Compact Normal Storage for small G-Buffers (Old and Wrong)
Stop! It's an error!
This version of my article has some stupidity: encoding shaders do not normalize the incoming per-vertex normal. This makes quality evaluation results being somewhat wrong. Also, if normal is assumed to be normalized, then three methods in this article (Sphere Map, Cry Engine 3 and Lambert Azimuthal) are in fact completely equivalent. You'd better just read the new & improved version of this article, trust me!
The old and wrong version follows, in case you really want to see it...
- Intro
- Baseline: store X&Y&Z
- Method 1: X&Y
- Method 2: X&Y&sign of Z
- Method 3: Spherical Coordinates
- Method 3a: Spherical Coordinates w/ texture LUT
- Method 4: Spheremap Transform
- Method 5: Cry Engine 3
- Method 6: Lambert Azimuthal Equal-Area projection
- Method 7: Stereographic projection
- Performance Comparison
- Quality Comparison
- Changelog
- TODO
Intro
Various deferred rendering or deferred lighting approaches need to store normals as part of their g-buffer. Let's figure out a compact storage method for view space normals. In my case, main target is minimalist g-buffer, where depth and normals are packed into a single 32 bit (8 bits/channel) render texture. I try to minimize error and shader cycles to encode/decode.
Now of course, 8 bits/channel storage for normals is usually not enough for deferred rendering/shading, if you want specular (low precision & quantization leads to specular "wobble" when camera or objects move). However, everything below should Just Work (tm) for 10 or 16 bits/channel integer formats. For 16 bits/channel half-float formats, some of the computations are not necessary (e.g. bringing normal values into 0..1 range).
If you know other ways to store/encode normals, please let me know in the comments!
Here's a small test scene. Note that the outer walls have view space normals that point away from
the camera. The same scenario happens on the edges of the spheres. Click for larger version:

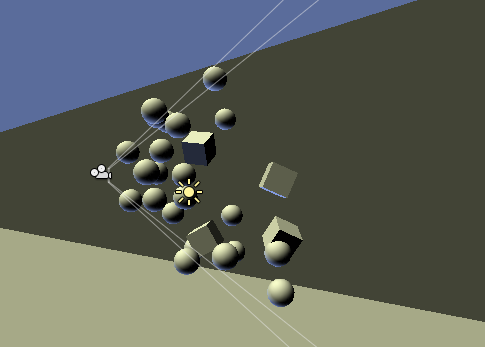
Various normal encoding methods and their comparison below. Notes:
- Error images are: 1-pow(dot(n1,n2)32), abs(n1-n2) and abs(n1-n2)*10, where n1 is actual normal, and n2 is normal encoded into a texture, read back & decoded. MSE and PSNR is computed on the difference (abs(n1-n2)) image.
- Shader code is HLSL. Compiled into ps_2_0 and ps_3_0 by d3dx9_40.dll (November 2008 SDK).
- Radeon GPU performance numbers from AMD's GPU ShaderAnalyzer 1.51, using Catalyst 9.4 driver.
- GeForce GPU performance numbers from NVIDIA's NVShaderPerf 2.0, using 174.74 driver.
Baseline: store X&Y&Z
Just to set the basis, store all three components of the normal. It's not suitable for our quest, but I include it here to evaluate "base" encoding error (which here happens only because of quantization to 8 bits per component).
Encoding, Error to power, Error*1, Error*10 images below. MSE: 0.0000054; PSNR: 52.661 dB.




Method #1: store X&Y, reconstruct Z
Used by Killzone 2 among others (PDF link).
Encoding, Error to power, Error*1, Error*10 images below. MSE: 0.0312331; PSNR: 15.054 dB.




Pros:
|
Cons:
|
| Encoding | Decoding |
|---|---|
enc = n.xy * 0.5 + 0.5; |
n.xy = enc*2-1; n.z = sqrt(1-dot(n.xy,n.xy)); |
ps_2_0 def c0, 0.5, 0, 0, 1 dcl t0.xy mad_pp r0.xy, t0, c0.x, c0.x mov_pp r0.zw, c0 mov_pp oC0, r0 |
ps_2_0 def c0, 2, -1, 1, 0 dcl t0.xyz dcl_2d s0 mov r0.xyz, t0 mov r0.w, t0.z texldp r0, r0, s0 mad_pp r0.xy, r0, c0.x, c0.y dp2add r1.w, r0, -r0, c0.z rsq r1.x, r1.w rcp_pp r0.z, r1.x mov r0.w, c0.z mov_pp oC0, r0 |
3 ALU Radeon 9700: 1 GPR, 2 clk, 4.00 pix/clk Radeon X1600 and up: 1 GPR, 1 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 1 clk, 6400 mpix/s GeForce 7800GT: 1 GPR, 1 clk, 9600 mpix/s GeForce 8800GTX: 5 GPR, 7 clk, 14394 mpix/s |
8 ALU, 1 TEX Radeon 9700: 1 GPR, 4.00 clk, 2.00 pix/clk Radeon X1900: 1 GPR, 2.67 clk, 6.00 pix/clk Radeon HD 2900,3870: 2 GPR, 1.50 clk, 10.67 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 4 clk, 1600 mpix/s GeForce 7800GT: 1 GPR, 3 clk, 3200 mpix/s GeForce 8800GTX: 5 GPR, 20 clk, 8384 mpix/s |
ps_3_0 def c0, 0.5, 0, 1, 0 dcl_texcoord v0.xy mad_pp oC0, v0.xyxx, c0.xxyy, c0.xxyz |
ps_3_0 def c0, 2, -1, 1, 0 dcl_texcoord v0.xyz dcl_2d s0 texldp r0, v0.xyzz, s0 mad_pp r0.xy, r0, c0.x, c0.y dp2add r0.z, r0, -r0, c0.z mov_pp oC0.xy, r0 rsq r0.x, r0.z rcp_pp oC0.z, r0.x mov_pp oC0.w, c0.z |
1 ALU Radeon 9700: -- Radeon X1600 and up: 1 GPR, 1 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 1 clk, 6400 mpix/s GeForce 7800GT: 1 GPR, 1 clk, 9600 mpix/s GeForce 8800GTX: 5 GPR, 7 clk, 14394 mpix/s |
6 ALU, 1 TEX Radeon 9700: -- Radeon X1900: 1 GPR, 2.67 clk, 6.00 pix/clk Radeon HD 2900,3870: 2 GPR, 1.50 clk, 10.67 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 4 clk, 1600 mpix/s GeForce 7800GT: 1 GPR, 3 clk, 3200 mpix/s GeForce 8800GTX: 5 GPR, 15 clk, 11075 mpix/s |
Method #2: store X&Y&sign of Z, reconstruct Z
Basically, method #1 with proper support for negative view space Z component. See gamedev.net forum thread for details.
