EXR: libdeflate is great
Previous blog post was about adding Zstandard compression to OpenEXR. I planned to look into something else now, but a github comment from Miloš Komarčević and a blog post from Matt Pharr reminded me to look into libdeflate, which I was not consciously aware of before.
TL;DR: libdeflate is most excellent. If you need to use zlib/deflate compression, look into it!
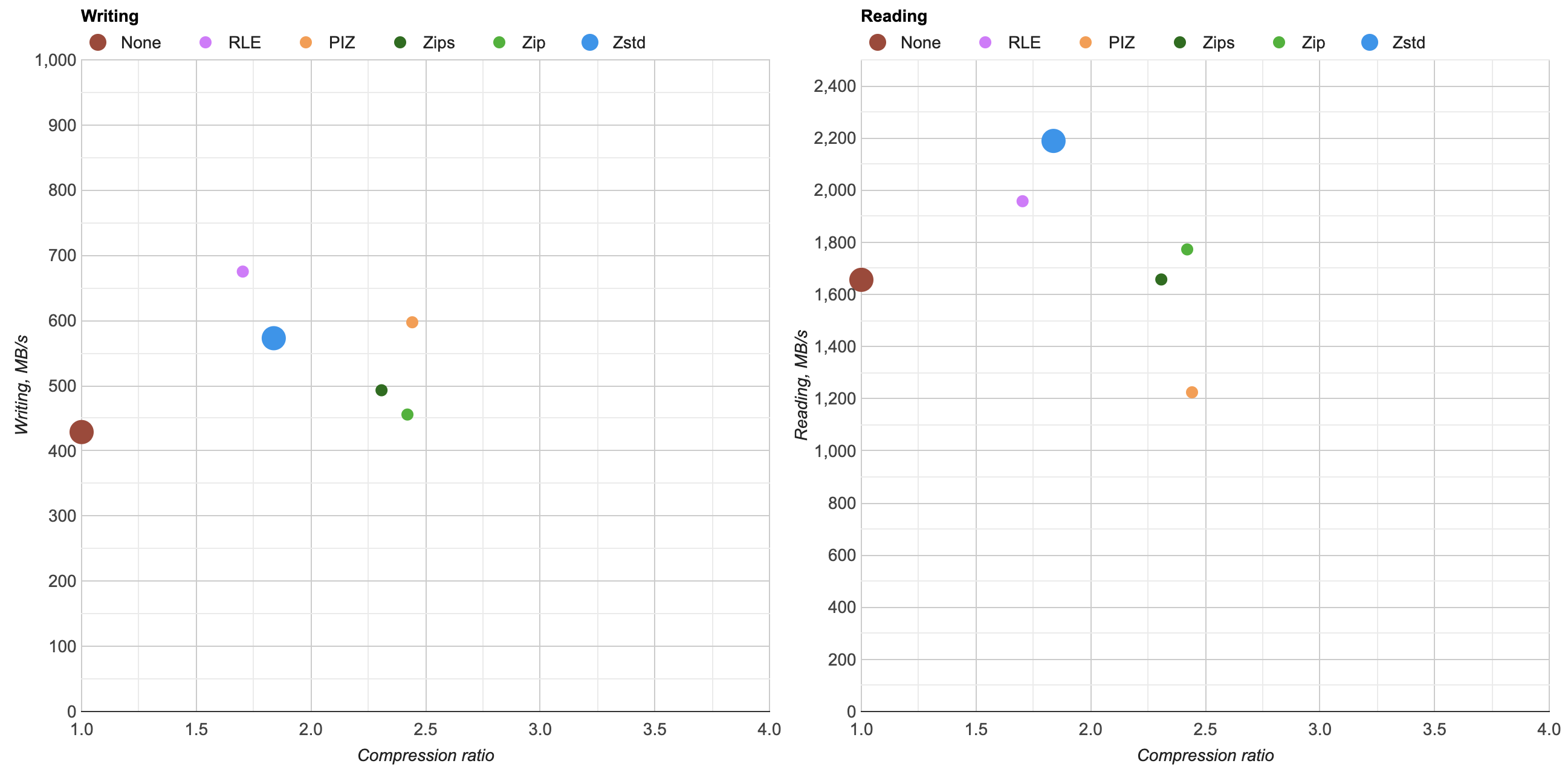
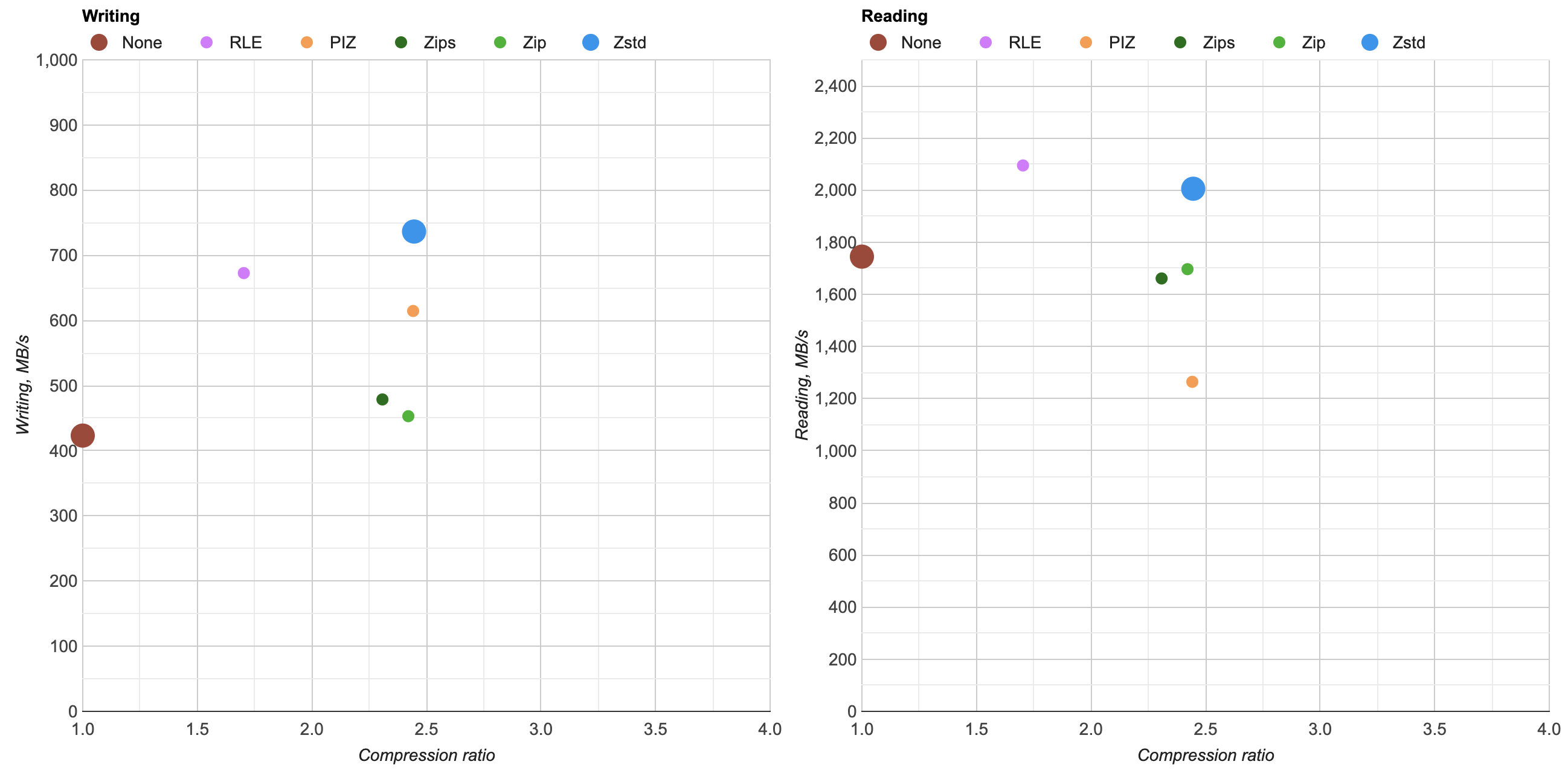
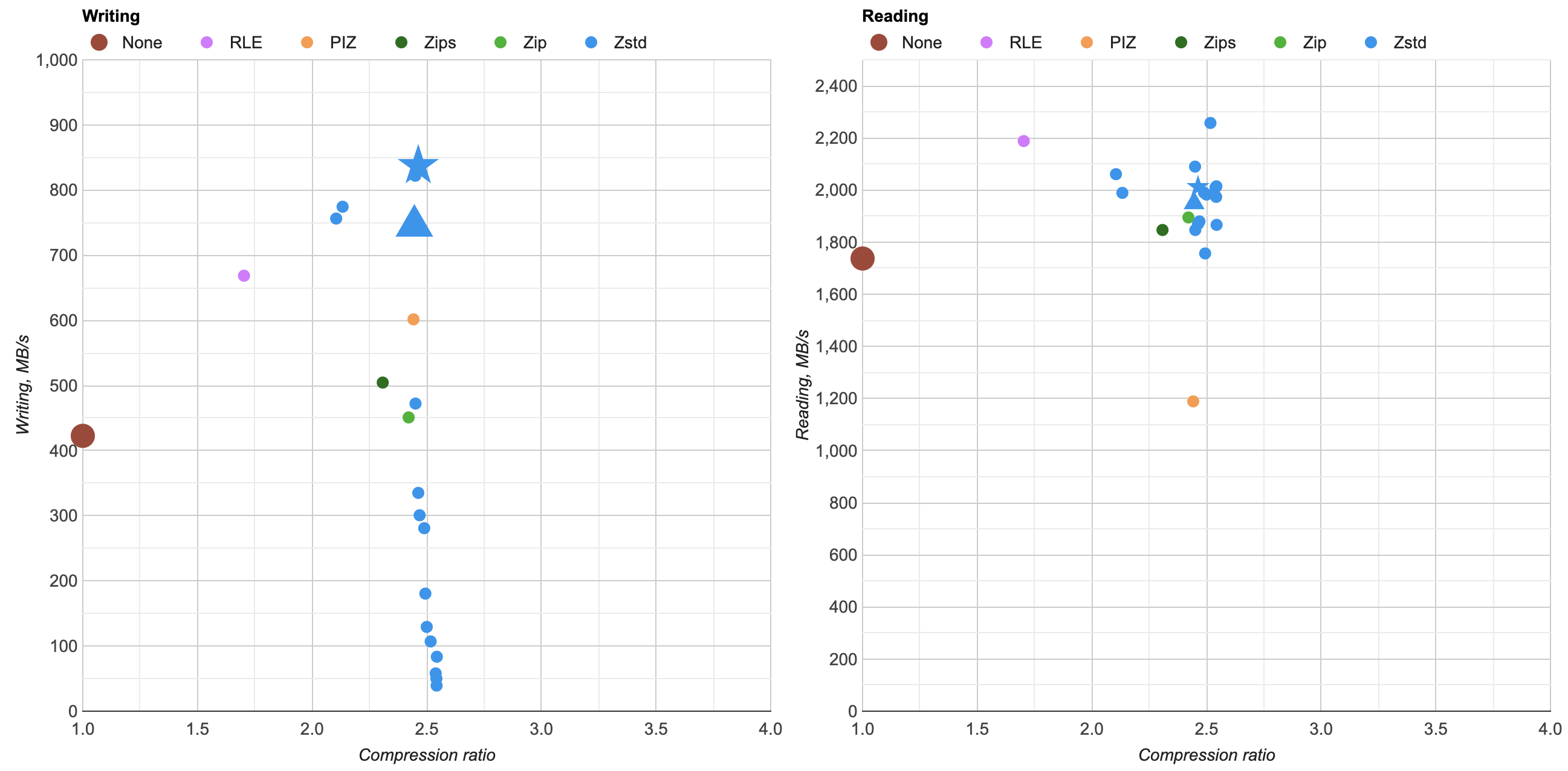
