most of the above hash functions produce different output if ran on a big-endian CPU. I did not have any platform like that to test on.
Some of the hash functions depend on unaligned memory reads being possible – most notably Murmur and Spooky. I had to change Spooky to work
on ARM 32 bit (define ALLOW_UNALIGNED_READS to zero in the source code). Murmur and Spooky did produce wrong results on asm.js
(no crash, just different hash results and way more collisions than expected).
Conclusions
General cross-platform use: CityHash64 on a 64 bit system; xxHash32 on a 32 bit system.
- Good performance across various data sizes.
- Identical hash results across various little-endian platforms and compilers.
- No weird compilation options to tweak or peformance drops on compilers that it is not tuned for.
Best throughput on large data: depends on platform!
- Intel CPU: xxHash64 in general, FarmHash64 if you can use SSE4.2, xxHash32 if compiling for 32 bit.
- Apple mobile CPU (A9): FarmHash64 for 64 bit, xxHash32 for 32 bit.
- Console (XboxOne, AMD Jaguar): SpookyV2.
- asm.js: xxHash32.
Best for short strings: FNV-1a.
- Super simple to implement, inline-able.
- Where exactly it becomes “generally fastest” depends on a platform; around 8 bytes or less on PC, mobile and console; around 20 bytes or less on asm.js.
- If your data is fixed size (e.g. one or two integers), look into specialized hashes instead (see above).