Pros:
|
Cons:
|
TODO!
Method #3: Spherical Coordinates
It is possible to use spherical coordinates to encode the normal. Since we know it's unit length, we can just store the two angles.
Suggested by Pat Wilson of Garage Games: GG blog post. Other mentions: MJP's blog, GarageGames thread, Wolf Engel's blog, gamedev.net forum thread.
Encoding, Error to power, Error*1, Error*10 images below. MSE: 0.0000945; PSNR: 40.244 dB.




Pros:
|
Cons:
|
| Encoding | Decoding |
|---|---|
// kPI = 3.1415926536f enc = (float2(atan2(n.y,n.x)/kPI, n.z)+1.0)*0.5; |
// kPI = 3.1415926536f float2 ang = enc*2-1; float2 scth; sincos(ang.x * kPI, scth.x, scth.y); float2 scphi = float2(sqrt(1.0 - ang.y*ang.y), ang.y); n = float3(scth.y*scphi.x, scth.x*scphi.x, scphi.y); |
ps_2_0
def c0, 0.0208350997, -0.0851330012,
0.180141002, -0.330299497
def c1, 0.999866009, 0, 1, 3.14159274
def c2, -2, 1.57079637, 0.318309873, 0.5
def c3, 0, 0, 0, 1
dcl t0.xyz
abs r0.w, t0.y
abs r0.x, t0.x
max r1.w, r0.w, r0.x
rcp r0.y, r1.w
min r1.x, r0.x, r0.w
add r0.x, -r0.w, r0.x
cmp r0.x, r0.x, c1.y, c1.z
mul r0.y, r0.y, r1.x
mul r0.z, r0.y, r0.y
mad r0.w, r0.z, c0.x, c0.y
mad r0.w, r0.z, r0.w, c0.z
mad r0.w, r0.z, r0.w, c0.w
mad r0.z, r0.z, r0.w, c1.x
mul r0.y, r0.y, r0.z
mad r0.z, r0.y, c2.x, c2.y
mad r0.x, r0.z, r0.x, r0.y
cmp r0.y, t0.x, -c1.y, -c1.w
add r0.x, r0.x, r0.y
add r0.y, r0.x, r0.x
min r0.z, t0.x, t0.y
cmp r0.z, r0.z, c1.y, c1.z
max r0.w, t0.y, t0.x
cmp r0.w, r0.w, c1.z, c1.y
mul r0.z, r0.z, r0.w
mad r0.x, r0.z, -r0.y, r0.x
mul r0.x, r0.x, c2.z
mov r0.y, t0.z
add r0.xy, r0, c1.z
mul_pp r0.xy, r0, c2.w
mov_pp r0.zw, c3
mov_pp oC0, r0
|
ps_2_0
def c0, 2, -1, 0.5, 1
def c1, 6.28318548, -3.14159274, 0, 0
def c2, -1.55009923e-006, -2.17013894e-005,
0.00260416674, 0.00026041668
def c3, -0.020833334, -0.125, 1, 0.5
dcl t0.xyz
dcl_2d s0
mov r0.xyz, t0
mov r0.w, t0.z
texldp r0, r0, s0
mad r0.xy, r0, c0.x, c0.y
mad r0.x, r0.x, c0.z, c0.z
frc r0.x, r0.x
mad r0.x, r0.x, c1.x, c1.y
sincos r1.xy, r0.x, c2, c3
mad r0.x, r0.y, -r0.y, c0.w
mov_pp r2.z, r0.y
rsq r0.x, r0.x
rcp r0.x, r0.x
mul_pp r2.xy, r1, r0.x
mov_pp r2.w, c0.w
mov_pp oC0, r2
|
31 ALU Radeon 9700: 3 GPR, 15 clk, 0.53 pix/clk Radeon X1900: 3 GPR, 5.67 clk, 2.82 pix/clk Radeon HD 2900,3870: 1 GPR, 4.00 clk, 4.00 pix/clk Radeon HD 4870: 1 GPR, 1.60 clk, 10.00 pix/clk GeForce 6800U: 2 GPR, 12 clk, 533 mpix/s GeForce 7800GT: 3 GPR, 9 clk, 1066 mpix/s GeForce 8800GTX: 9 GPR, 36 clk, 5760 mpix/s |