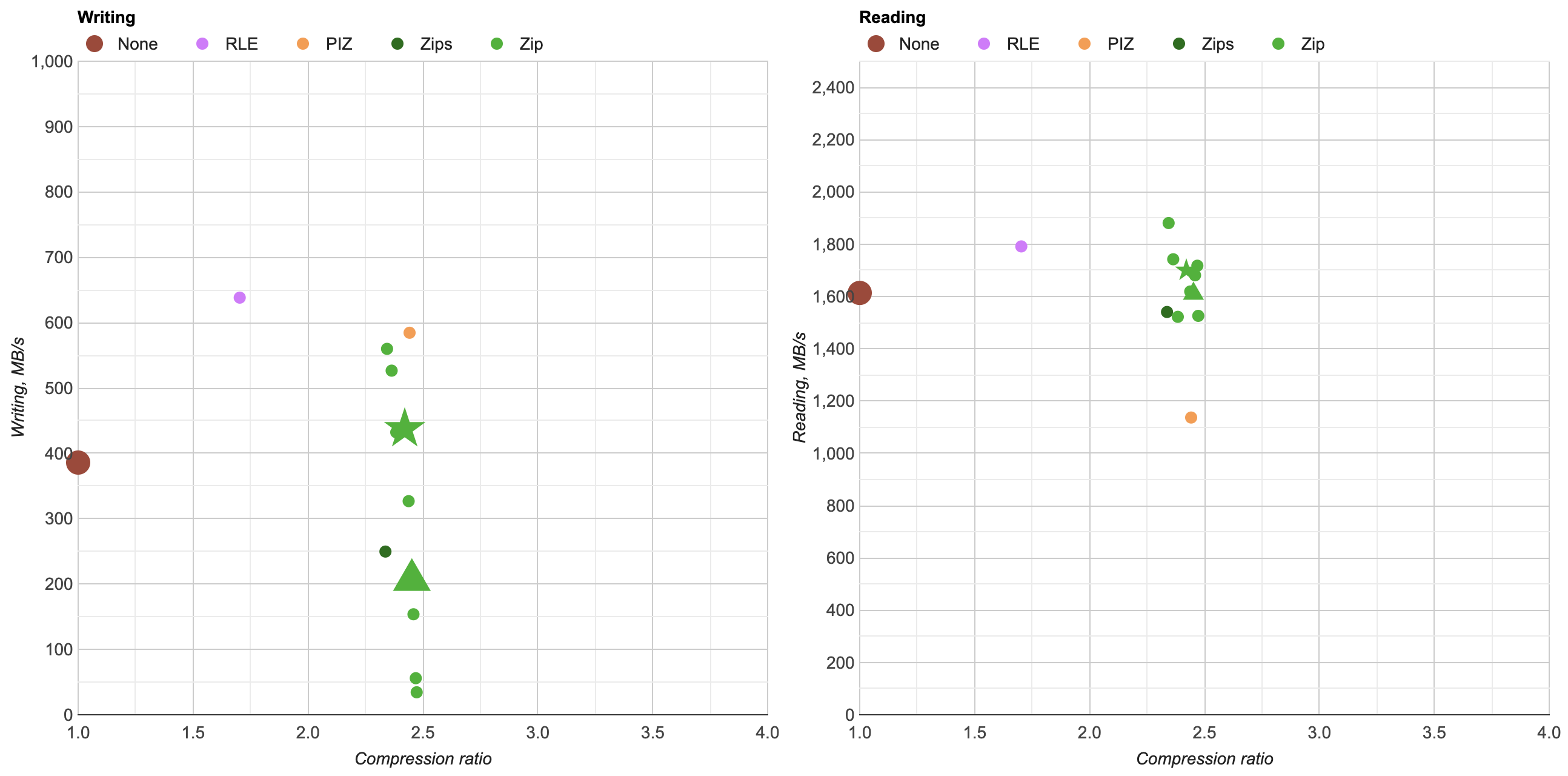
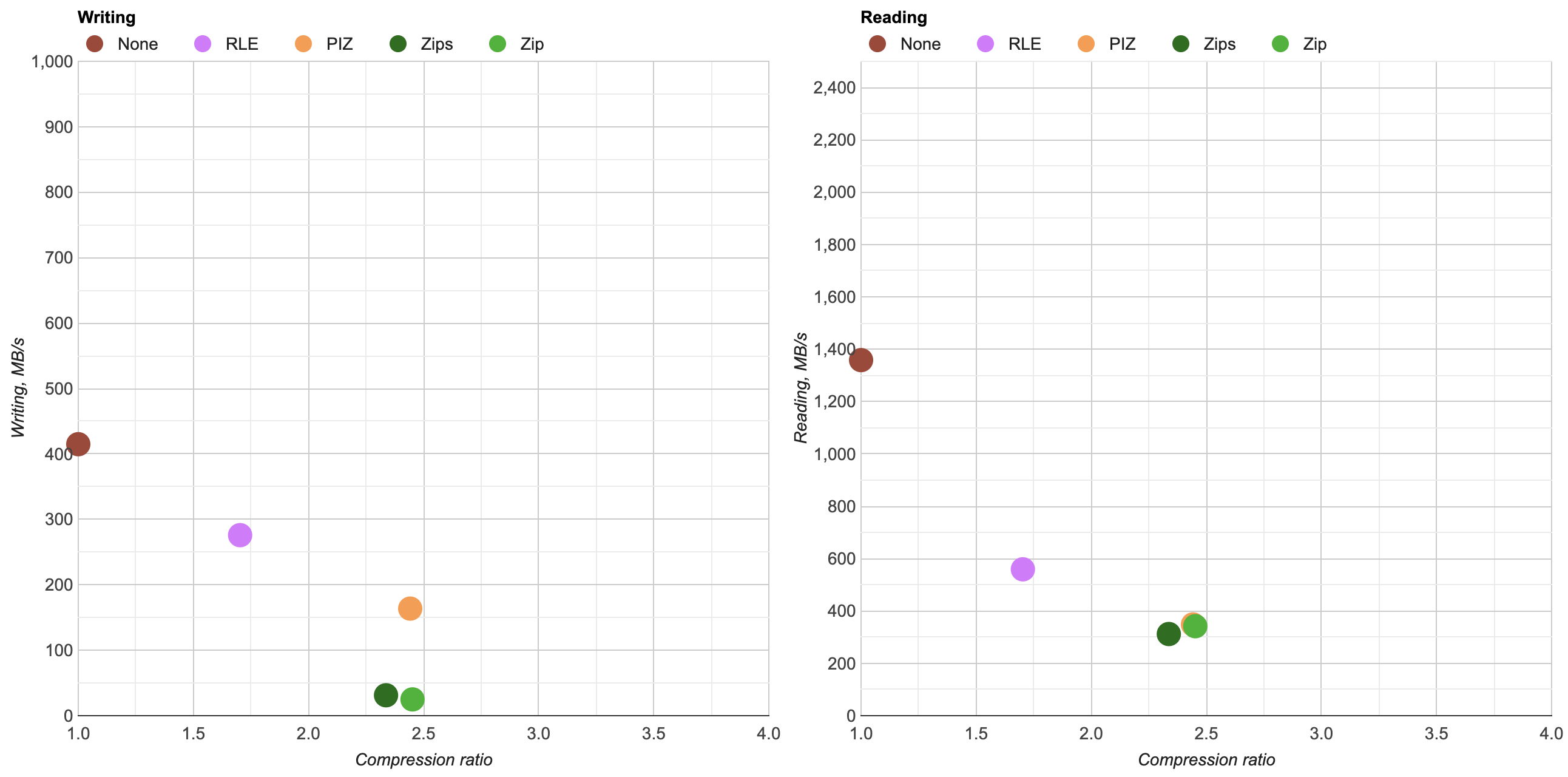
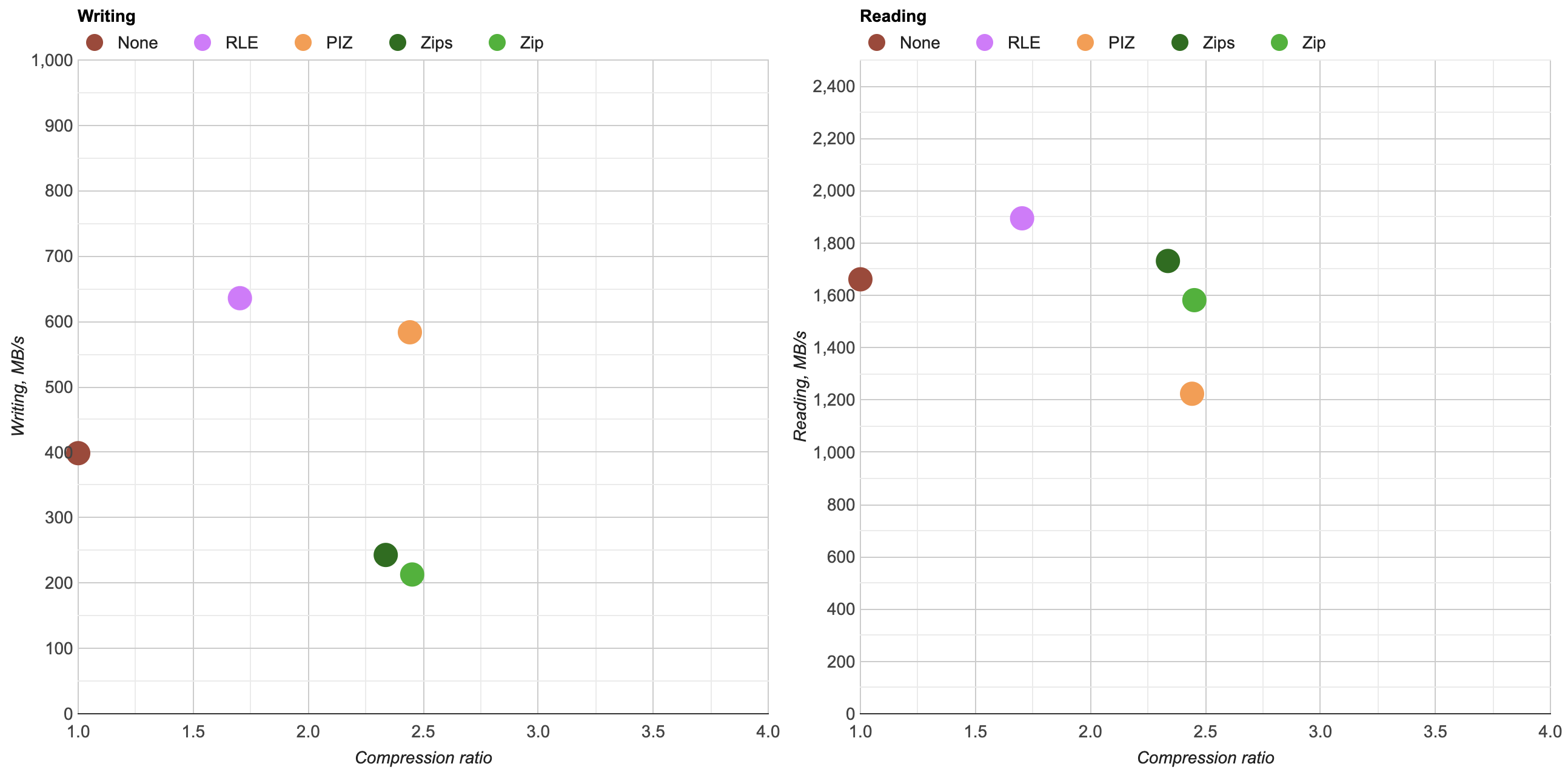
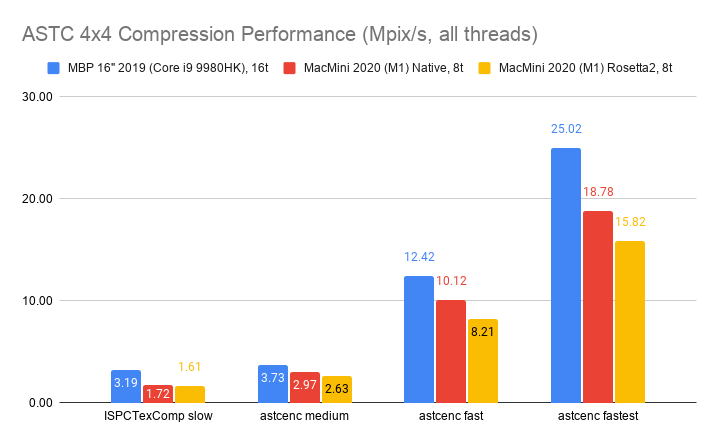
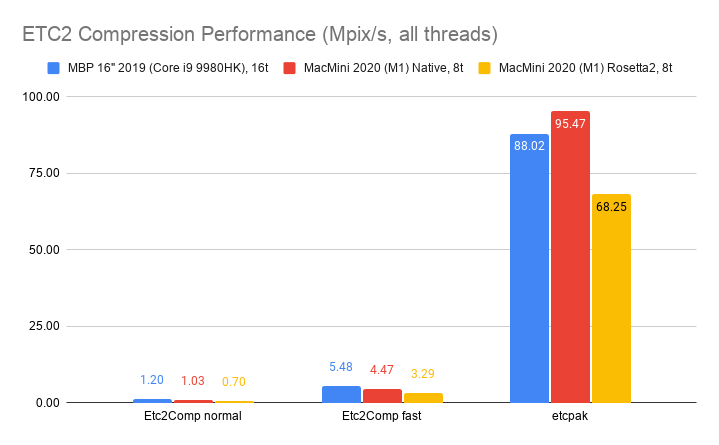
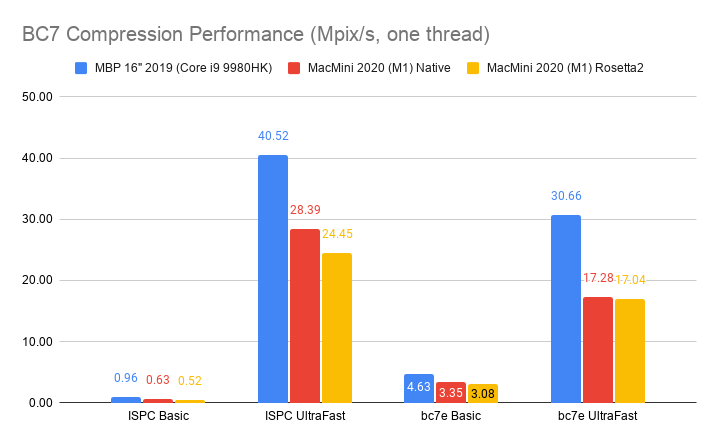
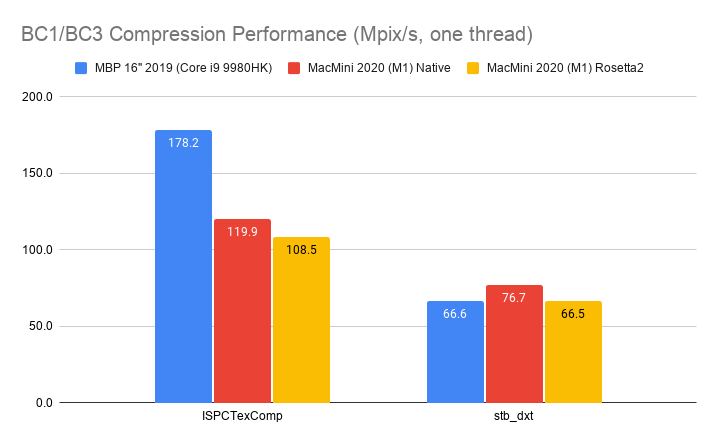
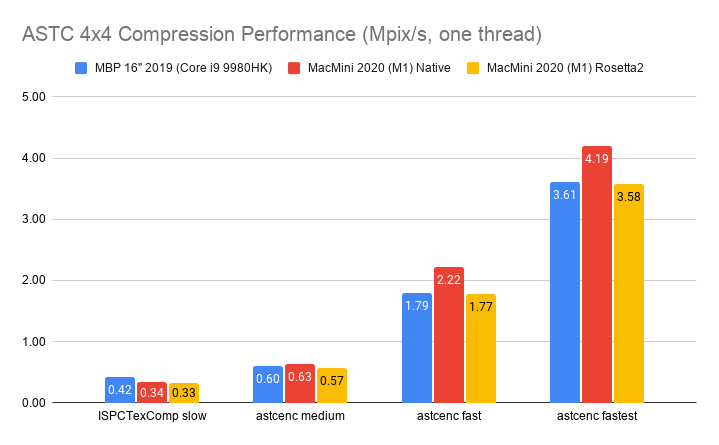
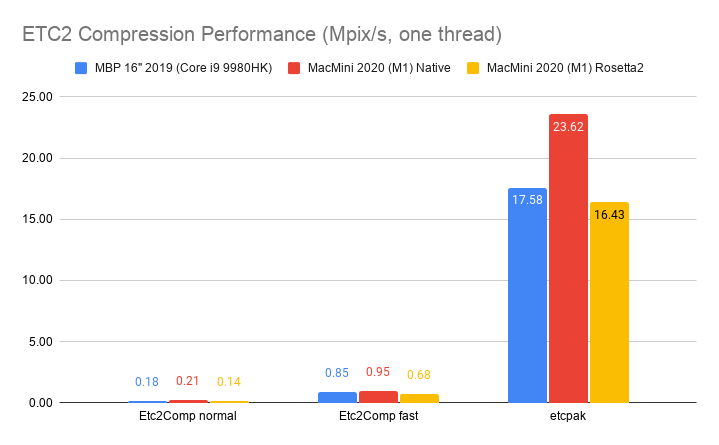
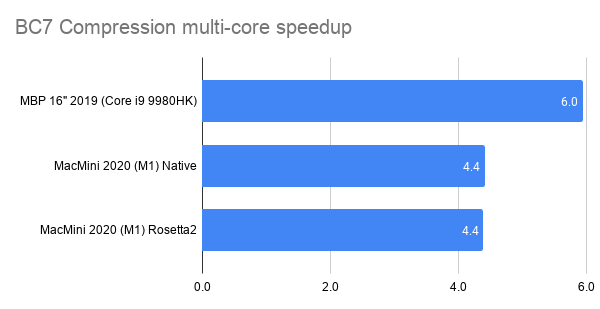
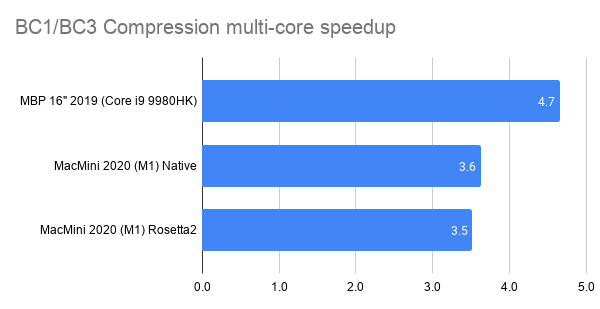
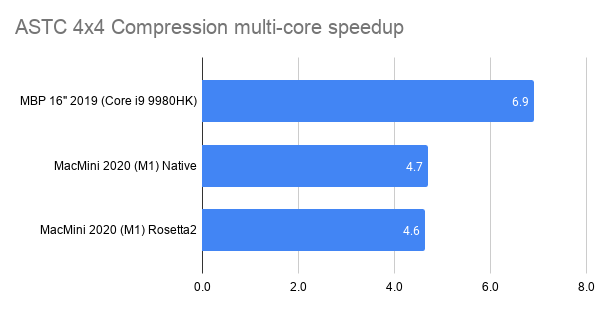
