2012 Theory for Forward Rendering
Good question in a tweet by @ivanassen:
So what is the 2012 theory on lights in a forward renderer?
Hard to answer that in 140 characters, so here goes raw brain dump (warning: not checked in practice!).
Short answer
A modern forward renderer for DX11-class hardware would probably be something like AMD’s Leo demo.
They seem to be doing light culling in a compute shader, and the result is per-pixel / tile linked lists of lights. Then scene is rendered normally in forward rendering, fetching the light lists and computing shading. Advantages are many; arbitrary shading models with many parameters that would be hard to store in a G-buffer; semitransparent objects; hardware MSAA support; much smaller memory requirements compared to some fat G-buffer layout.
Disadvantages would be storing linked lists, I guess. Potentially unbounded memory usage here, though I guess various schemes similar to Adaptive Transparency could be used to cap the maximum number of lights per pixel/tile.
Deferred == Caching
All the deferred lighting/shading approaches are essentially caching schemes. We cache some amount of surface information, in screen space, in order to avoid fetching or computing the same information over and over again, while applying lights one by one in traditional forward rendering.
Now, the “cache in screenspace” leads to disadvantages like “it’s really hard to do transparencies” - since with transparencies you do not have one point in space mapping to one pixel on screen anymore. There’s no reason why caching should be done in screen space however; lighting could also just as well be computed in texture space (like some skin rendering techniques, but they do it for a different reason), world space (voxels?), etc.
Does “modern” forward rendering still need caching?
 Caching information was important since in DX9 / Shader Model 3 times, it was hard to do forward rendering that could almost arbitrarily apply variable number of lights - with good efficiency - in one pass. That led to either shader combination explosion, or inefficient multipass rendering, or both. But now we have DX11, compute, structured buffers and unordered access views, so maybe we can actually do better?
Caching information was important since in DX9 / Shader Model 3 times, it was hard to do forward rendering that could almost arbitrarily apply variable number of lights - with good efficiency - in one pass. That led to either shader combination explosion, or inefficient multipass rendering, or both. But now we have DX11, compute, structured buffers and unordered access views, so maybe we can actually do better?
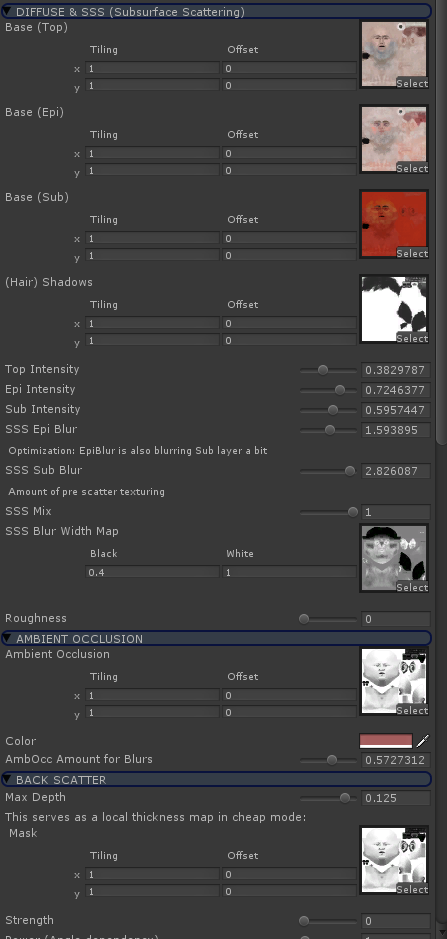
Because at some point we will want to have BRDFs with more parameters than it is viable to store in a G-buffer (side image: this is half of parameters for a material). We will want many semitransparent objects. And then we’re back to square one; we can not efficiently do this in a traditional “deferred” way where we cache N numbers per pixel.
AMD’s Leo goes in that direction. It seems to be a blend of tiled deferred approaches to light culling, applied to forward rendering.
I imagine it doing something like:
-
Z-prepass:
- Render Z prepass of opaque objects to fill in depth buffer.
- Store that away (copy into another depth buffer).
- Continue Z prepass of transparent objects; writing to depth.
- Now we have two Z buffers, and for any pixel we know the Z-extents of anything interesting in it (from closest transparent object up to closest opaque surface)
-
Shadowmaps, as usual. Would need to keep all shadowmaps for all lights in memory, which can be a problem!
-
Light culling, very similar to what you’d do in tiled deferred case!
- Have all lights stored in a buffer. Light types, positions/directions/ranges/angles, colors etc.
- From the two depth buffers above, we can compute Z ranges per pixel/tile in order to do better light culling.
- Run a compute shader that does light culling. Could do this per pixel or per small tiles (e.g. 8x8 ). Result is buffer(s) / lists per pixel or tile, with lights that affect said pixel or tile.
-
Render objects in forward rendering:
- Z-buffer is already pre-filled in 1.1.
- Each shader would have to do “apply all lights that affect this pixel/tile” computation. So that would involve fetching those arbitrary light informations, looping over lights etc.
- Otherwise, each object is free to use as many shader parameters as it wants, or use any BRDF it wants.
- Rendering order is like usual forward rendering; batch-friendly order (since Z is prefilled already) for opaque, per-object or per-triangle back-to-front order for semitransparent objects.
-
Profit!
Now, I have hand-waved over some potentially problematic details.
For example, “two depth buffers” is not robust for cases where there’s no opaque objects in some area; we’d need to track minimum and maximum depths of semitransparent stuff, or accept worse light culling for those tiles. Likewise, copying the depth buffer might lose some hardware Hi-Z information, so in practice it could be better to track semitransparent depths using another approach (min/max blending of a float texture etc.).
4.b. bit about “let’s apply all lights” assumes there is some way to do that efficiently, while supporting complicated things like each light having a different cookie/gobo texture, or a different shadowmap etc. Texture arrays could almost certainly be used here, but since this just a brain dump without verification in practice, it’s hard to say how would this work.
Update: other papers came out describing almost the same idea, with actual implementations & measurements. Check them out here!