14 ALU, 1 TEX Radeon 9700: 2 GPR, 12.00 clk, 0.67 pix/clk Radeon X1900: 2 GPR, 3.00 clk, 5.33 pix/clk Radeon HD 2900,3870: 2 GPR, 2.25 clk, 7.11 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 7 clk, 914 mpix/s GeForce 7800GT: 2 GPR, 5 clk, 1920 mpix/s GeForce 8800GTX: 6 GPR, 28 clk, 5903 mpix/s |
ps_3_0
def c0, 0.0208350997, -0.0851330012,
0.180141002, -0.330299497
def c1, 0.999866009, 0, 1, 3.14159274
def c2, -2, 1.57079637, 0.318309873, 0.5
dcl_texcoord v0.xyz
add r0.xy, -v0_abs, v0_abs.yxzw
cmp r0.xz, r0.x, v0_abs.xyyw, v0_abs.yyxw
cmp r0.y, r0.y, c1.y, c1.z
rcp r0.z, r0.z
mul r0.x, r0.x, r0.z
mul r0.z, r0.x, r0.x
mad r0.w, r0.z, c0.x, c0.y
mad r0.w, r0.z, r0.w, c0.z
mad r0.w, r0.z, r0.w, c0.w
mad r0.z, r0.z, r0.w, c1.x
mul r0.x, r0.x, r0.z
mad r0.z, r0.x, c2.x, c2.y
mad r0.x, r0.z, r0.y, r0.x
cmp r0.y, v0.x, -c1.y, -c1.w
add r0.x, r0.x, r0.y
add r0.y, r0.x, r0.x
add r0.z, -v0.x, v0.y
cmp r0.zw, r0.z, v0.xyxy, v0.xyyx
cmp r0.zw, r0, c1.xyyz, c1.xyzy
mul r0.z, r0.w, r0.z
mad r0.x, r0.z, -r0.y, r0.x
mul r0.x, r0.x, c2.z
mov r0.y, v0.z
add r0.xy, r0, c1.z
mul_pp oC0.xy, r0, c2.w
mov_pp oC0.zw, c1.xyyz
|
ps_3_0 def c0, 2, -1, 0.5, 1 def c1, 6.28318548, -3.14159274, 1, 0 dcl_texcoord v0.xyz dcl_2d s0 texldp r0, v0.xyzz, s0 mad r0.xy, r0, c0.x, c0.y mad r0.x, r0.x, c0.z, c0.z frc r0.x, r0.x mad r0.x, r0.x, c1.x, c1.y sincos r1.xy, r0.x mad r0.x, r0.y, -r0.y, c0.w mad_pp oC0.zw, r0.y, c1, c1.xywz rsq r0.x, r0.x rcp r0.x, r0.x mul_pp oC0.xy, r1, r0.x |
26 ALU Radeon 9700: -- Radeon X1900: 4 GPR, 6.00 clk, 2.67 pix/clk Radeon HD 2900,3870: 1 GPR, 4.25 clk, 3.76 pix/clk Radeon HD 4870: 1 GPR, 1.70 clk, 9.41 pix/clk GeForce 6800U: 3 GPR, 12 clk, 533 mpix/s GeForce 7800GT: 3 GPR, 10 clk, 960 mpix/s GeForce 8800GTX: 9 GPR, 43 clk, 5146 mpix/s |
10 ALU, 1 TEX Radeon 9700: -- Radeon X1900: 2 GPR, 3.00 clk, 5.33 pix/clk Radeon HD 2900,3870: 2 GPR, 2.25 clk, 7.11 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 7 clk, 914 mpix/s GeForce 7800GT: 2 GPR, 5 clk, 1920 mpix/s GeForce 8800GTX: 6 GPR, 23 clk, 7119 mpix/s |
Method #3a: Spherical Coordinates w/ texture LUT
Method #3, ALU operations replaced with texture lookups.
Encoding, Error to power, Error*1, Error*10 images below. MSE: 0.0002237; PSNR: 36.503 dB.