Here’s what happens by replacing zlib usage for Zip compression in OpenEXR with libdeflate v1.8 (click for a larger chart):
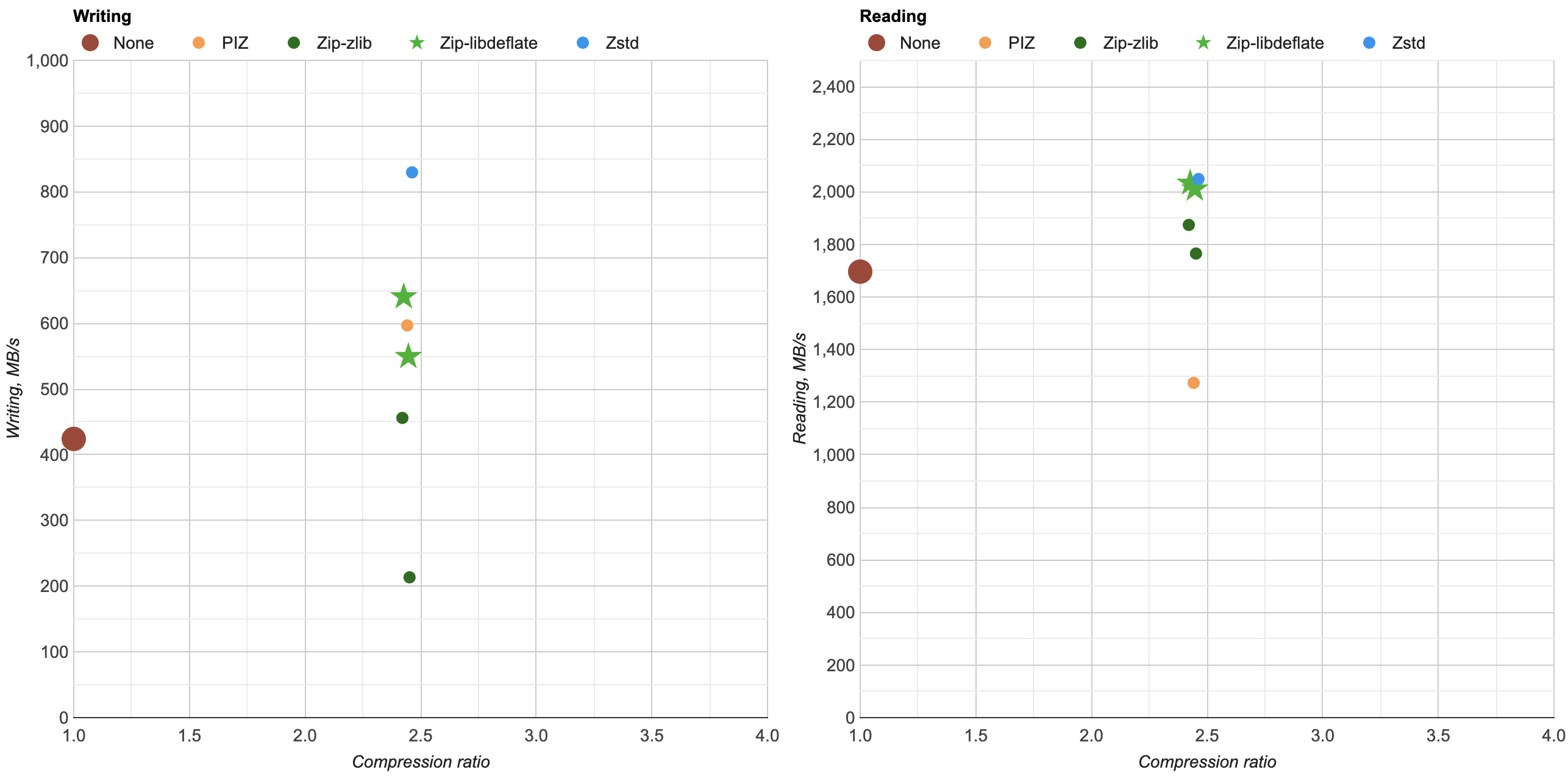
zlib is dark green (both the currently default compression level 6, and my proposed
level 4 are indicated). libdeflate is light green, star shape.
- Compression ratio is almost the same. Level 4: 2.421x for zlib, 2.427x for libdeflate; level 6: 2.452x for zlib, 2.447x for libdeflate.