Pros:
|
Cons:
|
| Encoding | Decoding |
|---|---|
float3 in01 = n*0.5+0.5; enc.x = tex2D(_Atan2Lookup, in01.xy).a; enc.y = in01.z; |
half3 sclook = tex2D(_SinCosLookup, enc).rgb; n = sclook*2-1; |
ps_2_0 def c0, 0.5, 0, 0, 1 dcl t0.xyz dcl_2d s0 mad r0.xy, t0, c0.x, c0.x texld_pp r0, r0, s0 mov_pp r0.x, r0.w mad_pp r0.y, t0.z, c0.x, c0.x mov_pp r0.zw, c0 mov_pp oC0, r0 |
ps_2_0 def c0, 2, -1, 1, 0 dcl t0.xyz dcl_2d s0 dcl_2d s1 mov r0.xyz, t0 mov r0.w, t0.z texldp r0, r0, s0 texld_pp r0, r0, s1 mad_pp r0.xyz, r0, c0.x, c0.y mov_pp r0.w, c0.z mov_pp oC0, r0 |
5 ALU, 1 TEX Radeon 9700: 2 GPR, 4.00 clk, 2.00 pix/clk Radeon X1900: 1 GPR, 3.33 clk, 4.80 pix/clk Radeon HD 2900,3870: 2 GPR, 1.00 clk, 16.00 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 3.00 clk, 2133 mpix/s GeForce 7800GT: 1 GPR, 3.00 clk, 3200 mpix/s GeForce 8800GTX: 7 GPR, 10.00 clk, 14241 mpix/s |
5 ALU, 2 TEX Radeon 9700: 1 GPR, 2.00 clk, 4.00 pix/clk Radeon X1900: 1 GPR, 2.00 clk, 8.00 pix/clk Radeon HD 2900,3870: 2 GPR, 2.00 clk, 8.00 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 2.00 clk, 3200 mpix/s GeForce 7800GT: 1 GPR, 2.00 clk, 4800 mpix/s GeForce 8800GTX: 6 GPR, 20.00 clk, 8689 mpix/s |
ps_3_0 def c0, 0.5, 1, 0, 0 dcl_texcoord v0.xyz dcl_2d s0 mad r0.xy, v0, c0.x, c0.x texld_pp r0, r0, s0 mad_pp oC0.xzw, r0.w, c0.yyzz, c0.zyzy mad_pp oC0.y, v0.z, c0.x, c0.x |
ps_3_0 def c0, 2, -1, 1, 0 dcl_texcoord v0.xyz dcl_2d s0 dcl_2d s1 texldp r0, v0.xyzz, s0 texld_pp r0, r0, s1 mad_pp oC0.xyz, r0, c0.x, c0.y mov_pp oC0.w, c0.z |
3 ALU, 1 TEX Radeon 9700: -- Radeon X1900: 1GPR, 2.33 clk, 6.86 pix/clk Radeon HD 2900,3870: 2 GPR, 1.00 clk, 16.00 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 3.00 clk, 2133 mpix/s GeForce 7800GT: 2 GPR, 3.00 clk, 3200 mpix/s GeForce 8800GTX: 7 GPR, 10.00 clk, 14241 mpix/s |
2 ALU, 2 TEX Radeon 9700: -- Radeon X1900: 1 GPR, 2.00 clk, 8.00 pix/clk Radeon HD 2900,3870: 2 GPR, 2.00 clk, 8.00 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 2.00 clk, 3200 mpix/s GeForce 7800GT: 1 GPR, 2.00 clk, 4800 mpix/s GeForce 8800GTX: 6 GPR, 20.00 clk, 8689 mpix/s |
// UnityScript code to create _Atan2Lookup
var size = 256;
tex = new Texture2D(size,size,
TextureFormat.Alpha8,false);
var pix = new Color[size*size];
var idx = 0;
var sizeF : float = size;
for (var y = 0; y < size; ++y)
{
for (var x = 0; x < size; ++x)
{
var xval = x/sizeF * 2.0 - 1.0;
var yval = y/sizeF * 2.0 - 1.0;
var atanRes = (Math.Atan2(yval, xval) + Mathf.PI) /
(Mathf.PI*2);
pix[idx] = new Color(0,0,0,atanRes+0.5/255.0);
++idx;
}
}
tex.SetPixels (pix,0);
tex.Apply();
tex.wrapMode = TextureWrapMode.Clamp;
tex.filterMode = FilterMode.Point;
Shader.SetGlobalTexture ("_Atan2Lookup", tex);
|
// UnityScript code to create _SinCosLookup
var tex = new Texture2D(size,size,
TextureFormat.ARGB32,false);
var pix = new Color[size*size];
var idx = 0;
var sizeF : float = size;
for (y = 0; y < size; ++y)
{
var angY : float = y/sizeF * 2.0 - 1.0;
var scphi = Mathf.Sqrt(1.0-angY*angY);
for (x = 0; x < size; ++x)
{
var ang : float = x/sizeF * 2.0 - 1.0;
ang *= Mathf.PI;
var vs = Mathf.Sin(ang);
var vc = Mathf.Cos(ang);
pix[idx] = new Color(
vc*scphi*0.5+0.5+0.5/255.0,
vs*scphi*0.5+0.5+0.5/255.0,
angY*0.5+0.5+0.5/255.0,
1
);
++idx;
}
}
tex.SetPixels (pix,0);
tex.Apply();
tex.wrapMode = TextureWrapMode.Clamp;
tex.filterMode = FilterMode.Point;
Shader.SetGlobalTexture ("_SinCosLookup", tex);
|
Method #4: Spheremap Transform
Spherical environment mapping (indirectly) maps reflection vector to a texture coordinate in [0..1] range. The reflection vector can point away from the camera, just like our view space normals. Bingo! See Siggraph 99 notes for sphere map math. Normal we want to encode is R, resulting values are (s,t).
I'm not aware of any uses of this method. If someone has used it to store normals, please let me know (mail or comment on my blog post).
Encoding, Error to power, Error*1, Error*10 images below. MSE: 0.0000333; PSNR: 44.781 dB.




Pros:
|
Cons:
|
| Encoding | Decoding |
|---|---|
float f = n.z*2+1; float g = dot(n,n); float p = sqrt(g+f); enc = n/p * 0.5 + 0.5; |
float2 tmp = -enc*enc+enc; float f = tmp.x+tmp.y; float m = sqrt(4*f-1); n.xy = (enc*4-2) * m; n.z = 8*f-3; // optimized n.xy = -enc*enc+enc; n.z = -1; float f = dot(n, float3(1,1,0.25)); float m = sqrt(f); n.xy = (enc*8-4) * m; n.z += 8*f; |
ps_2_0 def c0, 2, 1, 0.5, 0 def c1, 0, 1, 0, 0 dcl t0.xyz mad r0.w, t0.z, c0.x, c0.y dp3 r0.x, t0, t0 add r0.x, r0.w, r0.x rsq r0.x, r0.x mul r0.xy, r0.x, t0 mad_pp r0.xy, r0, c0.z, c0.z mov_pp r0.z, c1.x mov_pp r0.w, c1.y mov_pp oC0, r0 |
ps_2_0 def c0, -1, 0.25, 1, 1 def c1, 8, -4, -1, 0 dcl t0.xyz dcl_2d s0 mov r0.xyz, t0 mov r0.w, t0.z texldp r0, r0, s0 mad r1.xy, -r0, r0, r0 mad r0.xy, r0, c1.x, c1.y mov r1.z, c0.x dp3 r0.z, r1, c0.wzyx rsq r0.w, r0.z mad_pp r1.z, r0.z, c1.x, c1.z rcp r0.z, r0.w mul_pp r1.xy, r0, r0.z mov r1.w, c0.w mov_pp oC0, r1 |
9 ALU Radeon 9700: 2 GPR, 4.00 clk, 2.00 pix/clk Radeon X1900: 3 GPR, 2.33 clk, 6.86 pix/clk Radeon HD 2900,3870: 2 GPR, 1.50 clk, 10.67 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 6 clk, 1066 mpix/s GeForce 7800GT: 1 GPR, 3 clk, 3200 mpix/s GeForce 8800GTX: 6 GPR, 13 clk, 11712 mpix/s |
12 ALU, 1 TEX Radeon 9700: 2 GPR, 6.00 clk, 1.33 pix/clk Radeon X1900: 2 GPR, 3.00 clk, 5.33 pix/clk Radeon HD 2900,3870: 3 GPR, 1.75 clk, 9.14 pix/clk Radeon HD 4870: 3 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 6 clk, 1066 mpix/s GeForce 7800GT: 1 GPR, 3 clk, 3200 mpix/s GeForce 8800GTX: 7 GPR, 20 clk, 8320 mpix/s |
ps_3_0 def c0, 2, 1, 0.5, 0 dcl_texcoord v0.xyz mad r0.x, v0.z, c0.x, c0.y dp3 r0.y, v0, v0 add r0.x, r0.x, r0.y rsq r0.x, r0.x mul r0.xy, r0.x, v0 mad_pp oC0.xy, r0, c0.z, c0.z mov_pp oC0.zw, c0.xywy |
ps_3_0 def c0, -1, 1, 0.25, 8 def c1, 8, -4, 0, 0 dcl_texcoord v0.xyz dcl_2d s0 mov r0.z, c0.x texldp r1, v0.xyzz, s0 mad r0.xy, -r1, r1, r1 mad r1.xy, r1, c1.x, c1.y dp3 r0.x, r0, c0.yyzw rsq r0.y, r0.x mad_pp oC0.z, r0.x, c0.w, c0.x rcp r0.x, r0.y mul_pp oC0.xy, r1, r0.x mov_pp oC0.w, c0.y |
7 ALU Radeon 9700: -- Radeon X1900: 3 GPR, 2.33 clk, 6.86 pix/clk Radeon HD 2900,3870: 2 GPR, 1.50 clk, 10.67 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 6 clk, 1066 mpix/s GeForce 7800GT: 1 GPR, 3 clk, 3200 mpix/s GeForce 8800GTX: 6 GPR, 13 clk, 11712 mpix/s |
8 ALU, 1 TEX Radeon 9700: -- Radeon X1900: 2 GPR, 3.00 clk, 5.33 pix/clk Radeon HD 2900,3870: 3 GPR, 1.75 clk, 9.14 pix/clk Radeon HD 4870: 3 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 6 clk, 1066 mpix/s GeForce 7800GT: 1 GPR, 3 clk, 3200 mpix/s GeForce 8800GTX: 7 GPR, 15 clk, 10777 mpix/s |
Method #5: Cry Engine 3
Somewhat similar to Method #4 (sphere map). Used in Cry Engine 3, presented by Martin Mittring in "A bit more Deferred" presentation (PPT link, slide 13). For Unity, I had to negate Z component of view space normal to produce good results, I guess Unity's and Cry Engine's coordinate systems are different.
Encoding, Error to power, Error*1, Error*10 images below. MSE: 0.0000921; PSNR: 40.355 dB.