- Writing: level 4 goes 456 -> 640 MB/s (1.4x faster), and level 6 goes 213 -> 549 MB/s (2.6x faster). Both are faster than writing uncompressed.
- Reading: with libdeflate reaches 2GB/s speed, and becomes same speed as Zstandard. I suspect this might be disk bandwidth bound at that point, since the numbers all look curiously similar.
So, changing zlib to libdeflate should be a no-brainer. Way faster, and a huge advantage is that the file format stays exactly the same; everything that could read or write EXR files in the past can still read/write them if libdeflate is used.
In compression performance, Zip+libdeflate does not quite reach Zstandard speeds though.
Another possible thing to watch out is security/bugs. zlib, being an extremely popular library, has been quite thoroughly battle-tested against bugs, crashes, handling of malformed or malicious data, etc. I don’t know if libdeflate got a similar treatment.
In terms of code, my quick hack is not even very optimal – I create a whole new libdeflate compressor/decompressor object for each compression
request. This could be optimized somehow if one were to switch to libdeflate for real, and maybe the numbers would be a tiny bit better.
All my change did was this in src/lib/OpenEXR/ImfZip.cpp:
// in Zip::compress:
//
// if (Z_OK != ::compress2 ((Bytef *)compressed, &outSize,
// (const Bytef *) _tmpBuffer, rawSize, level))
// {
// throw IEX_NAMESPACE::BaseExc ("Data compression (zlib) failed.");
// }
libdeflate_compressor* cmp = libdeflate_alloc_compressor(level);
size_t cmpBytes = libdeflate_zlib_compress(cmp, _tmpBuffer, rawSize, compressed, outSize);
libdeflate_free_compressor(cmp);
if (cmpBytes == 0)
{
throw IEX_NAMESPACE::BaseExc ("Data compression (libdeflate) failed.");
}
outSize = cmpBytes;
// in Zip::uncompress:
// if (Z_OK != ::uncompress ((Bytef *)_tmpBuffer, &outSize,
// (const Bytef *) compressed, compressedSize))
// {
// throw IEX_NAMESPACE::InputExc ("Data decompression (zlib) failed.");
// }
libdeflate_decompressor* cmp = libdeflate_alloc_decompressor();
size_t cmpBytes = 0;
libdeflate_result cmpRes = libdeflate_zlib_decompress(cmp, compressed, compressedSize, _tmpBuffer, _maxRawSize, &cmpBytes);
libdeflate_free_decompressor(cmp);
if (cmpRes != LIBDEFLATE_SUCCESS)
{
throw IEX_NAMESPACE::InputExc ("Data decompression (libdeflate) failed.");
}
outSize = cmpBytes;
Next up?
I want to look into more specialized compression schemes, besides just “let’s throw a general purpose compressor”. For example, ZFP.