Pros:
|
Cons:
|
| Encoding | Decoding |
|---|---|
enc = normalize(n.xy) * (sqrt(-n.z*0.5+0.5)); enc = enc*0.5+0.5; |
float2 fenc = enc*2-1; n.z = -(dot(fenc,fenc)*2-1); n.xy = normalize(fenc) * sqrt(1-n.z*n.z);
// optimized
// enc4 is float4, with .rg containing encoded normal
float4 nn =
enc4*float4(2,2,0,0) +
float4(-1,-1,1,-1);
float l = dot(nn.xyz,-nn.xyw);
nn.z = l;
nn.xy *= sqrt(l);
n = nn.xyz * 2 + float3(0,0,-1);
|
ps_2_0 def c0, 0, -0.5, 0.5, 0 def c1, 0, 1, 0, 0 dcl t0.xyz dp2add r0.w, t0, t0, c0.x rsq r0.x, r0.w mul r0.xy, r0.x, t0 mad r0.z, t0.z, c0.y, c0.z rsq r0.z, r0.z rcp r0.z, r0.z mul r0.xy, r0, r0.z mad_pp r0.xy, r0, c0.z, c0.z mov_pp r0.z, c1.x mov_pp r0.w, c1.y mov_pp oC0, r0 |
ps_2_0 def c0, 2, 2, 0, 0 def c1, -1, -1, 1, -1 def c2, 0, 0, -1, 2 dcl t0.xyz dcl_2d s0 mov r0.xyz, t0 mov r0.w, t0.z texldp r0, r0, s0 mov r1, c1 mad r0, r0, c0, r1 mul r1.x, -r0.x, r0.x mad r1.x, r0.y, -r0.y, r1.x mad r1.z, r0.z, -r0.w, r1.x rsq r1.w, r1.z rcp r1.w, r1.w mul r1.xy, r0, r1.w mad_pp r0.xyz, r1, c2.w, c2 mov r0.w, c1.z mov_pp oC0, r0 |
11 ALU Radeon 9700: 2 GPR, 5.00 clk, 1.60 pix/clk Radeon X1900: 2 GPR, 2.33 clk, 6.86 pix/clk Radeon HD 2900,3870: 2 GPR, 1.50 clk, 10.67 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 6.00 clk, 1067 mpix/s GeForce 7800GT: 2 GPR, 3.00 clk, 3200 mpix/s GeForce 8800GTX: 6 GPR, 20.00 clk, 8246 mpix/s |
13 ALU, 1 TEX Radeon 9700: 2 GPR, 7.00 clk, 1.14 pix/clk Radeon X1900: 2 GPR, 2.67 clk, 6.00 pix/clk Radeon HD 2900,3870: 2 GPR, 2.25 clk, 7.11 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 6.00 clk, 1066 mpix/s GeForce 7800GT: 2 GPR, 5.00 clk, 1920 mpix/s GeForce 8800GTX: 6 GPR, 20.00 clk, 8128 mpix/s |
ps_3_0 def c0, 0, -0.5, 0.5, 1 dcl_texcoord v0.xyz dp2add r0.x, v0, v0, c0.x rsq r0.x, r0.x mul r0.xy, r0.x, v0 mad r0.z, v0.z, c0.y, c0.z rsq r0.z, r0.z rcp r0.z, r0.z mul r0.xy, r0, r0.z mad_pp oC0.xy, r0, c0.z, c0.z mov_pp oC0.zw, c0.xyxw |
ps_3_0 def c0, 2, 0, -1, 1 dcl_texcoord v0.xyz dcl_2d s0 texldp r0, v0.xyzz, s0 mad r0, r0, c0.xxyy, c0.zzwz dp3 r1.z, r0, -r0.xyww rsq r0.z, r1.z rcp r0.z, r0.z mul r1.xy, r0, r0.z mad_pp oC0.xyz, r1, c0.x, c0.yyzw mov_pp oC0.w, c0.w |
9 ALU Radeon 9700: -- Radeon X1900: 2 GPR, 2.33 clk, 6.86 pix/clk Radeon HD 2900,3870: 2 GPR, 1.50 clk, 10.67 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 6.00 clk, 1067 mpix/s GeForce 7800GT: 2 GPR, 3.00 clk, 3200 mpix/s GeForce 8800GTX: 6 GPR, 20.00 clk, 8246 mpix/s |
7 ALU, 1 TEX Radeon 9700: -- Radeon X1900: 2 GPR, 2.67 clk, 6.00 pix/clk Radeon HD 2900,3870: 3 GPR, 2.00 clk, 8.00 pix/clk Radeon HD 4870: 3 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 5.00 clk, 1280 mpix/s GeForce 7800GT: 2 GPR, 4.00 clk, 2400 mpix/s GeForce 8800GTX: 6 GPR, 15.00 clk, 10501 mpix/s |
Method #6: Lambert Azimuthal Equal-Area Projection
What the title says: use Lambert Azimuthal Equal-Area projection (Wikipedia link). Suggested by Sean Barrett in comments for this article.
Encoding, Error to power, Error*1, Error*10 images below. MSE: 0.0000495; PSNR: 43.054 dB.




Pros:
|
Cons:
|
| Encoding | Decoding |
|---|---|
float f = sqrt(8*n.z+8); enc = n.xy / f + 0.5; |
float2 fenc = enc*4-2; float f = dot(fenc,fenc); float g = sqrt(1-f/4); n.xy = fenc*g; n.z = 1-f/2; |
ps_2_0 def c0, 8, 0.5, 1, 0 dcl t0.xyz mad r0.w, t0.z, c0.x, c0.x rsq r0.x, r0.w mad_pp r0.xy, t0, r0.x, c0.y mov_pp r0.z, c0.w mov_pp r0.w, c0.z mov_pp oC0, r0 |
ps_2_0 def c0, 4, -2, 0, 1 def c1, 0.25, 1, 0.5, 0 dcl t0.xyz dcl_2d s0 mov r0.xyz, t0 mov r0.w, t0.z texldp r0, r0, s0 mad r0.xy, r0, c0.x, c0.y dp2add r0.z, r0, r0, c0.z mad r0.w, r0.z, -c1.x, c1.y mad_pp r1.z, r0.z, -c1.z, c1.y rsq r0.z, r0.w rcp r0.z, r0.z mul_pp r1.xy, r0, r0.z mov_pp r1.w, c0.w mov_pp oC0, r1 |
6 ALU Radeon 9700: 1 GPR, 3.00 clk, 2.67 pix/clk Radeon X1900: 1 GPR, 1.67 clk, 9.60 pix/clk Radeon HD 2900,3870: 2 GPR, 1.00 clk, 16.00 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 4.00 clk, 1600 mpix/s GeForce 7800GT: 1 GPR, 2.00 clk, 4800 mpix/s GeForce 8800GTX: 5 GPR, 12.00 clk, 13724 mpix/s |
11 ALU, 1 TEX Radeon 9700: 1 GPR, 7.00 clk, 1.14 pix/clk Radeon X1900: 1 GPR, 3.33 clk, 4.80 pix/clk Radeon HD 2900,3870: 2 GPR, 2.00 clk, 8.00 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 6.00 clk, 1067 mpix/s GeForce 7800GT: 1 GPR, 3.00 clk, 3200 mpix/s GeForce 8800GTX: 6 GPR, 20.00 clk, 8282 mpix/s |
ps_3_0 def c0, 8, 0.5, 0, 1 dcl_texcoord v0.xyz mad r0.x, v0.z, c0.x, c0.x rsq r0.x, r0.x mad_pp oC0.xy, v0, r0.x, c0.y mov_pp oC0.zw, c0 |
ps_3_0 def c0, 4, -2, 0, 1 def c1, 0.25, 0.5, 1, 0 dcl_texcoord v0.xyz dcl_2d s0 texldp r0, v0.xyzz, s0 mad r0.xy, r0, c0.x, c0.y dp2add r0.z, r0, r0, c0.z mad r0.zw, r0.z, -c1.xyxy, c1.z rsq r0.z, r0.z mad_pp oC0.zw, r0.w, c0.xywz, c0 rcp r0.z, r0.z mul_pp oC0.xy, r0, r0.z |
4 ALU Radeon 9700: -- Radeon X1900: 1 GPR, 1.67 clk, 9.60 pix/clk Radeon HD 2900,3870: 2 GPR, 1.00 clk, 16.00 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 4.00 clk, 1600 mpix/s GeForce 7800GT: 1 GPR, 2.00 clk, 4800 mpix/s GeForce 8800GTX: 5 GPR, 12.00 clk, 13724 mpix/s |
7 ALU, 1 TEX Radeon 9700: -- Radeon X1900: 1 GPR, 3.33 clk, 4.80 pix/clk Radeon HD 2900,3870: 2 GPR, 2.00 clk, 8.00 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 6.00 clk, 1067 mpix/s GeForce 7800GT: 1 GPR, 3.00 clk, 3200 mpix/s GeForce 8800GTX: 6 GPR, 15.00 clk, 10952 mpix/s |
Method #7: Stereographic Projection
What the title says: use Stereographic Projection (Wikipedia link), plus rescaling so that "practically visible" range of normals maps into unit circle (regular stereographic projection maps sphere to circle of infinite size). In my tests, scaling factor of 1.7777 produced best results; in practice it depends on FOV used and how much do you care about normals that point away from the camera.
Suggested by Sean Barrett and Ignacio Castano in comments for this article.
Encoding, Error to power, Error*1, Error*10 images below. MSE: 0.0000380; PSNR: 44.207 dB.




Pros:
|
Cons:
|
| Encoding | Decoding |
|---|---|
float scale = 1.7777; enc = n.xy / (n.z+1); enc /= scale; enc = enc*0.5+0.5; |
// enc4 is float4, with .rg containing encoded normal
float scale = 1.7777;
float3 nn =
enc4.xyz*float3(2*scale,2*scale,0) +
float3(-scale,-scale,1);
float g = 2.0 / dot(nn.xyz,nn.xyz);
n.xy = g*nn.xy;
n.z = g-1;
|
ps_2_0 def c0, 1, 0.281262308, 0.5, 0 def c1, 0, 0, 0, 1 dcl t0.xyz add r0.w, t0.z, c0.x rcp r0.x, r0.w mul r0.xy, r0.x, t0 mad_pp r0.xy, r0, c0.y, c0.z mov_pp r0.zw, c1 mov_pp oC0, r0 |
ps_2_0 def c0, 3.55539989, 3.55539989, 0, 1 def c1, -1.77769995, -1.77769995, 1, -2 dcl t0.xyz dcl_2d s0 mov r0.xyz, t0 mov r0.w, t0.z texldp r0, r0, s0 mov r1.xyz, c1 mad r0.xyz, r0, c0, r1 dp3 r0.z, r0, r0 rcp r0.z, r0.z add r0.w, r0.z, r0.z mad_pp r1.z, r0.z, -c1.w, -c1.z mul_pp r1.xy, r0, r0.w mov_pp r1.w, c0.w mov_pp oC0, r1 |
6 ALU Radeon 9700: 1 GPR, 4.00 clk, 2.00 pix/clk Radeon X1900: 1 GPR, 2.00 clk, 8.00 pix/clk Radeon HD 2900,3870: 2 GPR, 1.00 clk, 16.00 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 2.00 clk, 3200 mpix/s GeForce 7800GT: 1 GPR, 2.00 clk, 4800 mpix/s GeForce 8800GTX: 5 GPR, 12.00 clk, 13734 mpix/s |
11 ALU, 1 TEX Radeon 9700: 1 GPR, 6.00 clk, 1.33 pix/clk Radeon X1900: 1 GPR, 3.00 clk, 5.33 pix/clk Radeon HD 2900,3870: 3 GPR, 1.75 clk, 9.14 pix/clk Radeon HD 4870: 3 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 3.00 clk, 2133 mpix/s GeForce 7800GT: 2 GPR, 3.00 clk, 3200 mpix/s GeForce 8800GTX: 6 GPR, 16.00 clk, 9897 mpix/s |
ps_3_0 def c0, 1, 0.281262308, 0.5, 0 dcl_texcoord v0.xyz add r0.x, c0.x, v0.z rcp r0.x, r0.x mul r0.xy, r0.x, v0 mad_pp oC0.xy, r0, c0.y, c0.z mov_pp oC0.zw, c0.xywx |
ps_3_0 def c0, 3.55539989, 0, -1.77769995, 1 def c1, 2, -1, 0, 0 dcl_texcoord v0.xyz dcl_2d s0 texldp r0, v0.xyzz, s0 mad r0.xyz, r0, c0.xxyw, c0.zzww dp3 r0.z, r0, r0 rcp r0.z, r0.z add r0.w, r0.z, r0.z mad_pp oC0.z, r0.z, c1.x, c1.y mul_pp oC0.xy, r0, r0.w mov_pp oC0.w, c0.w |
5 ALU Radeon 9700: -- Radeon X1900: 1 GPR, 2.00 clk, 8.00 pix/clk Radeon HD 2900,3870: 2 GPR, 1.00 clk, 16.00 pix/clk Radeon HD 4870: 2 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 1 GPR, 2.00 clk, 3200 mpix/s GeForce 7800GT: 1 GPR, 2.00 clk, 4800 mpix/s GeForce 8800GTX: 5 GPR, 12.00 clk, 13734 mpix/s |
7 ALU, 1 TEX Radeon 9700: -- Radeon X1900: 1 GPR, 3.00 clk, 5.33 pix/clk Radeon HD 2900,3870: 3 GPR, 1.75 clk, 9.14 pix/clk Radeon HD 4870: 3 GPR, 1.00 clk, 16.00 pix/clk GeForce 6800U: 2 GPR, 3.00 clk, 2133 mpix/s GeForce 7800GT: 2 GPR, 3.00 clk, 3200 mpix/s GeForce 8800GTX: 6 GPR, 12.00 clk, 12493 mpix/s |
Performance Comparison
GPU performance comparison in a single table:
| #1: X & Y | #3: Spherical | #3a: w/ LUT | #4: Spheremap | #5: Cry3 | #6: Lambert | #7: Stereo | |
|---|---|---|---|---|---|---|---|
| Encoding, GPU cycles, SM2.0 | |||||||
| Radeon X1900 | 1.00 | 5.67 | 3.33 | 2.33 | 2.33 | 1.67 | 2.00 |
| Radeon HD3870 | 1.00 | 4.00 | 1.00 | 1.50 | 1.50 | 1.00 | 1.00 |
| GeForce 6800U | 1.00 | 12.00 | 3.00 | 6.00 | 6.00 | 4.00 | 2.00 |
| GeForce 8800GTX | 7.00 | 36.00 | 10.00 | 13.00 | 20.00 | 12.00 | 12.00 |
| Decoding, GPU cycles, SM2.0 | |||||||
| Radeon X1900 | 2.67 | 3.00 | 2.00 | 3.00 | 2.67 | 3.33 | 3.00 |
| Radeon HD3870 | 1.50 | 2.25 | 2.00 | 1.75 | 2.25 | 2.00 | 1.75 |
| GeForce 6800U | 4.00 | 7.00 | 2.00 | 6.00 | 6.00 | 6.00 | 3.00 |
| GeForce 8800GTX | 20.00 | 28.00 | 20.00 | 20.00 | 20.00 | 20.00 | 16.00 |
| Encoding, D3D ALU+TEX instruction slots | |||||||
| SM2.0 | 3 | 31 | 6 | 9 | 11 | 6 | 6 |
| SM3.0 | 1 | 26 | 4 | 7 | 9 | 4 | 5 |
| Decoding, D3D ALU+TEX instruction slots | |||||||
| SM2.0 | 8 | 14 | 6 | 12 | 13 | 11 | 11 |
| SM3.0 | 6 | 10 | 3 | 8 | 7 | 7 | 7 |
Quality Comparison
Quality comparison in a single table. PSNR based, higher numbers are better.
| Method | PSNR, dB |
|---|---|
| #1: X & Y | 15.054 |
| #3: Spherical | 40.244 |
| #3a: w/ LUT | 36.503 |
| #4: Spheremap | 44.781 |
| #5: Cry Engine 3 | 40.355 |
| #6: Lambert | 43.054 |
| #7: Stereographic | 44.207 |
Changelog
- 2010 03 25: Stop! Read the new & improved version of this article!
- 2009 08 12: Added Method #7: Stereographic projection. Suggested by Sean Barrett and Ignacio Castano.
- 2009 08 12: Optimized Method #5, suggested by Steve Hill.
- 2009 08 08: Added power difference images.
- 2009 08 07: Optimized Method #4: Sphere map. Suggested by Irenee Caroulle.
- 2009 08 07: Added Method #6: Lambert Azimuthal Equal Area. Suggested by Sean Barrett.
- 2009 08 05: Added Method #5: Cry Engine 3. Suggested by Steve Hill.
- 2009 08 05: Improved quality of Method #3a: round values in texture LUT.
- 2009 08 05: Added MSE and PSNR values for all methods.
- 2009 08 04: Added Method #3a: Spherical Coordinates w/ texture LUT.
- 2009 08 04: Method #1: 1-dot(n.xy,n.xy) is slightly better than 1-n.x*n.x-n.y*n.y (better pipelining on NV and ATI). Suggested by Arseny "zeux" Kapoulkine.